labels = new ArrayList<>();
+ while ((text = bufferedReader.readLine()) != null) {
+ labels.add(text);
+ }
+ return labels;
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ return null;
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/layout/ActionBarLayout.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/layout/ActionBarLayout.java
new file mode 100644
index 0000000000000000000000000000000000000000..099219fa9f677134ae58d3e695d9389b54ce9597
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/layout/ActionBarLayout.java
@@ -0,0 +1,33 @@
+package com.baidu.paddle.fastdeploy.app.ui.layout;
+
+import android.content.Context;
+import android.graphics.Color;
+import android.support.annotation.Nullable;
+import android.util.AttributeSet;
+import android.widget.RelativeLayout;
+
+
+public class ActionBarLayout extends RelativeLayout {
+ private int layoutHeight = 150;
+
+ public ActionBarLayout(Context context) {
+ super(context);
+ }
+
+ public ActionBarLayout(Context context, @Nullable AttributeSet attrs) {
+ super(context, attrs);
+ }
+
+ public ActionBarLayout(Context context, @Nullable AttributeSet attrs, int defStyleAttr) {
+ super(context, attrs, defStyleAttr);
+ }
+
+ @Override
+ protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
+ super.onMeasure(widthMeasureSpec, heightMeasureSpec);
+ int width = MeasureSpec.getSize(widthMeasureSpec);
+ setMeasuredDimension(width, layoutHeight);
+ setBackgroundColor(Color.BLACK);
+ setAlpha(0.9f);
+ }
+}
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/AppCompatPreferenceActivity.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/AppCompatPreferenceActivity.java
new file mode 100644
index 0000000000000000000000000000000000000000..c1a952dcff6873593c0d5e75dc909d9b3177b3d0
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/AppCompatPreferenceActivity.java
@@ -0,0 +1,111 @@
+package com.baidu.paddle.fastdeploy.app.ui.view;
+
+import android.content.res.Configuration;
+import android.os.Bundle;
+import android.preference.PreferenceActivity;
+import android.support.annotation.LayoutRes;
+import android.support.annotation.Nullable;
+import android.support.v7.app.ActionBar;
+import android.support.v7.app.AppCompatDelegate;
+import android.support.v7.widget.Toolbar;
+import android.view.MenuInflater;
+import android.view.View;
+import android.view.ViewGroup;
+
+/**
+ * A {@link PreferenceActivity} which implements and proxies the necessary calls
+ * to be used with AppCompat.
+ *
+ * This technique can be used with an {@link android.app.Activity} class, not just
+ * {@link PreferenceActivity}.
+ */
+public abstract class AppCompatPreferenceActivity extends PreferenceActivity {
+ private AppCompatDelegate mDelegate;
+
+ @Override
+ protected void onCreate(Bundle savedInstanceState) {
+ getDelegate().installViewFactory();
+ getDelegate().onCreate(savedInstanceState);
+ super.onCreate(savedInstanceState);
+ }
+
+ @Override
+ protected void onPostCreate(Bundle savedInstanceState) {
+ super.onPostCreate(savedInstanceState);
+ getDelegate().onPostCreate(savedInstanceState);
+ }
+
+ public ActionBar getSupportActionBar() {
+ return getDelegate().getSupportActionBar();
+ }
+
+ public void setSupportActionBar(@Nullable Toolbar toolbar) {
+ getDelegate().setSupportActionBar(toolbar);
+ }
+
+ @Override
+ public MenuInflater getMenuInflater() {
+ return getDelegate().getMenuInflater();
+ }
+
+ @Override
+ public void setContentView(@LayoutRes int layoutResID) {
+ getDelegate().setContentView(layoutResID);
+ }
+
+ @Override
+ public void setContentView(View view) {
+ getDelegate().setContentView(view);
+ }
+
+ @Override
+ public void setContentView(View view, ViewGroup.LayoutParams params) {
+ getDelegate().setContentView(view, params);
+ }
+
+ @Override
+ public void addContentView(View view, ViewGroup.LayoutParams params) {
+ getDelegate().addContentView(view, params);
+ }
+
+ @Override
+ protected void onPostResume() {
+ super.onPostResume();
+ getDelegate().onPostResume();
+ }
+
+ @Override
+ protected void onTitleChanged(CharSequence title, int color) {
+ super.onTitleChanged(title, color);
+ getDelegate().setTitle(title);
+ }
+
+ @Override
+ public void onConfigurationChanged(Configuration newConfig) {
+ super.onConfigurationChanged(newConfig);
+ getDelegate().onConfigurationChanged(newConfig);
+ }
+
+ @Override
+ protected void onStop() {
+ super.onStop();
+ getDelegate().onStop();
+ }
+
+ @Override
+ protected void onDestroy() {
+ super.onDestroy();
+ getDelegate().onDestroy();
+ }
+
+ public void invalidateOptionsMenu() {
+ getDelegate().invalidateOptionsMenu();
+ }
+
+ private AppCompatDelegate getDelegate() {
+ if (mDelegate == null) {
+ mDelegate = AppCompatDelegate.create(this, null);
+ }
+ return mDelegate;
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/CameraSurfaceView.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/CameraSurfaceView.java
new file mode 100644
index 0000000000000000000000000000000000000000..e90874c627f671de2b7341334b92d872c7078bb6
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/CameraSurfaceView.java
@@ -0,0 +1,353 @@
+package com.baidu.paddle.fastdeploy.app.ui.view;
+
+import android.content.Context;
+import android.graphics.Bitmap;
+import android.graphics.SurfaceTexture;
+import android.hardware.Camera;
+import android.hardware.Camera.CameraInfo;
+import android.hardware.Camera.Size;
+import android.opengl.GLES11Ext;
+import android.opengl.GLES20;
+import android.opengl.GLSurfaceView;
+import android.opengl.GLSurfaceView.Renderer;
+import android.opengl.GLUtils;
+import android.opengl.Matrix;
+import android.os.SystemClock;
+import android.util.AttributeSet;
+import android.util.Log;
+
+import com.baidu.paddle.fastdeploy.app.ui.Utils;
+
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.nio.ByteOrder;
+import java.nio.FloatBuffer;
+import java.util.List;
+
+import javax.microedition.khronos.egl.EGLConfig;
+import javax.microedition.khronos.opengles.GL10;
+
+public class CameraSurfaceView extends GLSurfaceView implements Renderer,
+ SurfaceTexture.OnFrameAvailableListener {
+ private static final String TAG = CameraSurfaceView.class.getSimpleName();
+
+ public static int EXPECTED_PREVIEW_WIDTH = 1280; // 1920
+ public static int EXPECTED_PREVIEW_HEIGHT = 720; // 960
+
+ protected int numberOfCameras;
+ protected int selectedCameraId;
+ protected boolean disableCamera = false;
+ protected Camera camera;
+
+ protected Context context;
+ protected SurfaceTexture surfaceTexture;
+ protected int surfaceWidth = 0;
+ protected int surfaceHeight = 0;
+ protected int textureWidth = 0;
+ protected int textureHeight = 0;
+
+ protected Bitmap ARGB8888ImageBitmap;
+ protected boolean bitmapReleaseMode = true;
+
+ // In order to manipulate the camera preview data and render the modified one
+ // to the screen, three textures are created and the data flow is shown as following:
+ // previewdata->camTextureId->fboTexureId->drawTexureId->framebuffer
+ protected int[] fbo = {0};
+ protected int[] camTextureId = {0};
+ protected int[] fboTexureId = {0};
+ protected int[] drawTexureId = {0};
+
+ private final String vss = ""
+ + "attribute vec2 vPosition;\n"
+ + "attribute vec2 vTexCoord;\n" + "varying vec2 texCoord;\n"
+ + "void main() {\n" + " texCoord = vTexCoord;\n"
+ + " gl_Position = vec4 (vPosition.x, vPosition.y, 0.0, 1.0);\n"
+ + "}";
+
+ private final String fssCam2FBO = ""
+ + "#extension GL_OES_EGL_image_external : require\n"
+ + "precision mediump float;\n"
+ + "uniform samplerExternalOES sTexture;\n"
+ + "varying vec2 texCoord;\n"
+ + "void main() {\n"
+ + " gl_FragColor = texture2D(sTexture,texCoord);\n" + "}";
+
+ private final String fssTex2Screen = ""
+ + "precision mediump float;\n"
+ + "uniform sampler2D sTexture;\n"
+ + "varying vec2 texCoord;\n"
+ + "void main() {\n"
+ + " gl_FragColor = texture2D(sTexture,texCoord);\n" + "}";
+
+ private final float[] vertexCoords = {
+ -1, -1,
+ -1, 1,
+ 1, -1,
+ 1, 1};
+ private float[] textureCoords = {
+ 0, 1,
+ 0, 0,
+ 1, 1,
+ 1, 0};
+
+ private FloatBuffer vertexCoordsBuffer;
+ private FloatBuffer textureCoordsBuffer;
+
+ private int progCam2FBO = -1;
+ private int progTex2Screen = -1;
+ private int vcCam2FBO;
+ private int tcCam2FBO;
+ private int vcTex2Screen;
+ private int tcTex2Screen;
+
+ public void setBitmapReleaseMode(boolean mode) {
+ synchronized (this) {
+ bitmapReleaseMode = mode;
+ }
+ }
+
+ public Bitmap getBitmap() {
+ return ARGB8888ImageBitmap; // may null or recycled.
+ }
+
+ public interface OnTextureChangedListener {
+ boolean onTextureChanged(Bitmap ARGB8888ImageBitmap);
+ }
+
+ private OnTextureChangedListener onTextureChangedListener = null;
+
+ public void setOnTextureChangedListener(OnTextureChangedListener listener) {
+ onTextureChangedListener = listener;
+ }
+
+ public CameraSurfaceView(Context ctx, AttributeSet attrs) {
+ super(ctx, attrs);
+ context = ctx;
+ setEGLContextClientVersion(2);
+ setRenderer(this);
+ setRenderMode(RENDERMODE_WHEN_DIRTY);
+
+ // Find the total number of available cameras and the ID of the default camera
+ numberOfCameras = Camera.getNumberOfCameras();
+ CameraInfo cameraInfo = new CameraInfo();
+ for (int i = 0; i < numberOfCameras; i++) {
+ Camera.getCameraInfo(i, cameraInfo);
+ if (cameraInfo.facing == CameraInfo.CAMERA_FACING_BACK) {
+ selectedCameraId = i;
+ }
+ }
+ }
+
+ @Override
+ public void onSurfaceCreated(GL10 gl, EGLConfig config) {
+ // Create OES texture for storing camera preview data(YUV format)
+ GLES20.glGenTextures(1, camTextureId, 0);
+ GLES20.glBindTexture(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, camTextureId[0]);
+ GLES20.glTexParameteri(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, GLES20.GL_TEXTURE_WRAP_S, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, GLES20.GL_TEXTURE_WRAP_T, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, GLES20.GL_TEXTURE_MIN_FILTER, GLES20.GL_NEAREST);
+ GLES20.glTexParameteri(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, GLES20.GL_TEXTURE_MAG_FILTER, GLES20.GL_NEAREST);
+ surfaceTexture = new SurfaceTexture(camTextureId[0]);
+ surfaceTexture.setOnFrameAvailableListener(this);
+
+ // Prepare vertex and texture coordinates
+ int bytes = vertexCoords.length * Float.SIZE / Byte.SIZE;
+ vertexCoordsBuffer = ByteBuffer.allocateDirect(bytes).order(ByteOrder.nativeOrder()).asFloatBuffer();
+ textureCoordsBuffer = ByteBuffer.allocateDirect(bytes).order(ByteOrder.nativeOrder()).asFloatBuffer();
+ vertexCoordsBuffer.put(vertexCoords).position(0);
+ textureCoordsBuffer.put(textureCoords).position(0);
+
+ // Create vertex and fragment shaders
+ // camTextureId->fboTexureId
+ progCam2FBO = Utils.createShaderProgram(vss, fssCam2FBO);
+ vcCam2FBO = GLES20.glGetAttribLocation(progCam2FBO, "vPosition");
+ tcCam2FBO = GLES20.glGetAttribLocation(progCam2FBO, "vTexCoord");
+ GLES20.glEnableVertexAttribArray(vcCam2FBO);
+ GLES20.glEnableVertexAttribArray(tcCam2FBO);
+ // fboTexureId/drawTexureId -> screen
+ progTex2Screen = Utils.createShaderProgram(vss, fssTex2Screen);
+ vcTex2Screen = GLES20.glGetAttribLocation(progTex2Screen, "vPosition");
+ tcTex2Screen = GLES20.glGetAttribLocation(progTex2Screen, "vTexCoord");
+ GLES20.glEnableVertexAttribArray(vcTex2Screen);
+ GLES20.glEnableVertexAttribArray(tcTex2Screen);
+ }
+
+ @Override
+ public void onSurfaceChanged(GL10 gl, int width, int height) {
+ surfaceWidth = width;
+ surfaceHeight = height;
+ openCamera();
+ }
+
+ @Override
+ public void onDrawFrame(GL10 gl) {
+ if (surfaceTexture == null) return;
+
+ GLES20.glClearColor(0.0f, 0.0f, 0.0f, 1.0f);
+ GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT | GLES20.GL_DEPTH_BUFFER_BIT);
+ surfaceTexture.updateTexImage();
+ float[] matrix = new float[16];
+ surfaceTexture.getTransformMatrix(matrix);
+
+ // camTextureId->fboTexureId
+ GLES20.glBindFramebuffer(GLES20.GL_FRAMEBUFFER, fbo[0]);
+ GLES20.glViewport(0, 0, textureWidth, textureHeight);
+ GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT);
+ GLES20.glUseProgram(progCam2FBO);
+ GLES20.glVertexAttribPointer(vcCam2FBO, 2, GLES20.GL_FLOAT, false, 4 * 2, vertexCoordsBuffer);
+ textureCoordsBuffer.clear();
+ textureCoordsBuffer.put(transformTextureCoordinates(textureCoords, matrix));
+ textureCoordsBuffer.position(0);
+ GLES20.glVertexAttribPointer(tcCam2FBO, 2, GLES20.GL_FLOAT, false, 4 * 2, textureCoordsBuffer);
+ GLES20.glActiveTexture(GLES20.GL_TEXTURE0);
+ GLES20.glBindTexture(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, camTextureId[0]);
+ GLES20.glUniform1i(GLES20.glGetUniformLocation(progCam2FBO, "sTexture"), 0);
+ GLES20.glDrawArrays(GLES20.GL_TRIANGLE_STRIP, 0, 4);
+ GLES20.glFlush();
+
+ // Check if the draw texture is set
+ int targetTexureId = fboTexureId[0];
+ if (onTextureChangedListener != null) {
+ // Read pixels of FBO to a bitmap
+ ByteBuffer pixelBuffer = ByteBuffer.allocate(textureWidth * textureHeight * 4);
+ GLES20.glReadPixels(0, 0, textureWidth, textureHeight, GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, pixelBuffer);
+
+ ARGB8888ImageBitmap = Bitmap.createBitmap(textureWidth, textureHeight, Bitmap.Config.ARGB_8888);
+ ARGB8888ImageBitmap.copyPixelsFromBuffer(pixelBuffer);
+
+ boolean modified = onTextureChangedListener.onTextureChanged(ARGB8888ImageBitmap);
+
+ if (modified) {
+ targetTexureId = drawTexureId[0];
+ // Update a bitmap to the GL texture if modified
+ GLES20.glActiveTexture(targetTexureId);
+ // GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, targetTexureId);
+ GLES20.glBindTexture(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, targetTexureId);
+ GLUtils.texImage2D(GL10.GL_TEXTURE_2D, 0, ARGB8888ImageBitmap, 0);
+ }
+ if (bitmapReleaseMode) {
+ ARGB8888ImageBitmap.recycle();
+ }
+ }
+
+ // fboTexureId/drawTexureId->Screen
+ GLES20.glBindFramebuffer(GLES20.GL_FRAMEBUFFER, 0);
+ GLES20.glViewport(0, 0, surfaceWidth, surfaceHeight);
+ GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT);
+ GLES20.glUseProgram(progTex2Screen);
+ GLES20.glVertexAttribPointer(vcTex2Screen, 2, GLES20.GL_FLOAT, false, 4 * 2, vertexCoordsBuffer);
+ textureCoordsBuffer.clear();
+ textureCoordsBuffer.put(textureCoords);
+ textureCoordsBuffer.position(0);
+ GLES20.glVertexAttribPointer(tcTex2Screen, 2, GLES20.GL_FLOAT, false, 4 * 2, textureCoordsBuffer);
+ GLES20.glActiveTexture(GLES20.GL_TEXTURE0);
+ GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, targetTexureId);
+ GLES20.glUniform1i(GLES20.glGetUniformLocation(progTex2Screen, "sTexture"), 0);
+ GLES20.glDrawArrays(GLES20.GL_TRIANGLE_STRIP, 0, 4);
+ GLES20.glFlush();
+ }
+
+ private float[] transformTextureCoordinates(float[] coords, float[] matrix) {
+ float[] result = new float[coords.length];
+ float[] vt = new float[4];
+ for (int i = 0; i < coords.length; i += 2) {
+ float[] v = {coords[i], coords[i + 1], 0, 1};
+ Matrix.multiplyMV(vt, 0, matrix, 0, v, 0);
+ result[i] = vt[0];
+ result[i + 1] = vt[1];
+ }
+ return result;
+ }
+
+ @Override
+ public void onResume() {
+ super.onResume();
+ }
+
+ @Override
+ public void onPause() {
+ super.onPause();
+ releaseCamera();
+ }
+
+ @Override
+ public void onFrameAvailable(SurfaceTexture surfaceTexture) {
+ requestRender();
+ }
+
+ public void disableCamera() {
+ disableCamera = true;
+ }
+
+ public void enableCamera() {
+ disableCamera = false;
+ }
+
+ public void switchCamera() {
+ releaseCamera();
+ selectedCameraId = (selectedCameraId + 1) % numberOfCameras;
+ openCamera();
+ }
+
+ public void openCamera() {
+ if (disableCamera) return;
+ camera = Camera.open(selectedCameraId);
+ List supportedPreviewSizes = camera.getParameters().getSupportedPreviewSizes();
+ Size previewSize = Utils.getOptimalPreviewSize(supportedPreviewSizes, EXPECTED_PREVIEW_WIDTH,
+ EXPECTED_PREVIEW_HEIGHT);
+ Camera.Parameters parameters = camera.getParameters();
+ parameters.setPreviewSize(previewSize.width, previewSize.height);
+ if (parameters.getSupportedFocusModes().contains(Camera.Parameters.FOCUS_MODE_CONTINUOUS_VIDEO)) {
+ parameters.setFocusMode(Camera.Parameters.FOCUS_MODE_CONTINUOUS_VIDEO);
+ }
+ camera.setParameters(parameters);
+ int degree = Utils.getCameraDisplayOrientation(context, selectedCameraId);
+ camera.setDisplayOrientation(degree);
+ boolean rotate = degree == 90 || degree == 270;
+ textureWidth = rotate ? previewSize.height : previewSize.width;
+ textureHeight = rotate ? previewSize.width : previewSize.height;
+ // Destroy FBO and draw textures
+ GLES20.glBindFramebuffer(GLES20.GL_FRAMEBUFFER, 0);
+ GLES20.glDeleteFramebuffers(1, fbo, 0);
+ GLES20.glDeleteTextures(1, drawTexureId, 0);
+ GLES20.glDeleteTextures(1, fboTexureId, 0);
+ // Normal texture for storing modified camera preview data(RGBA format)
+ GLES20.glGenTextures(1, drawTexureId, 0);
+ GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, drawTexureId[0]);
+ GLES20.glTexImage2D(GLES20.GL_TEXTURE_2D, 0, GLES20.GL_RGBA, textureWidth, textureHeight, 0,
+ GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, null);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_S, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_T, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MIN_FILTER, GLES20.GL_NEAREST);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MAG_FILTER, GLES20.GL_NEAREST);
+ // FBO texture for storing camera preview data(RGBA format)
+ GLES20.glGenTextures(1, fboTexureId, 0);
+ GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, fboTexureId[0]);
+ GLES20.glTexImage2D(GLES20.GL_TEXTURE_2D, 0, GLES20.GL_RGBA, textureWidth, textureHeight, 0,
+ GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, null);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_S, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_T, GLES20.GL_CLAMP_TO_EDGE);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MIN_FILTER, GLES20.GL_NEAREST);
+ GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MAG_FILTER, GLES20.GL_NEAREST);
+ // Generate FBO and bind to FBO texture
+ GLES20.glGenFramebuffers(1, fbo, 0);
+ GLES20.glBindFramebuffer(GLES20.GL_FRAMEBUFFER, fbo[0]);
+ GLES20.glFramebufferTexture2D(GLES20.GL_FRAMEBUFFER, GLES20.GL_COLOR_ATTACHMENT0, GLES20.GL_TEXTURE_2D,
+ fboTexureId[0], 0);
+ try {
+ camera.setPreviewTexture(surfaceTexture);
+ } catch (IOException exception) {
+ Log.e(TAG, "IOException caused by setPreviewDisplay()", exception);
+ }
+ camera.startPreview();
+ }
+
+ public void releaseCamera() {
+ if (camera != null) {
+ camera.setPreviewCallback(null);
+ camera.stopPreview();
+ camera.release();
+ camera = null;
+ }
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/ResultListView.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/ResultListView.java
new file mode 100644
index 0000000000000000000000000000000000000000..62b48a0547dca5c1dd80440918bb813811f35844
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/ResultListView.java
@@ -0,0 +1,43 @@
+package com.baidu.paddle.fastdeploy.app.ui.view;
+
+import android.content.Context;
+import android.os.Handler;
+import android.util.AttributeSet;
+import android.widget.ListView;
+
+public class ResultListView extends ListView {
+ public ResultListView(Context context) {
+ super(context);
+ }
+
+ public ResultListView(Context context, AttributeSet attrs) {
+ super(context, attrs);
+ }
+
+ public ResultListView(Context context, AttributeSet attrs, int defStyleAttr) {
+ super(context, attrs, defStyleAttr);
+ }
+
+ private Handler handler;
+
+ public void setHandler(Handler mHandler) {
+ handler = mHandler;
+ }
+
+ public void clear() {
+ handler.post(new Runnable() {
+ @Override
+ public void run() {
+ removeAllViewsInLayout();
+ invalidate();
+ }
+ });
+ }
+
+ @Override
+ protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
+ int expandSpec = MeasureSpec.makeMeasureSpec(Integer.MAX_VALUE >> 2,
+ MeasureSpec.AT_MOST);
+ super.onMeasure(widthMeasureSpec, expandSpec);
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/adapter/BaseResultAdapter.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/adapter/BaseResultAdapter.java
new file mode 100644
index 0000000000000000000000000000000000000000..62747965adc25714bd35fa254c6fce1e6009fa0e
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/adapter/BaseResultAdapter.java
@@ -0,0 +1,48 @@
+package com.baidu.paddle.fastdeploy.app.ui.view.adapter;
+
+import android.content.Context;
+import android.support.annotation.NonNull;
+import android.support.annotation.Nullable;
+import android.view.LayoutInflater;
+import android.view.View;
+import android.view.ViewGroup;
+import android.widget.ArrayAdapter;
+import android.widget.TextView;
+
+import com.baidu.paddle.fastdeploy.app.examples.R;
+import com.baidu.paddle.fastdeploy.app.ui.view.model.BaseResultModel;
+
+import java.text.DecimalFormat;
+import java.util.List;
+
+public class BaseResultAdapter extends ArrayAdapter {
+ private int resourceId;
+
+ public BaseResultAdapter(@NonNull Context context, int resource) {
+ super(context, resource);
+ }
+
+ public BaseResultAdapter(@NonNull Context context, int resource, @NonNull List objects) {
+ super(context, resource, objects);
+ resourceId = resource;
+ }
+
+ @NonNull
+ @Override
+ public View getView(int position, @Nullable View convertView, @NonNull ViewGroup parent) {
+ BaseResultModel model = getItem(position);
+ View view = LayoutInflater.from(getContext()).inflate(resourceId, null);
+ TextView indexText = (TextView) view.findViewById(R.id.index);
+ TextView nameText = (TextView) view.findViewById(R.id.name);
+ TextView confidenceText = (TextView) view.findViewById(R.id.confidence);
+ indexText.setText(String.valueOf(model.getIndex()));
+ nameText.setText(String.valueOf(model.getName()));
+ confidenceText.setText(formatFloatString(model.getConfidence()));
+ return view;
+ }
+
+ public static String formatFloatString(float number) {
+ DecimalFormat df = new DecimalFormat("0.00");
+ return df.format(number);
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/model/BaseResultModel.java b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/model/BaseResultModel.java
new file mode 100644
index 0000000000000000000000000000000000000000..cae71b6909db125894a2ce0da8ac3485dd48619f
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/java/com/baidu/paddle/fastdeploy/app/ui/view/model/BaseResultModel.java
@@ -0,0 +1,41 @@
+package com.baidu.paddle.fastdeploy.app.ui.view.model;
+
+public class BaseResultModel {
+ private int index;
+ private String name;
+ private float confidence;
+
+ public BaseResultModel() {
+
+ }
+
+ public BaseResultModel(int index, String name, float confidence) {
+ this.index = index;
+ this.name = name;
+ this.confidence = confidence;
+ }
+
+ public float getConfidence() {
+ return confidence;
+ }
+
+ public void setConfidence(float confidence) {
+ this.confidence = confidence;
+ }
+
+ public int getIndex() {
+ return index;
+ }
+
+ public void setIndex(int index) {
+ this.index = index;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+}
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/action_button_layer.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/action_button_layer.xml
new file mode 100644
index 0000000000000000000000000000000000000000..a0d2e76bfa39dc7faa6cca58132ea6c0691c3f15
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/action_button_layer.xml
@@ -0,0 +1,14 @@
+
+
+ -
+
+
+
+
+
+ -
+
+
+
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/album_btn.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/album_btn.xml
new file mode 100644
index 0000000000000000000000000000000000000000..26d01c584185231af27b424b26de8b957a8f5c28
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/album_btn.xml
@@ -0,0 +1,7 @@
+
+
+ -
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/round_corner_btn.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/round_corner_btn.xml
new file mode 100644
index 0000000000000000000000000000000000000000..c5dcc45d56375ae8bfad057aea837a1d34c6aac2
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/round_corner_btn.xml
@@ -0,0 +1,10 @@
+
+
+
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_realtime.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_realtime.xml
new file mode 100644
index 0000000000000000000000000000000000000000..b349d15a6aa37105a7ce2a1d09db4490ff715341
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_realtime.xml
@@ -0,0 +1,18 @@
+
+
+
+
+ -
+
+
+
+ -
+
+
+
+
+
+
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_result.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_result.xml
new file mode 100644
index 0000000000000000000000000000000000000000..17cb68ed80ccb203d76c20bf6be25cf3408f7a22
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_progress_result.xml
@@ -0,0 +1,18 @@
+
+
+
+
+ -
+
+
+
+
+
+ -
+
+
+
+
+
+
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_thumb.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_thumb.xml
new file mode 100644
index 0000000000000000000000000000000000000000..96bd95e0a1736f5eb1bf574c041fd631a888f2b4
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/seekbar_thumb.xml
@@ -0,0 +1,9 @@
+
+
+
+ -
+
+
+
+
+
+
+ -
+
+
+
+
+
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/drawable-v24/switch_side_btn.xml b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/switch_side_btn.xml
new file mode 100644
index 0000000000000000000000000000000000000000..b9b2edfb6a55a246302cbf7b67e6a8110ceebe54
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/drawable-v24/switch_side_btn.xml
@@ -0,0 +1,7 @@
+
+
+ - 1 threads
+ - 2 threads
+ - 4 threads
+ - 8 threads
+
+
+ - 1
+ - 2
+ - 4
+ - 8
+
+
+ - HIGH(only big cores)
+ - LOW(only LITTLE cores)
+ - FULL(all cores)
+ - NO_BIND(depends on system)
+ - RAND_HIGH
+ - RAND_LOW
+
+
+ - LITE_POWER_HIGH
+ - LITE_POWER_LOW
+ - LITE_POWER_FULL
+ - LITE_POWER_NO_BIND
+ - LITE_POWER_RAND_HIGH
+ - LITE_POWER_RAND_LOW
+
+
+ - true
+ - false
+
+
+ - true
+ - false
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/res/values/colors.xml b/deploy/fastdeploy/android/app/src/main/res/values/colors.xml
new file mode 100644
index 0000000000000000000000000000000000000000..f8ec1f0c3bca8b1b8cf4a82334fdd6ab18f35862
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/values/colors.xml
@@ -0,0 +1,22 @@
+
+
+ #008577
+ #00574B
+ #D81B60
+ #FF000000
+ #00000000
+ #00000000
+ #FFFFFFFF
+
+ #000000
+ #3B85F5
+ #F5A623
+ #FFFFFF
+
+ #EEEEEE
+
+ #3B85F5
+ #333333
+ #E5E5E5
+ #3b85f5
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/values/dimens.xml b/deploy/fastdeploy/android/app/src/main/res/values/dimens.xml
new file mode 100644
index 0000000000000000000000000000000000000000..2df89499da7090787effe0b811af18a2612b0f4c
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/values/dimens.xml
@@ -0,0 +1,17 @@
+
+
+ 26dp
+ 36dp
+ 34dp
+ 60dp
+ 16dp
+ 67dp
+ 67dp
+ 56dp
+ 56dp
+ 46dp
+ 46dp
+ 32dp
+ 24dp
+ 16dp
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/values/strings.xml b/deploy/fastdeploy/android/app/src/main/res/values/strings.xml
new file mode 100644
index 0000000000000000000000000000000000000000..b5c396f5f781f3eee74272953c95bf7fd78ae369
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/values/strings.xml
@@ -0,0 +1,51 @@
+
+
+ EasyEdge
+
+ EasyEdge
+ EasyEdge
+ EasyEdge
+ EasyEdge
+ EasyEdge
+
+ CHOOSE_INSTALLED_MODEL_KEY
+ MODEL_DIR_KEY
+ LABEL_PATH_KEY
+ CPU_THREAD_NUM_KEY
+ CPU_POWER_MODE_KEY
+ SCORE_THRESHOLD_KEY
+ ENABLE_LITE_FP16_MODE_KEY
+
+ 2
+ LITE_POWER_HIGH
+ 0.4
+ 0.1
+ 0.25
+ true
+
+
+ models/picodet_s_320_coco_lcnet
+ labels/coco_label_list.txt
+
+ models
+ labels/ppocr_keys_v1.txt
+
+ models/MobileNetV1_x0_25_infer
+ labels/imagenet1k_label_list.txt
+
+ models/scrfd_500m_bnkps_shape320x320_pd
+
+ models/human_pp_humansegv1_lite_192x192_inference_model
+
+ 拍照识别
+ 实时识别
+ <
+ 模型名称
+ 识别结果
+ 序号
+ 名称
+ 置信度
+ 阈值控制
+ 重新识别
+ 保存结果
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/values/styles.xml b/deploy/fastdeploy/android/app/src/main/res/values/styles.xml
new file mode 100644
index 0000000000000000000000000000000000000000..67c147594487ee33165cb1c13d0cc8bc332671a9
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/values/styles.xml
@@ -0,0 +1,70 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/deploy/fastdeploy/android/app/src/main/res/values/values.xml b/deploy/fastdeploy/android/app/src/main/res/values/values.xml
new file mode 100644
index 0000000000000000000000000000000000000000..156146d9ad86481e7aaa245be39936fbaa1f765f
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/values/values.xml
@@ -0,0 +1,17 @@
+
+
+ 120dp
+ 46px
+
+ 126px
+ 136px
+
+ 46px
+
+ 36px
+
+ 15dp
+
+ 15dp
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/app/src/main/res/xml/ocr_settings.xml b/deploy/fastdeploy/android/app/src/main/res/xml/ocr_settings.xml
new file mode 100644
index 0000000000000000000000000000000000000000..692b74b4cd21fe040ca6dd825040c07e5ecb2f67
--- /dev/null
+++ b/deploy/fastdeploy/android/app/src/main/res/xml/ocr_settings.xml
@@ -0,0 +1,45 @@
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/deploy/fastdeploy/android/build.gradle b/deploy/fastdeploy/android/build.gradle
new file mode 100644
index 0000000000000000000000000000000000000000..d8d678b3ffd56e367294f6c5fb7c4be25df22a7c
--- /dev/null
+++ b/deploy/fastdeploy/android/build.gradle
@@ -0,0 +1,37 @@
+// Top-level build file where you can add configuration options common to all sub-projects/modules.
+//plugins {
+// id 'com.android.application' version '7.2.2' apply false
+// id 'com.android.library' version '7.2.2' apply false
+//}
+//
+//task clean(type: Delete) {
+// delete rootProject.buildDir
+//}
+
+buildscript {
+ repositories {
+ google()
+ jcenter()
+ // mavenCentral()
+
+ }
+ dependencies {
+ classpath 'com.android.tools.build:gradle:7.2.2'
+
+ // NOTE: Do not place your application dependencies here; they belong
+ // in the individual module build.gradle files
+ }
+}
+
+allprojects {
+ repositories {
+ google()
+ jcenter()
+ // mavenCentral()
+
+ }
+}
+
+task clean(type: Delete) {
+ delete rootProject.buildDir
+}
diff --git a/deploy/fastdeploy/android/gradle.properties b/deploy/fastdeploy/android/gradle.properties
new file mode 100644
index 0000000000000000000000000000000000000000..ae995d47ccd9199fa367c2566d87f18caf10b8e5
--- /dev/null
+++ b/deploy/fastdeploy/android/gradle.properties
@@ -0,0 +1,13 @@
+# Project-wide Gradle settings.
+# IDE (e.g. Android Studio) users:
+# Gradle settings configured through the IDE *will override*
+# any settings specified in this file.
+# For more details on how to configure your build environment visit
+# http://www.gradle.org/docs/current/userguide/build_environment.html
+# Specifies the JVM arguments used for the daemon process.
+# The setting is particularly useful for tweaking memory settings.
+org.gradle.jvmargs=-Xmx3096m
+# When configured, Gradle will run in incubating parallel mode.
+# This option should only be used with decoupled projects. More details, visit
+# http://www.gradle.org/docs/current/userguide/multi_project_builds.html#sec:decoupled_projects
+# org.gradle.parallel=true
diff --git a/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.jar b/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.jar
new file mode 100644
index 0000000000000000000000000000000000000000..e708b1c023ec8b20f512888fe07c5bd3ff77bb8f
Binary files /dev/null and b/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.jar differ
diff --git a/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.properties b/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.properties
new file mode 100644
index 0000000000000000000000000000000000000000..7855fafe4997690cd9fdc4db93d3b7491f7fb747
--- /dev/null
+++ b/deploy/fastdeploy/android/gradle/wrapper/gradle-wrapper.properties
@@ -0,0 +1,6 @@
+#Sat Oct 08 17:24:34 CST 2022
+distributionBase=GRADLE_USER_HOME
+distributionUrl=https\://services.gradle.org/distributions/gradle-7.3.3-bin.zip
+distributionPath=wrapper/dists
+zipStorePath=wrapper/dists
+zipStoreBase=GRADLE_USER_HOME
diff --git a/deploy/fastdeploy/android/gradlew b/deploy/fastdeploy/android/gradlew
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/deploy/fastdeploy/android/gradlew.bat b/deploy/fastdeploy/android/gradlew.bat
new file mode 100644
index 0000000000000000000000000000000000000000..107acd32c4e687021ef32db511e8a206129b88ec
--- /dev/null
+++ b/deploy/fastdeploy/android/gradlew.bat
@@ -0,0 +1,89 @@
+@rem
+@rem Copyright 2015 the original author or authors.
+@rem
+@rem Licensed under the Apache License, Version 2.0 (the "License");
+@rem you may not use this file except in compliance with the License.
+@rem You may obtain a copy of the License at
+@rem
+@rem https://www.apache.org/licenses/LICENSE-2.0
+@rem
+@rem Unless required by applicable law or agreed to in writing, software
+@rem distributed under the License is distributed on an "AS IS" BASIS,
+@rem WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+@rem See the License for the specific language governing permissions and
+@rem limitations under the License.
+@rem
+
+@if "%DEBUG%" == "" @echo off
+@rem ##########################################################################
+@rem
+@rem Gradle startup script for Windows
+@rem
+@rem ##########################################################################
+
+@rem Set local scope for the variables with windows NT shell
+if "%OS%"=="Windows_NT" setlocal
+
+set DIRNAME=%~dp0
+if "%DIRNAME%" == "" set DIRNAME=.
+set APP_BASE_NAME=%~n0
+set APP_HOME=%DIRNAME%
+
+@rem Resolve any "." and ".." in APP_HOME to make it shorter.
+for %%i in ("%APP_HOME%") do set APP_HOME=%%~fi
+
+@rem Add default JVM options here. You can also use JAVA_OPTS and GRADLE_OPTS to pass JVM options to this script.
+set DEFAULT_JVM_OPTS="-Xmx64m" "-Xms64m"
+
+@rem Find java.exe
+if defined JAVA_HOME goto findJavaFromJavaHome
+
+set JAVA_EXE=java.exe
+%JAVA_EXE% -version >NUL 2>&1
+if "%ERRORLEVEL%" == "0" goto execute
+
+echo.
+echo ERROR: JAVA_HOME is not set and no 'java' command could be found in your PATH.
+echo.
+echo Please set the JAVA_HOME variable in your environment to match the
+echo location of your Java installation.
+
+goto fail
+
+:findJavaFromJavaHome
+set JAVA_HOME=%JAVA_HOME:"=%
+set JAVA_EXE=%JAVA_HOME%/bin/java.exe
+
+if exist "%JAVA_EXE%" goto execute
+
+echo.
+echo ERROR: JAVA_HOME is set to an invalid directory: %JAVA_HOME%
+echo.
+echo Please set the JAVA_HOME variable in your environment to match the
+echo location of your Java installation.
+
+goto fail
+
+:execute
+@rem Setup the command line
+
+set CLASSPATH=%APP_HOME%\gradle\wrapper\gradle-wrapper.jar
+
+
+@rem Execute Gradle
+"%JAVA_EXE%" %DEFAULT_JVM_OPTS% %JAVA_OPTS% %GRADLE_OPTS% "-Dorg.gradle.appname=%APP_BASE_NAME%" -classpath "%CLASSPATH%" org.gradle.wrapper.GradleWrapperMain %*
+
+:end
+@rem End local scope for the variables with windows NT shell
+if "%ERRORLEVEL%"=="0" goto mainEnd
+
+:fail
+rem Set variable GRADLE_EXIT_CONSOLE if you need the _script_ return code instead of
+rem the _cmd.exe /c_ return code!
+if not "" == "%GRADLE_EXIT_CONSOLE%" exit 1
+exit /b 1
+
+:mainEnd
+if "%OS%"=="Windows_NT" endlocal
+
+:omega
diff --git a/deploy/fastdeploy/android/local.properties b/deploy/fastdeploy/android/local.properties
new file mode 100644
index 0000000000000000000000000000000000000000..aaa0de9aa3c1c41e9997edd9bc95a5aeba2fed62
--- /dev/null
+++ b/deploy/fastdeploy/android/local.properties
@@ -0,0 +1,8 @@
+## This file must *NOT* be checked into Version Control Systems,
+# as it contains information specific to your local configuration.
+#
+# Location of the SDK. This is only used by Gradle.
+# For customization when using a Version Control System, please read the
+# header note.
+#Tue Nov 29 18:47:20 CST 2022
+sdk.dir=D\:\\androidsdk
diff --git a/deploy/fastdeploy/android/settings.gradle b/deploy/fastdeploy/android/settings.gradle
new file mode 100644
index 0000000000000000000000000000000000000000..e7b4def49cb53d9aa04228dd3edb14c9e635e003
--- /dev/null
+++ b/deploy/fastdeploy/android/settings.gradle
@@ -0,0 +1 @@
+include ':app'
diff --git a/deploy/fastdeploy/ascend/README.md b/deploy/fastdeploy/ascend/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e13de3ef8bdbc98c530f6acce2d882a56210b6d
--- /dev/null
+++ b/deploy/fastdeploy/ascend/README.md
@@ -0,0 +1,23 @@
+[English](README.md) | 简体中文
+
+# PaddleOCR 模型在华为昇腾上部署方案-FastDeploy
+
+## 1. 说明
+PaddleOCR支持通过FastDeploy在华为昇腾上部署相关模型
+
+## 2. 支持模型列表
+
+下表中的模型下载链接由PaddleOCR模型库提供, 详见[PP-OCR系列模型列表](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md)
+
+| PaddleOCR版本 | 文本框检测 | 方向分类模型 | 文字识别 |字典文件| 说明 |
+|:----|:----|:----|:----|:----|:--------|
+| ch_PP-OCRv3[推荐] |[ch_PP-OCRv3_det](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_PP-OCRv3_rec](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv3系列原始超轻量模型,支持中英文、多语种文本检测 |
+| en_PP-OCRv3[推荐] |[en_PP-OCRv3_det](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [en_PP-OCRv3_rec](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) | [en_dict.txt](https://bj.bcebos.com/paddlehub/fastdeploy/en_dict.txt) | OCRv3系列原始超轻量模型,支持英文与数字识别,除检测模型和识别模型的训练数据与中文模型不同以外,无其他区别 |
+| ch_PP-OCRv2 |[ch_PP-OCRv2_det](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_PP-OCRv2_rec](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2系列原始超轻量模型,支持中英文、多语种文本检测 |
+| ch_PP-OCRv2_mobile |[ch_ppocr_mobile_v2.0_det](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_ppocr_mobile_v2.0_rec](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2系列原始超轻量模型,支持中英文、多语种文本检测,比PPOCRv2更加轻量 |
+| ch_PP-OCRv2_server |[ch_ppocr_server_v2.0_det](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_ppocr_server_v2.0_rec](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) |[ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2服务器系列模型, 支持中英文、多语种文本检测,比超轻量模型更大,但效果更好|
+
+
+## 3. 详细部署的部署示例
+- [Python部署](python)
+- [C++部署](cpp)
diff --git a/deploy/fastdeploy/ascend/cpp/CMakeLists.txt b/deploy/fastdeploy/ascend/cpp/CMakeLists.txt
new file mode 100644
index 0000000000000000000000000000000000000000..93540a7e83e05228bcb38042a91166c858c95137
--- /dev/null
+++ b/deploy/fastdeploy/ascend/cpp/CMakeLists.txt
@@ -0,0 +1,14 @@
+PROJECT(infer_demo C CXX)
+CMAKE_MINIMUM_REQUIRED (VERSION 3.10)
+
+# 指定下载解压后的fastdeploy库路径
+option(FASTDEPLOY_INSTALL_DIR "Path of downloaded fastdeploy sdk.")
+
+include(${FASTDEPLOY_INSTALL_DIR}/FastDeploy.cmake)
+
+# 添加FastDeploy依赖头文件
+include_directories(${FASTDEPLOY_INCS})
+
+add_executable(infer_demo ${PROJECT_SOURCE_DIR}/infer.cc)
+# 添加FastDeploy库依赖
+target_link_libraries(infer_demo ${FASTDEPLOY_LIBS})
diff --git a/deploy/fastdeploy/ascend/cpp/README.md b/deploy/fastdeploy/ascend/cpp/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ed8d63a309074a4d1b6626eb8b0d7c7e5d443fbd
--- /dev/null
+++ b/deploy/fastdeploy/ascend/cpp/README.md
@@ -0,0 +1,63 @@
+[English](README.md) | 简体中文
+# PP-OCRv3 Ascend C++部署示例
+
+本目录下提供`infer.cc`, 供用户完成PP-OCRv3在华为昇腾AI处理器上的部署.
+
+## 1. 部署环境准备
+在部署前,需确认以下两个步骤
+- 1. 在部署前,需自行编译基于华为昇腾AI处理器的预测库,参考文档[华为昇腾AI处理器部署环境编译](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install#自行编译安装)
+- 2. 部署时需要环境初始化, 请参考[如何使用C++在华为昇腾AI处理器部署](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/use_sdk_on_ascend.md)
+
+
+## 2.部署模型准备
+在部署前, 请准备好您所需要运行的推理模型, 您可以在[FastDeploy支持的PaddleOCR模型列表](../README.md)中下载所需模型.
+
+## 3.运行部署示例
+```
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy/examples/vision/ocr/PP-OCR/ascend/cpp
+
+# 如果您希望从PaddleOCR下载示例代码,请运行
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到dygraph分支
+git checkout dygraph
+cd PaddleOCR/deploy/fastdeploy/ascend/cpp
+
+mkdir build
+cd build
+# 使用编译完成的FastDeploy库编译infer_demo
+cmake .. -DFASTDEPLOY_INSTALL_DIR=${PWD}/fastdeploy-ascend
+make -j
+
+# 下载PP-OCRv3文字检测模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
+tar -xvf ch_PP-OCRv3_det_infer.tar
+# 下载文字方向分类器模型
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
+tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar
+# 下载PP-OCRv3文字识别模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
+tar -xvf ch_PP-OCRv3_rec_infer.tar
+
+# 下载预测图片与字典文件
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
+
+# 按照上文提供的文档完成环境初始化, 并执行以下命令
+./infer_demo ./ch_PP-OCRv3_det_infer ./ch_ppocr_mobile_v2.0_cls_infer ./ch_PP-OCRv3_rec_infer ./ppocr_keys_v1.txt ./12.jpg
+
+# NOTE:若用户需要连续地预测图片, 输入图片尺寸需要准备为统一尺寸, 例如 N 张, 尺寸为 A * B 的图片.
+```
+
+运行完成可视化结果如下图所示
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+ +
+
+
+
+
+## 3. 服务端的使用
+
+### 3.1 下载模型并使用服务化Docker
+```bash
+# 下载仓库代码
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy/examples/vision/ocr/PP-OCR/serving/fastdeploy_serving
+
+# 如果您希望从PaddleOCR下载示例代码,请运行
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到dygraph分支
+git checkout dygraph
+cd PaddleOCR/deploy/fastdeploy/serving/fastdeploy_serving
+
+# 下载模型,图片和字典文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
+tar xvf ch_PP-OCRv3_det_infer.tar && mv ch_PP-OCRv3_det_infer 1
+mv 1/inference.pdiparams 1/model.pdiparams && mv 1/inference.pdmodel 1/model.pdmodel
+mv 1 models/det_runtime/ && rm -rf ch_PP-OCRv3_det_infer.tar
+
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
+tar xvf ch_ppocr_mobile_v2.0_cls_infer.tar && mv ch_ppocr_mobile_v2.0_cls_infer 1
+mv 1/inference.pdiparams 1/model.pdiparams && mv 1/inference.pdmodel 1/model.pdmodel
+mv 1 models/cls_runtime/ && rm -rf ch_ppocr_mobile_v2.0_cls_infer.tar
+
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
+tar xvf ch_PP-OCRv3_rec_infer.tar && mv ch_PP-OCRv3_rec_infer 1
+mv 1/inference.pdiparams 1/model.pdiparams && mv 1/inference.pdmodel 1/model.pdmodel
+mv 1 models/rec_runtime/ && rm -rf ch_PP-OCRv3_rec_infer.tar
+
+mkdir models/pp_ocr/1 && mkdir models/rec_pp/1 && mkdir models/cls_pp/1
+
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
+mv ppocr_keys_v1.txt models/rec_postprocess/1/
+
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
+
+# x.y.z为镜像版本号,需参照serving文档替换为数字
+docker pull registry.baidubce.com/paddlepaddle/fastdeploy:x.y.z-gpu-cuda11.4-trt8.4-21.10
+docker run -dit --net=host --name fastdeploy --shm-size="1g" -v $PWD:/ocr_serving registry.baidubce.com/paddlepaddle/fastdeploy:x.y.z-gpu-cuda11.4-trt8.4-21.10 bash
+docker exec -it -u root fastdeploy bash
+```
+
+### 3.2 安装(在docker内)
+```bash
+ldconfig
+apt-get install libgl1
+```
+
+#### 3.3 启动服务端(在docker内)
+```bash
+fastdeployserver --model-repository=/ocr_serving/models
+```
+
+参数:
+ - `model-repository`(required): 整套模型streaming_pp_tts存放的路径.
+ - `http-port`(optional): HTTP服务的端口号. 默认: `8000`. 本示例中未使用该端口.
+ - `grpc-port`(optional): GRPC服务的端口号. 默认: `8001`.
+ - `metrics-port`(optional): 服务端指标的端口号. 默认: `8002`. 本示例中未使用该端口.
+
+
+## 4. 客户端的使用
+### 4.1 安装
+```bash
+pip3 install tritonclient[all]
+```
+
+### 4.2 发送请求
+```bash
+python3 client.py
+```
+
+## 5.配置修改
+当前默认配置在GPU上运行, 如果要在CPU或其他推理引擎上运行。 需要修改`models/runtime/config.pbtxt`中配置,详情请参考[配置文档](../../../../../serving/docs/zh_CN/model_configuration.md)
+
+## 6. 其他指南
+
+- 使用PP-OCRv2进行服务化部署, 除了自行准备PP-OCRv2模型之外, 只需手动添加一行代码即可.
+在[model.py](./models/det_postprocess/1/model.py#L109)文件**109行添加以下代码**:
+```
+self.rec_preprocessor.cls_image_shape[1] = 32
+```
+
+- [使用 VisualDL 进行 Serving 可视化部署](https://github.com/PaddlePaddle/FastDeploy/blob/develop/serving/docs/zh_CN/vdl_management.md)
+通过VisualDL的可视化界面对PP-OCRv3进行服务化部署只需要如下三步:
+```text
+1. 载入模型库:./vision/ocr/PP-OCRv3/serving
+2. 下载模型资源文件:点击det_runtime模型,点击版本号1添加预训练模型,选择文字识别模型ch_PP-OCRv3_det进行下载。点击cls_runtime模型,点击版本号1添加预训练模型,选择文字识别模型ch_ppocr_mobile_v2.0_cls进行下载。点击rec_runtime模型,点击版本号1添加预训练模型,选择文字识别模型ch_PP-OCRv3_rec进行下载。点击rec_postprocess模型,点击版本号1添加预训练模型,选择文字识别模型ch_PP-OCRv3_rec进行下载。
+3. 启动服务:点击启动服务按钮,输入启动参数。
+```
+
+  +
+
+
+## 7. 常见问题
+- [如何编写客户端 HTTP/GRPC 请求](https://github.com/PaddlePaddle/FastDeploy/blob/develop/serving/docs/zh_CN/client.md)
+- [如何编译服务化部署镜像](https://github.com/PaddlePaddle/FastDeploy/blob/develop/serving/docs/zh_CN/compile.md)
+- [服务化部署原理及动态Batch介绍](https://github.com/PaddlePaddle/FastDeploy/blob/develop/serving/docs/zh_CN/demo.md)
+- [模型仓库介绍](https://github.com/PaddlePaddle/FastDeploy/blob/develop/serving/docs/zh_CN/model_repository.md)
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/client.py b/deploy/fastdeploy/serving/fastdeploy_serving/client.py
new file mode 100755
index 0000000000000000000000000000000000000000..6b758c5e39ac0fada03e4e7a561e4a4d0192c6e0
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/client.py
@@ -0,0 +1,109 @@
+import logging
+import numpy as np
+import time
+from typing import Optional
+import cv2
+import json
+
+from tritonclient import utils as client_utils
+from tritonclient.grpc import InferenceServerClient, InferInput, InferRequestedOutput, service_pb2_grpc, service_pb2
+
+LOGGER = logging.getLogger("run_inference_on_triton")
+
+
+class SyncGRPCTritonRunner:
+ DEFAULT_MAX_RESP_WAIT_S = 120
+
+ def __init__(
+ self,
+ server_url: str,
+ model_name: str,
+ model_version: str,
+ *,
+ verbose=False,
+ resp_wait_s: Optional[float]=None, ):
+ self._server_url = server_url
+ self._model_name = model_name
+ self._model_version = model_version
+ self._verbose = verbose
+ self._response_wait_t = self.DEFAULT_MAX_RESP_WAIT_S if resp_wait_s is None else resp_wait_s
+
+ self._client = InferenceServerClient(
+ self._server_url, verbose=self._verbose)
+ error = self._verify_triton_state(self._client)
+ if error:
+ raise RuntimeError(
+ f"Could not communicate to Triton Server: {error}")
+
+ LOGGER.debug(
+ f"Triton server {self._server_url} and model {self._model_name}:{self._model_version} "
+ f"are up and ready!")
+
+ model_config = self._client.get_model_config(self._model_name,
+ self._model_version)
+ model_metadata = self._client.get_model_metadata(self._model_name,
+ self._model_version)
+ LOGGER.info(f"Model config {model_config}")
+ LOGGER.info(f"Model metadata {model_metadata}")
+
+ self._inputs = {tm.name: tm for tm in model_metadata.inputs}
+ self._input_names = list(self._inputs)
+ self._outputs = {tm.name: tm for tm in model_metadata.outputs}
+ self._output_names = list(self._outputs)
+ self._outputs_req = [
+ InferRequestedOutput(name) for name in self._outputs
+ ]
+
+ def Run(self, inputs):
+ """
+ Args:
+ inputs: list, Each value corresponds to an input name of self._input_names
+ Returns:
+ results: dict, {name : numpy.array}
+ """
+ infer_inputs = []
+ for idx, data in enumerate(inputs):
+ infer_input = InferInput(self._input_names[idx], data.shape,
+ "UINT8")
+ infer_input.set_data_from_numpy(data)
+ infer_inputs.append(infer_input)
+
+ results = self._client.infer(
+ model_name=self._model_name,
+ model_version=self._model_version,
+ inputs=infer_inputs,
+ outputs=self._outputs_req,
+ client_timeout=self._response_wait_t, )
+ results = {name: results.as_numpy(name) for name in self._output_names}
+ return results
+
+ def _verify_triton_state(self, triton_client):
+ if not triton_client.is_server_live():
+ return f"Triton server {self._server_url} is not live"
+ elif not triton_client.is_server_ready():
+ return f"Triton server {self._server_url} is not ready"
+ elif not triton_client.is_model_ready(self._model_name,
+ self._model_version):
+ return f"Model {self._model_name}:{self._model_version} is not ready"
+ return None
+
+
+if __name__ == "__main__":
+ model_name = "pp_ocr"
+ model_version = "1"
+ url = "localhost:8001"
+ runner = SyncGRPCTritonRunner(url, model_name, model_version)
+ im = cv2.imread("12.jpg")
+ im = np.array([im, ])
+ for i in range(1):
+ result = runner.Run([im, ])
+ batch_texts = result['rec_texts']
+ batch_scores = result['rec_scores']
+ batch_bboxes = result['det_bboxes']
+ for i_batch in range(len(batch_texts)):
+ texts = batch_texts[i_batch]
+ scores = batch_scores[i_batch]
+ bboxes = batch_bboxes[i_batch]
+ for i_box in range(len(texts)):
+ print('text=', texts[i_box].decode('utf-8'), ' score=',
+ scores[i_box], ' bbox=', bboxes[i_box])
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/1/model.py b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/1/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..891db5f24b8f117c6d499e258dd5e16ee7a7f356
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/1/model.py
@@ -0,0 +1,105 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import numpy as np
+import time
+
+import fastdeploy as fd
+
+# triton_python_backend_utils is available in every Triton Python model. You
+# need to use this module to create inference requests and responses. It also
+# contains some utility functions for extracting information from model_config
+# and converting Triton input/output types to numpy types.
+import triton_python_backend_utils as pb_utils
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # You must parse model_config. JSON string is not parsed here
+ self.model_config = json.loads(args['model_config'])
+ print("model_config:", self.model_config)
+
+ self.input_names = []
+ for input_config in self.model_config["input"]:
+ self.input_names.append(input_config["name"])
+ print("postprocess input names:", self.input_names)
+
+ self.output_names = []
+ self.output_dtype = []
+ for output_config in self.model_config["output"]:
+ self.output_names.append(output_config["name"])
+ dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+ self.output_dtype.append(dtype)
+ print("postprocess output names:", self.output_names)
+ self.postprocessor = fd.vision.ocr.ClassifierPostprocessor()
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+ responses = []
+ for request in requests:
+ infer_outputs = pb_utils.get_input_tensor_by_name(
+ request, self.input_names[0])
+ infer_outputs = infer_outputs.as_numpy()
+ results = self.postprocessor.run([infer_outputs])
+ out_tensor_0 = pb_utils.Tensor(self.output_names[0],
+ np.array(results[0]))
+ out_tensor_1 = pb_utils.Tensor(self.output_names[1],
+ np.array(results[1]))
+ inference_response = pb_utils.InferenceResponse(
+ output_tensors=[out_tensor_0, out_tensor_1])
+ responses.append(inference_response)
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print('Cleaning up...')
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..18ab2facc6389217da7b16fc91804b1a52b0ce30
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_postprocess/config.pbtxt
@@ -0,0 +1,30 @@
+name: "cls_postprocess"
+backend: "python"
+max_batch_size: 128
+input [
+ {
+ name: "POST_INPUT_0"
+ data_type: TYPE_FP32
+ dims: [ 2 ]
+ }
+]
+
+output [
+ {
+ name: "POST_OUTPUT_0"
+ data_type: TYPE_INT32
+ dims: [ 1 ]
+ },
+ {
+ name: "POST_OUTPUT_1"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_pp/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_pp/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..068b1e7d87954eb66b59b99a74b7693a98060e33
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_pp/config.pbtxt
@@ -0,0 +1,54 @@
+name: "cls_pp"
+platform: "ensemble"
+max_batch_size: 128
+input [
+ {
+ name: "x"
+ data_type: TYPE_FP32
+ dims: [ 3, -1, -1 ]
+ }
+]
+output [
+ {
+ name: "cls_labels"
+ data_type: TYPE_INT32
+ dims: [ 1 ]
+ },
+ {
+ name: "cls_scores"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "cls_runtime"
+ model_version: 1
+ input_map {
+ key: "x"
+ value: "x"
+ }
+ output_map {
+ key: "softmax_0.tmp_0"
+ value: "infer_output"
+ }
+ },
+ {
+ model_name: "cls_postprocess"
+ model_version: 1
+ input_map {
+ key: "POST_INPUT_0"
+ value: "infer_output"
+ }
+ output_map {
+ key: "POST_OUTPUT_0"
+ value: "cls_labels"
+ }
+ output_map {
+ key: "POST_OUTPUT_1"
+ value: "cls_scores"
+ }
+ }
+ ]
+}
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_runtime/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_runtime/config.pbtxt
new file mode 100755
index 0000000000000000000000000000000000000000..eb7b2550366a9c69cc90e002d5390eee99e31abb
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/cls_runtime/config.pbtxt
@@ -0,0 +1,52 @@
+# optional, If name is specified it must match the name of the model repository directory containing the model.
+name: "cls_runtime"
+backend: "fastdeploy"
+max_batch_size: 128
+
+# Input configuration of the model
+input [
+ {
+ # input name
+ name: "x"
+ # input type such as TYPE_FP32、TYPE_UINT8、TYPE_INT8、TYPE_INT16、TYPE_INT32、TYPE_INT64、TYPE_FP16、TYPE_STRING
+ data_type: TYPE_FP32
+ # input shape, The batch dimension is omitted and the actual shape is [batch, c, h, w]
+ dims: [ 3, -1, -1 ]
+ }
+]
+
+# The output of the model is configured in the same format as the input
+output [
+ {
+ name: "softmax_0.tmp_0"
+ data_type: TYPE_FP32
+ dims: [ 2 ]
+ }
+]
+
+# Number of instances of the model
+instance_group [
+ {
+ # The number of instances is 1
+ count: 1
+ # Use GPU, CPU inference option is:KIND_CPU
+ kind: KIND_GPU
+ # The instance is deployed on the 0th GPU card
+ gpus: [0]
+ }
+]
+
+optimization {
+ execution_accelerators {
+ # GPU推理配置, 配合KIND_GPU使用
+ gpu_execution_accelerator : [
+ {
+ name : "paddle"
+ # 设置推理并行计算线程数为4
+ parameters { key: "cpu_threads" value: "4" }
+ # 开启mkldnn加速,设置为0关闭mkldnn
+ parameters { key: "use_mkldnn" value: "1" }
+ }
+ ]
+ }
+}
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/1/model.py b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/1/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..87115c2d949762adfe3796487e93bc6e94483a60
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/1/model.py
@@ -0,0 +1,238 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import numpy as np
+import time
+import math
+import cv2
+import fastdeploy as fd
+
+# triton_python_backend_utils is available in every Triton Python model. You
+# need to use this module to create inference requests and responses. It also
+# contains some utility functions for extracting information from model_config
+# and converting Triton input/output types to numpy types.
+import triton_python_backend_utils as pb_utils
+
+
+def get_rotate_crop_image(img, box):
+ '''
+ img_height, img_width = img.shape[0:2]
+ left = int(np.min(points[:, 0]))
+ right = int(np.max(points[:, 0]))
+ top = int(np.min(points[:, 1]))
+ bottom = int(np.max(points[:, 1]))
+ img_crop = img[top:bottom, left:right, :].copy()
+ points[:, 0] = points[:, 0] - left
+ points[:, 1] = points[:, 1] - top
+ '''
+ points = []
+ for i in range(4):
+ points.append([box[2 * i], box[2 * i + 1]])
+ points = np.array(points, dtype=np.float32)
+ img = img.astype(np.float32)
+ assert len(points) == 4, "shape of points must be 4*2"
+ img_crop_width = int(
+ max(
+ np.linalg.norm(points[0] - points[1]),
+ np.linalg.norm(points[2] - points[3])))
+ img_crop_height = int(
+ max(
+ np.linalg.norm(points[0] - points[3]),
+ np.linalg.norm(points[1] - points[2])))
+ pts_std = np.float32([[0, 0], [img_crop_width, 0],
+ [img_crop_width, img_crop_height],
+ [0, img_crop_height]])
+ M = cv2.getPerspectiveTransform(points, pts_std)
+ dst_img = cv2.warpPerspective(
+ img,
+ M, (img_crop_width, img_crop_height),
+ borderMode=cv2.BORDER_REPLICATE,
+ flags=cv2.INTER_CUBIC)
+ dst_img_height, dst_img_width = dst_img.shape[0:2]
+ if dst_img_height * 1.0 / dst_img_width >= 1.5:
+ dst_img = np.rot90(dst_img)
+ return dst_img
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # You must parse model_config. JSON string is not parsed here
+ self.model_config = json.loads(args['model_config'])
+ print("model_config:", self.model_config)
+
+ self.input_names = []
+ for input_config in self.model_config["input"]:
+ self.input_names.append(input_config["name"])
+ print("postprocess input names:", self.input_names)
+
+ self.output_names = []
+ self.output_dtype = []
+ for output_config in self.model_config["output"]:
+ self.output_names.append(output_config["name"])
+ dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+ self.output_dtype.append(dtype)
+ print("postprocess output names:", self.output_names)
+ self.postprocessor = fd.vision.ocr.DBDetectorPostprocessor()
+ self.cls_preprocessor = fd.vision.ocr.ClassifierPreprocessor()
+ self.rec_preprocessor = fd.vision.ocr.RecognizerPreprocessor()
+ self.cls_threshold = 0.9
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+ responses = []
+ for request in requests:
+ infer_outputs = pb_utils.get_input_tensor_by_name(
+ request, self.input_names[0])
+ im_infos = pb_utils.get_input_tensor_by_name(request,
+ self.input_names[1])
+ ori_imgs = pb_utils.get_input_tensor_by_name(request,
+ self.input_names[2])
+
+ infer_outputs = infer_outputs.as_numpy()
+ im_infos = im_infos.as_numpy()
+ ori_imgs = ori_imgs.as_numpy()
+
+ results = self.postprocessor.run([infer_outputs], im_infos)
+ batch_rec_texts = []
+ batch_rec_scores = []
+ batch_box_list = []
+ for i_batch in range(len(results)):
+
+ cls_labels = []
+ cls_scores = []
+ rec_texts = []
+ rec_scores = []
+
+ box_list = fd.vision.ocr.sort_boxes(results[i_batch])
+ image_list = []
+ if len(box_list) == 0:
+ image_list.append(ori_imgs[i_batch])
+ else:
+ for box in box_list:
+ crop_img = get_rotate_crop_image(ori_imgs[i_batch], box)
+ image_list.append(crop_img)
+
+ batch_box_list.append(box_list)
+
+ cls_pre_tensors = self.cls_preprocessor.run(image_list)
+ cls_dlpack_tensor = cls_pre_tensors[0].to_dlpack()
+ cls_input_tensor = pb_utils.Tensor.from_dlpack(
+ "x", cls_dlpack_tensor)
+
+ inference_request = pb_utils.InferenceRequest(
+ model_name='cls_pp',
+ requested_output_names=['cls_labels', 'cls_scores'],
+ inputs=[cls_input_tensor])
+ inference_response = inference_request.exec()
+ if inference_response.has_error():
+ raise pb_utils.TritonModelException(
+ inference_response.error().message())
+ else:
+ # Extract the output tensors from the inference response.
+ cls_labels = pb_utils.get_output_tensor_by_name(
+ inference_response, 'cls_labels')
+ cls_labels = cls_labels.as_numpy()
+
+ cls_scores = pb_utils.get_output_tensor_by_name(
+ inference_response, 'cls_scores')
+ cls_scores = cls_scores.as_numpy()
+
+ for index in range(len(image_list)):
+ if cls_labels[index] == 1 and cls_scores[
+ index] > self.cls_threshold:
+ image_list[index] = cv2.rotate(
+ image_list[index].astype(np.float32), 1)
+ image_list[index] = np.astype(np.uint8)
+
+ rec_pre_tensors = self.rec_preprocessor.run(image_list)
+ rec_dlpack_tensor = rec_pre_tensors[0].to_dlpack()
+ rec_input_tensor = pb_utils.Tensor.from_dlpack(
+ "x", rec_dlpack_tensor)
+
+ inference_request = pb_utils.InferenceRequest(
+ model_name='rec_pp',
+ requested_output_names=['rec_texts', 'rec_scores'],
+ inputs=[rec_input_tensor])
+ inference_response = inference_request.exec()
+ if inference_response.has_error():
+ raise pb_utils.TritonModelException(
+ inference_response.error().message())
+ else:
+ # Extract the output tensors from the inference response.
+ rec_texts = pb_utils.get_output_tensor_by_name(
+ inference_response, 'rec_texts')
+ rec_texts = rec_texts.as_numpy()
+
+ rec_scores = pb_utils.get_output_tensor_by_name(
+ inference_response, 'rec_scores')
+ rec_scores = rec_scores.as_numpy()
+
+ batch_rec_texts.append(rec_texts)
+ batch_rec_scores.append(rec_scores)
+
+ out_tensor_0 = pb_utils.Tensor(
+ self.output_names[0],
+ np.array(
+ batch_rec_texts, dtype=np.object_))
+ out_tensor_1 = pb_utils.Tensor(self.output_names[1],
+ np.array(batch_rec_scores))
+ out_tensor_2 = pb_utils.Tensor(self.output_names[2],
+ np.array(batch_box_list))
+ inference_response = pb_utils.InferenceResponse(
+ output_tensors=[out_tensor_0, out_tensor_1, out_tensor_2])
+ responses.append(inference_response)
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print('Cleaning up...')
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..378b7bab64f76a71163177f071f776b104c00df3
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_postprocess/config.pbtxt
@@ -0,0 +1,45 @@
+name: "det_postprocess"
+backend: "python"
+max_batch_size: 128
+input [
+ {
+ name: "POST_INPUT_0"
+ data_type: TYPE_FP32
+ dims: [ 1, -1, -1]
+ },
+ {
+ name: "POST_INPUT_1"
+ data_type: TYPE_INT32
+ dims: [ 4 ]
+ },
+ {
+ name: "ORI_IMG"
+ data_type: TYPE_UINT8
+ dims: [ -1, -1, 3 ]
+ }
+]
+
+output [
+ {
+ name: "POST_OUTPUT_0"
+ data_type: TYPE_STRING
+ dims: [ -1, 1 ]
+ },
+ {
+ name: "POST_OUTPUT_1"
+ data_type: TYPE_FP32
+ dims: [ -1, 1 ]
+ },
+ {
+ name: "POST_OUTPUT_2"
+ data_type: TYPE_FP32
+ dims: [ -1, -1, 1 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/1/model.py b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/1/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..28e838da5b6394b7ae14d0ad5f99bded996b14d8
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/1/model.py
@@ -0,0 +1,107 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import numpy as np
+import time
+
+import fastdeploy as fd
+
+# triton_python_backend_utils is available in every Triton Python model. You
+# need to use this module to create inference requests and responses. It also
+# contains some utility functions for extracting information from model_config
+# and converting Triton input/output types to numpy types.
+import triton_python_backend_utils as pb_utils
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # You must parse model_config. JSON string is not parsed here
+ self.model_config = json.loads(args['model_config'])
+ print("model_config:", self.model_config)
+
+ self.input_names = []
+ for input_config in self.model_config["input"]:
+ self.input_names.append(input_config["name"])
+ print("preprocess input names:", self.input_names)
+
+ self.output_names = []
+ self.output_dtype = []
+ for output_config in self.model_config["output"]:
+ self.output_names.append(output_config["name"])
+ dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+ self.output_dtype.append(dtype)
+ print("preprocess output names:", self.output_names)
+ self.preprocessor = fd.vision.ocr.DBDetectorPreprocessor()
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+ responses = []
+ for request in requests:
+ data = pb_utils.get_input_tensor_by_name(request,
+ self.input_names[0])
+ data = data.as_numpy()
+ outputs, im_infos = self.preprocessor.run(data)
+ dlpack_tensor = outputs[0].to_dlpack()
+ output_tensor_0 = pb_utils.Tensor.from_dlpack(self.output_names[0],
+ dlpack_tensor)
+ output_tensor_1 = pb_utils.Tensor(
+ self.output_names[1], np.array(
+ im_infos, dtype=np.int32))
+ inference_response = pb_utils.InferenceResponse(
+ output_tensors=[output_tensor_0, output_tensor_1])
+ responses.append(inference_response)
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print('Cleaning up...')
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..93aa1d062ebb440429e588f0cefe9bb6235a2932
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_preprocess/config.pbtxt
@@ -0,0 +1,37 @@
+# optional, If name is specified it must match the name of the model repository directory containing the model.
+name: "det_preprocess"
+backend: "python"
+max_batch_size: 1
+
+# Input configuration of the model
+input [
+ {
+ # input name
+ name: "INPUT_0"
+ # input type such as TYPE_FP32、TYPE_UINT8、TYPE_INT8、TYPE_INT16、TYPE_INT32、TYPE_INT64、TYPE_FP16、TYPE_STRING
+ data_type: TYPE_UINT8
+ # input shape, The batch dimension is omitted and the actual shape is [batch, c, h, w]
+ dims: [ -1, -1, 3 ]
+ }
+]
+
+# The output of the model is configured in the same format as the input
+output [
+ {
+ name: "OUTPUT_0"
+ data_type: TYPE_FP32
+ dims: [ 3, -1, -1 ]
+ },
+ {
+ name: "OUTPUT_1"
+ data_type: TYPE_INT32
+ dims: [ 4 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/det_runtime/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_runtime/config.pbtxt
new file mode 100755
index 0000000000000000000000000000000000000000..96d85e3e1941293b049242b1c2b1cf207bb108bc
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/det_runtime/config.pbtxt
@@ -0,0 +1,52 @@
+# optional, If name is specified it must match the name of the model repository directory containing the model.
+name: "det_runtime"
+backend: "fastdeploy"
+max_batch_size: 1
+
+# Input configuration of the model
+input [
+ {
+ # input name
+ name: "x"
+ # input type such as TYPE_FP32、TYPE_UINT8、TYPE_INT8、TYPE_INT16、TYPE_INT32、TYPE_INT64、TYPE_FP16、TYPE_STRING
+ data_type: TYPE_FP32
+ # input shape, The batch dimension is omitted and the actual shape is [batch, c, h, w]
+ dims: [ 3, -1, -1 ]
+ }
+]
+
+# The output of the model is configured in the same format as the input
+output [
+ {
+ name: "sigmoid_0.tmp_0"
+ data_type: TYPE_FP32
+ dims: [ 1, -1, -1 ]
+ }
+]
+
+# Number of instances of the model
+instance_group [
+ {
+ # The number of instances is 1
+ count: 1
+ # Use GPU, CPU inference option is:KIND_CPU
+ kind: KIND_GPU
+ # The instance is deployed on the 0th GPU card
+ gpus: [0]
+ }
+]
+
+optimization {
+ execution_accelerators {
+ # GPU推理配置, 配合KIND_GPU使用
+ gpu_execution_accelerator : [
+ {
+ name : "paddle"
+ # 设置推理并行计算线程数为4
+ parameters { key: "cpu_threads" value: "4" }
+ # 开启mkldnn加速,设置为0关闭mkldnn
+ parameters { key: "use_mkldnn" value: "1" }
+ }
+ ]
+ }
+}
\ No newline at end of file
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/pp_ocr/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/pp_ocr/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..5ef951107e4f36696a46ce7396ddedc5c9316cee
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/pp_ocr/config.pbtxt
@@ -0,0 +1,87 @@
+name: "pp_ocr"
+platform: "ensemble"
+max_batch_size: 1
+input [
+ {
+ name: "INPUT"
+ data_type: TYPE_UINT8
+ dims: [ -1, -1, 3 ]
+ }
+]
+output [
+ {
+ name: "rec_texts"
+ data_type: TYPE_STRING
+ dims: [ -1, 1 ]
+ },
+ {
+ name: "rec_scores"
+ data_type: TYPE_FP32
+ dims: [ -1, 1 ]
+ },
+ {
+ name: "det_bboxes"
+ data_type: TYPE_FP32
+ dims: [ -1, -1, 1 ]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "det_preprocess"
+ model_version: 1
+ input_map {
+ key: "INPUT_0"
+ value: "INPUT"
+ }
+ output_map {
+ key: "OUTPUT_0"
+ value: "infer_input"
+ }
+ output_map {
+ key: "OUTPUT_1"
+ value: "infos"
+ }
+ },
+ {
+ model_name: "det_runtime"
+ model_version: 1
+ input_map {
+ key: "x"
+ value: "infer_input"
+ }
+ output_map {
+ key: "sigmoid_0.tmp_0"
+ value: "infer_output"
+ }
+ },
+ {
+ model_name: "det_postprocess"
+ model_version: 1
+ input_map {
+ key: "POST_INPUT_0"
+ value: "infer_output"
+ }
+ input_map {
+ key: "POST_INPUT_1"
+ value: "infos"
+ }
+ input_map {
+ key: "ORI_IMG"
+ value: "INPUT"
+ }
+ output_map {
+ key: "POST_OUTPUT_0"
+ value: "rec_texts"
+ }
+ output_map {
+ key: "POST_OUTPUT_1"
+ value: "rec_scores"
+ }
+ output_map {
+ key: "POST_OUTPUT_2"
+ value: "det_bboxes"
+ }
+ }
+ ]
+}
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/1/model.py b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/1/model.py
new file mode 100755
index 0000000000000000000000000000000000000000..c046cd929b75175bcbeceea80f14a8fb04c733ca
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/1/model.py
@@ -0,0 +1,112 @@
+# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import numpy as np
+import time
+import os
+import sys
+import codecs
+import fastdeploy as fd
+
+# triton_python_backend_utils is available in every Triton Python model. You
+# need to use this module to create inference requests and responses. It also
+# contains some utility functions for extracting information from model_config
+# and converting Triton input/output types to numpy types.
+import triton_python_backend_utils as pb_utils
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # You must parse model_config. JSON string is not parsed here
+ self.model_config = json.loads(args['model_config'])
+ print("model_config:", self.model_config)
+
+ self.input_names = []
+ for input_config in self.model_config["input"]:
+ self.input_names.append(input_config["name"])
+ print("postprocess input names:", self.input_names)
+
+ self.output_names = []
+ self.output_dtype = []
+ for output_config in self.model_config["output"]:
+ self.output_names.append(output_config["name"])
+ dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+ self.output_dtype.append(dtype)
+ print("postprocess output names:", self.output_names)
+
+ dir_name = os.path.dirname(os.path.realpath(__file__)) + "/"
+ file_name = dir_name + "ppocr_keys_v1.txt"
+ #self.label_list = load_dict()
+ self.postprocessor = fd.vision.ocr.RecognizerPostprocessor(file_name)
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+ responses = []
+ for request in requests:
+ infer_outputs = pb_utils.get_input_tensor_by_name(
+ request, self.input_names[0])
+ infer_outputs = infer_outputs.as_numpy()
+ results = self.postprocessor.run([infer_outputs])
+ out_tensor_0 = pb_utils.Tensor(
+ self.output_names[0], np.array(
+ results[0], dtype=np.object_))
+ out_tensor_1 = pb_utils.Tensor(self.output_names[1],
+ np.array(results[1]))
+ inference_response = pb_utils.InferenceResponse(
+ output_tensors=[out_tensor_0, out_tensor_1])
+ responses.append(inference_response)
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print('Cleaning up...')
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..c125140c8b15f8d090ed7ef72ee855454059aa42
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_postprocess/config.pbtxt
@@ -0,0 +1,30 @@
+name: "rec_postprocess"
+backend: "python"
+max_batch_size: 128
+input [
+ {
+ name: "POST_INPUT_0"
+ data_type: TYPE_FP32
+ dims: [ -1, 6625 ]
+ }
+]
+
+output [
+ {
+ name: "POST_OUTPUT_0"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "POST_OUTPUT_1"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_pp/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_pp/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..bb79f90012ba70fc1eac7779218395c3135be8f4
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_pp/config.pbtxt
@@ -0,0 +1,54 @@
+name: "rec_pp"
+platform: "ensemble"
+max_batch_size: 128
+input [
+ {
+ name: "x"
+ data_type: TYPE_FP32
+ dims: [ 3, 48, -1 ]
+ }
+]
+output [
+ {
+ name: "rec_texts"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "rec_scores"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "rec_runtime"
+ model_version: 1
+ input_map {
+ key: "x"
+ value: "x"
+ }
+ output_map {
+ key: "softmax_5.tmp_0"
+ value: "infer_output"
+ }
+ },
+ {
+ model_name: "rec_postprocess"
+ model_version: 1
+ input_map {
+ key: "POST_INPUT_0"
+ value: "infer_output"
+ }
+ output_map {
+ key: "POST_OUTPUT_0"
+ value: "rec_texts"
+ }
+ output_map {
+ key: "POST_OUTPUT_1"
+ value: "rec_scores"
+ }
+ }
+ ]
+}
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_runtime/config.pbtxt b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_runtime/config.pbtxt
new file mode 100755
index 0000000000000000000000000000000000000000..037d7a9f285550c8946bcf3f3cb9191c667a792c
--- /dev/null
+++ b/deploy/fastdeploy/serving/fastdeploy_serving/models/rec_runtime/config.pbtxt
@@ -0,0 +1,52 @@
+# optional, If name is specified it must match the name of the model repository directory containing the model.
+name: "rec_runtime"
+backend: "fastdeploy"
+max_batch_size: 128
+
+# Input configuration of the model
+input [
+ {
+ # input name
+ name: "x"
+ # input type such as TYPE_FP32、TYPE_UINT8、TYPE_INT8、TYPE_INT16、TYPE_INT32、TYPE_INT64、TYPE_FP16、TYPE_STRING
+ data_type: TYPE_FP32
+ # input shape, The batch dimension is omitted and the actual shape is [batch, c, h, w]
+ dims: [ 3, 48, -1 ]
+ }
+]
+
+# The output of the model is configured in the same format as the input
+output [
+ {
+ name: "softmax_5.tmp_0"
+ data_type: TYPE_FP32
+ dims: [ -1, 6625 ]
+ }
+]
+
+# Number of instances of the model
+instance_group [
+ {
+ # The number of instances is 1
+ count: 1
+ # Use GPU, CPU inference option is:KIND_CPU
+ kind: KIND_GPU
+ # The instance is deployed on the 0th GPU card
+ gpus: [0]
+ }
+]
+
+optimization {
+ execution_accelerators {
+ # GPU推理配置, 配合KIND_GPU使用
+ gpu_execution_accelerator : [
+ {
+ name : "paddle"
+ # 设置推理并行计算线程数为4
+ parameters { key: "cpu_threads" value: "4" }
+ # 开启mkldnn加速,设置为0关闭mkldnn
+ parameters { key: "use_mkldnn" value: "1" }
+ }
+ ]
+ }
+}
\ No newline at end of file
diff --git a/deploy/fastdeploy/serving/fastdeploy_serving/ppocr.png b/deploy/fastdeploy/serving/fastdeploy_serving/ppocr.png
new file mode 100644
index 0000000000000000000000000000000000000000..db12eddc49c9afe0d2d6ea661633abd8eff50c1b
Binary files /dev/null and b/deploy/fastdeploy/serving/fastdeploy_serving/ppocr.png differ
diff --git a/deploy/fastdeploy/serving/simple_serving/README.md b/deploy/fastdeploy/serving/simple_serving/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..913475c79ea9f304719afec335cf0ade3531d691
--- /dev/null
+++ b/deploy/fastdeploy/serving/simple_serving/README.md
@@ -0,0 +1,54 @@
+简体中文 | [English](README.md)
+
+
+# PaddleOCR Python轻量服务化部署示例
+
+PaddleOCR Python轻量服务化部署是FastDeploy基于Flask框架搭建的可快速验证线上模型部署可行性的服务化部署示例,基于http请求完成AI推理任务,适用于无并发推理的简单场景,如有高并发,高吞吐场景的需求请参考[fastdeploy_serving](../fastdeploy_serving/)
+
+
+## 1. 部署环境准备
+
+在部署前,需确认软硬件环境,同时下载预编译python wheel 包,参考文档[FastDeploy预编译库安装](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install#FastDeploy预编译库安装)
+
+
+## 2. 启动服务
+```bash
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy/examples/vision/ocr/PP-OCR/serving/simple_serving
+
+# 如果您希望从PaddleOCR下载示例代码,请运行
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到dygraph分支
+git checkout dygraph
+cd PaddleOCR/deploy/fastdeploy/serving/simple_serving
+
+# 下载模型和字典文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
+tar xvf ch_PP-OCRv3_det_infer.tar
+
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
+tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar
+
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
+tar xvf ch_PP-OCRv3_rec_infer.tar
+
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
+
+# 启动服务,可修改server.py中的配置项来指定硬件、后端等
+# 可通过--host、--port指定IP和端口号
+fastdeploy simple_serving --app server:app
+```
+
+## 3. 客户端请求
+```bash
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR/deploy/fastdeploy/serving/simple_serving
+
+# 下载测试图片
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
+
+# 请求服务,获取推理结果(如有必要,请修改脚本中的IP和端口号)
+python client.py
+```
diff --git a/deploy/fastdeploy/serving/simple_serving/client.py b/deploy/fastdeploy/serving/simple_serving/client.py
new file mode 100644
index 0000000000000000000000000000000000000000..6849c22046e67492c6a7d9db15fcf3f6b5a40d5d
--- /dev/null
+++ b/deploy/fastdeploy/serving/simple_serving/client.py
@@ -0,0 +1,24 @@
+import requests
+import json
+import cv2
+import fastdeploy as fd
+from fastdeploy.serving.utils import cv2_to_base64
+
+if __name__ == '__main__':
+ url = "http://127.0.0.1:8000/fd/ppocrv3"
+ headers = {"Content-Type": "application/json"}
+
+ im = cv2.imread("12.jpg")
+ data = {"data": {"image": cv2_to_base64(im)}, "parameters": {}}
+
+ resp = requests.post(url=url, headers=headers, data=json.dumps(data))
+ if resp.status_code == 200:
+ r_json = json.loads(resp.json()["result"])
+ print(r_json)
+ ocr_result = fd.vision.utils.json_to_ocr(r_json)
+ vis_im = fd.vision.vis_ppocr(im, ocr_result)
+ cv2.imwrite("visualized_result.jpg", vis_im)
+ print("Visualized result save in ./visualized_result.jpg")
+ else:
+ print("Error code:", resp.status_code)
+ print(resp.text)
diff --git a/deploy/fastdeploy/serving/simple_serving/server.py b/deploy/fastdeploy/serving/simple_serving/server.py
new file mode 100644
index 0000000000000000000000000000000000000000..0078b7112f91004926ced6623253589cdc68cab2
--- /dev/null
+++ b/deploy/fastdeploy/serving/simple_serving/server.py
@@ -0,0 +1,80 @@
+import fastdeploy as fd
+from fastdeploy.serving.server import SimpleServer
+import os
+import logging
+
+logging.getLogger().setLevel(logging.INFO)
+
+# Configurations
+det_model_dir = 'ch_PP-OCRv3_det_infer'
+cls_model_dir = 'ch_ppocr_mobile_v2.0_cls_infer'
+rec_model_dir = 'ch_PP-OCRv3_rec_infer'
+rec_label_file = 'ppocr_keys_v1.txt'
+device = 'cpu'
+# backend: ['paddle', 'trt'], you can also use other backends, but need to modify
+# the runtime option below
+backend = 'paddle'
+
+# Prepare models
+# Detection model
+det_model_file = os.path.join(det_model_dir, "inference.pdmodel")
+det_params_file = os.path.join(det_model_dir, "inference.pdiparams")
+# Classification model
+cls_model_file = os.path.join(cls_model_dir, "inference.pdmodel")
+cls_params_file = os.path.join(cls_model_dir, "inference.pdiparams")
+# Recognition model
+rec_model_file = os.path.join(rec_model_dir, "inference.pdmodel")
+rec_params_file = os.path.join(rec_model_dir, "inference.pdiparams")
+
+# Setup runtime option to select hardware, backend, etc.
+option = fd.RuntimeOption()
+if device.lower() == 'gpu':
+ option.use_gpu()
+if backend == 'trt':
+ option.use_trt_backend()
+else:
+ option.use_paddle_infer_backend()
+
+det_option = option
+det_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],
+ [1, 3, 960, 960])
+
+# det_option.set_trt_cache_file("det_trt_cache.trt")
+print(det_model_file, det_params_file)
+det_model = fd.vision.ocr.DBDetector(
+ det_model_file, det_params_file, runtime_option=det_option)
+
+cls_batch_size = 1
+rec_batch_size = 6
+
+cls_option = option
+cls_option.set_trt_input_shape("x", [1, 3, 48, 10],
+ [cls_batch_size, 3, 48, 320],
+ [cls_batch_size, 3, 48, 1024])
+
+# cls_option.set_trt_cache_file("cls_trt_cache.trt")
+cls_model = fd.vision.ocr.Classifier(
+ cls_model_file, cls_params_file, runtime_option=cls_option)
+
+rec_option = option
+rec_option.set_trt_input_shape("x", [1, 3, 48, 10],
+ [rec_batch_size, 3, 48, 320],
+ [rec_batch_size, 3, 48, 2304])
+
+# rec_option.set_trt_cache_file("rec_trt_cache.trt")
+rec_model = fd.vision.ocr.Recognizer(
+ rec_model_file, rec_params_file, rec_label_file, runtime_option=rec_option)
+
+# Create PPOCRv3 pipeline
+ppocr_v3 = fd.vision.ocr.PPOCRv3(
+ det_model=det_model, cls_model=cls_model, rec_model=rec_model)
+
+ppocr_v3.cls_batch_size = cls_batch_size
+ppocr_v3.rec_batch_size = rec_batch_size
+
+# Create server, setup REST API
+app = SimpleServer()
+app.register(
+ task_name="fd/ppocrv3",
+ model_handler=fd.serving.handler.VisionModelHandler,
+ predictor=ppocr_v3)
diff --git a/deploy/fastdeploy/sophgo/README.md b/deploy/fastdeploy/sophgo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9fd2e9563f48263cda37e98a6b4cf49ec5d53b4f
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/README.md
@@ -0,0 +1,102 @@
+[English](README.md) | 简体中文
+
+# PaddleOCR 模型在SOPHGO上部署方案-FastDeploy
+
+## 1. 说明
+PaddleOCR支持通过FastDeploy在SOPHGO上部署相关模型.
+
+## 2.支持模型列表
+
+下表中的模型下载链接由PaddleOCR模型库提供, 详见[PP-OCR系列模型列表](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md)
+
+| PaddleOCR版本 | 文本框检测 | 方向分类模型 | 文字识别 |字典文件| 说明 |
+|:----|:----|:----|:----|:----|:--------|
+| ch_PP-OCRv3[推荐] |[ch_PP-OCRv3_det](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_PP-OCRv3_rec](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv3系列原始超轻量模型,支持中英文、多语种文本检测 |
+| en_PP-OCRv3[推荐] |[en_PP-OCRv3_det](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [en_PP-OCRv3_rec](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) | [en_dict.txt](https://bj.bcebos.com/paddlehub/fastdeploy/en_dict.txt) | OCRv3系列原始超轻量模型,支持英文与数字识别,除检测模型和识别模型的训练数据与中文模型不同以外,无其他区别 |
+| ch_PP-OCRv2 |[ch_PP-OCRv2_det](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_PP-OCRv2_rec](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2系列原始超轻量模型,支持中英文、多语种文本检测 |
+| ch_PP-OCRv2_mobile |[ch_ppocr_mobile_v2.0_det](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_ppocr_mobile_v2.0_rec](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) | [ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2系列原始超轻量模型,支持中英文、多语种文本检测,比PPOCRv2更加轻量 |
+| ch_PP-OCRv2_server |[ch_ppocr_server_v2.0_det](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) | [ch_ppocr_mobile_v2.0_cls](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) | [ch_ppocr_server_v2.0_rec](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) |[ppocr_keys_v1.txt](https://bj.bcebos.com/paddlehub/fastdeploy/ppocr_keys_v1.txt) | OCRv2服务器系列模型, 支持中英文、多语种文本检测,比超轻量模型更大,但效果更好|
+
+## 3. 准备PP-OCR推理模型以及转换模型
+
+PP-OCRv3包括文本检测模型(ch_PP-OCRv3_det)、方向分类模型(ch_ppocr_mobile_v2.0_cls)、文字识别模型(ch_PP-OCRv3_rec)
+SOPHGO-TPU部署模型前需要将以上Paddle模型转换成bmodel模型,我们以ch_PP-OCRv3_det模型为例,具体步骤如下:
+- 下载Paddle模型[ch_PP-OCRv3_det](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar)
+- Pddle模型转换为ONNX模型,请参考[Paddle2ONNX](https://github.com/PaddlePaddle/Paddle2ONNX)
+- ONNX模型转换bmodel模型的过程,请参考[TPU-MLIR](https://github.com/sophgo/tpu-mlir)
+下面我们提供一个example, 供用户参考,完成模型的转换.
+
+### 3.1 下载ch_PP-OCRv3_det模型,并转换为ONNX模型
+```shell
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
+tar xvf ch_PP-OCRv3_det_infer.tar
+
+# 修改ch_PP-OCRv3_det模型的输入shape,由动态输入变成固定输入
+python paddle_infer_shape.py --model_dir ch_PP-OCRv3_det_infer \
+ --model_filename inference.pdmodel \
+ --params_filename inference.pdiparams \
+ --save_dir ch_PP-OCRv3_det_infer_fix \
+ --input_shape_dict="{'x':[1,3,960,608]}"
+
+# 请用户自行安装最新发布版本的paddle2onnx, 转换模型到ONNX格式的模型
+paddle2onnx --model_dir ch_PP-OCRv3_det_infer_fix \
+ --model_filename inference.pdmodel \
+ --params_filename inference.pdiparams \
+ --save_file ch_PP-OCRv3_det_infer_fix.onnx \
+ --enable_dev_version True
+```
+
+### 3.2 导出bmodel模型
+
+以转换BM1684x的bmodel模型为例子,我们需要下载[TPU-MLIR](https://github.com/sophgo/tpu-mlir)工程,安装过程具体参见[TPU-MLIR文档](https://github.com/sophgo/tpu-mlir/blob/master/README.md)。
+#### 3.2.1 安装
+``` shell
+docker pull sophgo/tpuc_dev:latest
+
+# myname1234是一个示例,也可以设置其他名字
+docker run --privileged --name myname1234 -v $PWD:/workspace -it sophgo/tpuc_dev:latest
+
+source ./envsetup.sh
+./build.sh
+```
+
+#### 3.2.2 ONNX模型转换为bmodel模型
+``` shell
+mkdir ch_PP-OCRv3_det && cd ch_PP-OCRv3_det
+
+#在该文件中放入测试图片,同时将上一步转换的ch_PP-OCRv3_det_infer_fix.onnx放入该文件夹中
+cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
+cp -rf ${REGRESSION_PATH}/image .
+#放入onnx模型文件ch_PP-OCRv3_det_infer_fix.onnx
+
+mkdir workspace && cd workspace
+
+#将ONNX模型转换为mlir模型,其中参数--output_names可以通过NETRON查看
+model_transform.py \
+ --model_name ch_PP-OCRv3_det \
+ --model_def ../ch_PP-OCRv3_det_infer_fix.onnx \
+ --input_shapes [[1,3,960,608]] \
+ --mean 0.0,0.0,0.0 \
+ --scale 0.0039216,0.0039216,0.0039216 \
+ --keep_aspect_ratio \
+ --pixel_format rgb \
+ --output_names sigmoid_0.tmp_0 \
+ --test_input ../image/dog.jpg \
+ --test_result ch_PP-OCRv3_det_top_outputs.npz \
+ --mlir ch_PP-OCRv3_det.mlir
+
+#将mlir模型转换为BM1684x的F32 bmodel模型
+model_deploy.py \
+ --mlir ch_PP-OCRv3_det.mlir \
+ --quantize F32 \
+ --chip bm1684x \
+ --test_input ch_PP-OCRv3_det_in_f32.npz \
+ --test_reference ch_PP-OCRv3_det_top_outputs.npz \
+ --model ch_PP-OCRv3_det_1684x_f32.bmodel
+```
+最终获得可以在BM1684x上能够运行的bmodel模型ch_PP-OCRv3_det_1684x_f32.bmodel。按照上面同样的方法,可以将ch_ppocr_mobile_v2.0_cls,ch_PP-OCRv3_rec转换为bmodel的格式。如果需要进一步对模型进行加速,可以将ONNX模型转换为INT8 bmodel,具体步骤参见[TPU-MLIR文档](https://github.com/sophgo/tpu-mlir/blob/master/README.md)。
+
+
+## 4. 详细部署的部署示例
+- [Python部署](python)
+- [C++部署](cpp)
diff --git a/deploy/fastdeploy/sophgo/cpp/CMakeLists.txt b/deploy/fastdeploy/sophgo/cpp/CMakeLists.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b32846afedc66b290e53721191493645b04fb707
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/cpp/CMakeLists.txt
@@ -0,0 +1,13 @@
+PROJECT(infer_demo C CXX)
+CMAKE_MINIMUM_REQUIRED (VERSION 3.10)
+# 指定下载解压后的fastdeploy库路径
+option(FASTDEPLOY_INSTALL_DIR "Path of downloaded fastdeploy sdk.")
+
+include(${FASTDEPLOY_INSTALL_DIR}/FastDeploy.cmake)
+
+# 添加FastDeploy依赖头文件
+include_directories(${FASTDEPLOY_INCS})
+
+add_executable(infer_demo ${PROJECT_SOURCE_DIR}/infer.cc)
+# 添加FastDeploy库依赖
+target_link_libraries(infer_demo ${FASTDEPLOY_LIBS})
diff --git a/deploy/fastdeploy/sophgo/cpp/README.md b/deploy/fastdeploy/sophgo/cpp/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b17f7df879684c77b3a83b01adf4cc550f1f49f
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/cpp/README.md
@@ -0,0 +1,66 @@
+[English](README_CN.md) | 简体中文
+# PP-OCRv3 SOPHGO C++部署示例
+本目录下提供`infer.cc`快速完成PPOCRv3模型在SOPHGO BM1684x板子上加速部署的示例。
+
+## 1. 部署环境准备
+在部署前,需自行编译基于SOPHGO硬件的预测库,参考文档[SOPHGO硬件部署环境](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install#算能硬件部署环境)
+
+## 2. 生成基本目录文件
+
+该例程由以下几个部分组成
+```text
+.
+├── CMakeLists.txt
+├── fastdeploy-sophgo # 编译好的SDK文件夹
+├── image # 存放图片的文件夹
+├── infer.cc
+└── model # 存放模型文件的文件夹
+```
+
+## 3.部署示例
+
+### 3.1 下载部署示例代码
+```bash
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy/examples/vision/ocr/PP-OCR/sophgo/cpp
+
+# 如果您希望从PaddleOCR下载示例代码,请运行
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到dygraph分支
+git checkout dygraph
+cd PaddleOCR/deploy/fastdeploy/sophgo/cpp
+```
+
+### 3.2 拷贝bmodel模型文至model文件夹
+将Paddle模型转换为SOPHGO bmodel模型,转换步骤参考[文档](../README.md). 将转换后的SOPHGO bmodel模型文件拷贝至model中.
+
+### 3.3 准备测试图片至image文件夹,以及字典文件
+```bash
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
+cp 12.jpg image/
+
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
+```
+
+### 3.4 编译example
+
+```bash
+cd build
+cmake .. -DFASTDEPLOY_INSTALL_DIR=${PWD}/fastdeploy-0.0.3
+make
+```
+
+### 3.5 运行例程
+
+```bash
+./infer_demo model ./ppocr_keys_v1.txt image/12.jpeg
+```
+
+
+## 4. 更多指南
+
+- [PP-OCR系列 C++ API查阅](https://www.paddlepaddle.org.cn/fastdeploy-api-doc/cpp/html/namespacefastdeploy_1_1vision_1_1ocr.html)
+- [FastDeploy部署PaddleOCR模型概览](../../)
+- [PP-OCRv3 Python部署](../python)
+- 如果用户想要调整前后处理超参数、单独使用文字检测识别模型、使用其他模型等,更多详细文档与说明请参考[PP-OCR系列在CPU/GPU上的部署](../../cpu-gpu/cpp/README.md)
diff --git a/deploy/fastdeploy/sophgo/cpp/infer.cc b/deploy/fastdeploy/sophgo/cpp/infer.cc
new file mode 100644
index 0000000000000000000000000000000000000000..181561b39e94c6e242502de24c17aadcda2d34c7
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/cpp/infer.cc
@@ -0,0 +1,136 @@
+// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "fastdeploy/vision.h"
+#ifdef WIN32
+const char sep = '\\';
+#else
+const char sep = '/';
+#endif
+
+void InitAndInfer(const std::string &det_model_dir,
+ const std::string &rec_label_file,
+ const std::string &image_file,
+ const fastdeploy::RuntimeOption &option) {
+ auto det_model_file =
+ det_model_dir + sep + "ch_PP-OCRv3_det_1684x_f32.bmodel";
+ auto det_params_file = det_model_dir + sep + "";
+
+ auto cls_model_file =
+ det_model_dir + sep + "ch_ppocr_mobile_v2.0_cls_1684x_f32.bmodel";
+ auto cls_params_file = det_model_dir + sep + "";
+
+ auto rec_model_file =
+ det_model_dir + sep + "ch_PP-OCRv3_rec_1684x_f32.bmodel";
+ auto rec_params_file = det_model_dir + sep + "";
+
+ auto format = fastdeploy::ModelFormat::SOPHGO;
+
+ auto det_option = option;
+ auto cls_option = option;
+ auto rec_option = option;
+
+ // The cls and rec model can inference a batch of images now.
+ // User could initialize the inference batch size and set them after create
+ // PPOCR model.
+ int cls_batch_size = 1;
+ int rec_batch_size = 1;
+
+ // If use TRT backend, the dynamic shape will be set as follow.
+ // We recommend that users set the length and height of the detection model to
+ // a multiple of 32. We also recommend that users set the Trt input shape as
+ // follow.
+ det_option.SetTrtInputShape("x", {1, 3, 64, 64}, {1, 3, 640, 640},
+ {1, 3, 960, 960});
+ cls_option.SetTrtInputShape("x", {1, 3, 48, 10}, {cls_batch_size, 3, 48, 320},
+ {cls_batch_size, 3, 48, 1024});
+ rec_option.SetTrtInputShape("x", {1, 3, 48, 10}, {rec_batch_size, 3, 48, 320},
+ {rec_batch_size, 3, 48, 2304});
+
+ // Users could save TRT cache file to disk as follow.
+ // det_option.SetTrtCacheFile(det_model_dir + sep + "det_trt_cache.trt");
+ // cls_option.SetTrtCacheFile(cls_model_dir + sep + "cls_trt_cache.trt");
+ // rec_option.SetTrtCacheFile(rec_model_dir + sep + "rec_trt_cache.trt");
+
+ auto det_model = fastdeploy::vision::ocr::DBDetector(
+ det_model_file, det_params_file, det_option, format);
+ auto cls_model = fastdeploy::vision::ocr::Classifier(
+ cls_model_file, cls_params_file, cls_option, format);
+ auto rec_model = fastdeploy::vision::ocr::Recognizer(
+ rec_model_file, rec_params_file, rec_label_file, rec_option, format);
+
+ // Users could enable static shape infer for rec model when deploy PP-OCR on
+ // hardware which can not support dynamic shape infer well, like Huawei Ascend
+ // series.
+ rec_model.GetPreprocessor().SetStaticShapeInfer(true);
+ rec_model.GetPreprocessor().SetRecImageShape({3, 48, 584});
+
+ assert(det_model.Initialized());
+ assert(cls_model.Initialized());
+ assert(rec_model.Initialized());
+
+ // The classification model is optional, so the PP-OCR can also be connected
+ // in series as follows auto ppocr_v3 =
+ // fastdeploy::pipeline::PPOCRv3(&det_model, &rec_model);
+ auto ppocr_v3 =
+ fastdeploy::pipeline::PPOCRv3(&det_model, &cls_model, &rec_model);
+
+ // Set inference batch size for cls model and rec model, the value could be -1
+ // and 1 to positive infinity. When inference batch size is set to -1, it
+ // means that the inference batch size of the cls and rec models will be the
+ // same as the number of boxes detected by the det model.
+ ppocr_v3.SetClsBatchSize(cls_batch_size);
+ ppocr_v3.SetRecBatchSize(rec_batch_size);
+
+ if (!ppocr_v3.Initialized()) {
+ std::cerr << "Failed to initialize PP-OCR." << std::endl;
+ return;
+ }
+
+ auto im = cv::imread(image_file);
+ auto im_bak = im.clone();
+
+ fastdeploy::vision::OCRResult result;
+ if (!ppocr_v3.Predict(&im, &result)) {
+ std::cerr << "Failed to predict." << std::endl;
+ return;
+ }
+
+ std::cout << result.Str() << std::endl;
+
+ auto vis_im = fastdeploy::vision::VisOcr(im_bak, result);
+ cv::imwrite("vis_result.jpg", vis_im);
+ std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
+}
+
+int main(int argc, char *argv[]) {
+ if (argc < 4) {
+ std::cout << "Usage: infer_demo path/to/model "
+ "path/to/rec_label_file path/to/image "
+ "e.g ./infer_demo ./ocr_bmodel "
+ "./ppocr_keys_v1.txt ./12.jpg"
+ << std::endl;
+ return -1;
+ }
+
+ fastdeploy::RuntimeOption option;
+ option.UseSophgo();
+ option.UseSophgoBackend();
+
+ std::string model_dir = argv[1];
+ std::string rec_label_file = argv[2];
+ std::string test_image = argv[3];
+ InitAndInfer(model_dir, rec_label_file, test_image, option);
+ return 0;
+}
diff --git a/deploy/fastdeploy/sophgo/python/README.md b/deploy/fastdeploy/sophgo/python/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..27dbe2694cd7ca71b9f16960937fde8564a5b4d4
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/python/README.md
@@ -0,0 +1,52 @@
+[English](README.md) | 简体中文
+# PP-OCRv3 SOPHGO Python部署示例
+本目录下提供`infer.py`快速完成 PP-OCRv3 在SOPHGO TPU上部署的示例。
+
+## 1. 部署环境准备
+
+在部署前,需自行编译基于算能硬件的FastDeploy python wheel包并安装,参考文档[算能硬件部署环境](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install#算能硬件部署环境)
+
+
+## 2.运行部署示例
+
+### 2.1 模型准备
+将Paddle模型转换为SOPHGO bmodel模型, 转换步骤参考[文档](../README.md)
+
+### 2.2 开始部署
+```bash
+# 下载部署示例代码
+git clone https://github.com/PaddlePaddle/FastDeploy.git
+cd FastDeploy/examples/vision/ocr/PP-OCR/sophgo/python
+
+# 如果您希望从PaddleOCR下载示例代码,请运行
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到dygraph分支
+git checkout dygraph
+cd PaddleOCR/deploy/fastdeploy/sophgo/python
+
+# 下载图片
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/doc/imgs/12.jpg
+
+#下载字典文件
+wget https://gitee.com/paddlepaddle/PaddleOCR/raw/release/2.6/ppocr/utils/ppocr_keys_v1.txt
+
+# 推理
+python3 infer.py --det_model ocr_bmodel/ch_PP-OCRv3_det_1684x_f32.bmodel \
+ --cls_model ocr_bmodel/ch_ppocr_mobile_v2.0_cls_1684x_f32.bmodel \
+ --rec_model ocr_bmodel/ch_PP-OCRv3_rec_1684x_f32.bmodel \
+ --rec_label_file ../ppocr_keys_v1.txt \
+ --image ../12.jpg
+
+# 运行完成后返回结果如下所示
+det boxes: [[42,413],[483,391],[484,428],[43,450]]rec text: 上海斯格威铂尔大酒店 rec score:0.952958 cls label: 0 cls score: 1.000000
+det boxes: [[187,456],[399,448],[400,480],[188,488]]rec text: 打浦路15号 rec score:0.897335 cls label: 0 cls score: 1.000000
+det boxes: [[23,507],[513,488],[515,529],[24,548]]rec text: 绿洲仕格维花园公寓 rec score:0.994589 cls label: 0 cls score: 1.000000
+det boxes: [[74,553],[427,542],[428,571],[75,582]]rec text: 打浦路252935号 rec score:0.900663 cls label: 0 cls score: 1.000000
+
+可视化结果保存在sophgo_result.jpg中
+```
+
+## 3. 其它文档
+- [PP-OCRv3 C++部署](../cpp)
+- [转换 PP-OCRv3 SOPHGO模型文档](../README.md)
+- 如果用户想要调整前后处理超参数、单独使用文字检测识别模型、使用其他模型等,更多详细文档与说明请参考[PP-OCR系列在CPU/GPU上的部署](../../cpu-gpu/cpp/README.md)
diff --git a/deploy/fastdeploy/sophgo/python/infer.py b/deploy/fastdeploy/sophgo/python/infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..356317099f4072bad3830c403c14913c74f573cd
--- /dev/null
+++ b/deploy/fastdeploy/sophgo/python/infer.py
@@ -0,0 +1,116 @@
+import fastdeploy as fd
+import cv2
+import os
+
+
+def parse_arguments():
+ import argparse
+ import ast
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--det_model", required=True, help="Path of Detection model of PPOCR.")
+ parser.add_argument(
+ "--cls_model",
+ required=True,
+ help="Path of Classification model of PPOCR.")
+ parser.add_argument(
+ "--rec_model",
+ required=True,
+ help="Path of Recognization model of PPOCR.")
+ parser.add_argument(
+ "--rec_label_file",
+ required=True,
+ help="Path of Recognization label of PPOCR.")
+ parser.add_argument(
+ "--image", type=str, required=True, help="Path of test image file.")
+
+ return parser.parse_args()
+
+
+args = parse_arguments()
+
+# 配置runtime,加载模型
+runtime_option = fd.RuntimeOption()
+runtime_option.use_sophgo()
+
+# Detection模型, 检测文字框
+det_model_file = args.det_model
+det_params_file = ""
+# Classification模型,方向分类,可选
+cls_model_file = args.cls_model
+cls_params_file = ""
+# Recognition模型,文字识别模型
+rec_model_file = args.rec_model
+rec_params_file = ""
+rec_label_file = args.rec_label_file
+
+# PPOCR的cls和rec模型现在已经支持推理一个Batch的数据
+# 定义下面两个变量后, 可用于设置trt输入shape, 并在PPOCR模型初始化后, 完成Batch推理设置
+cls_batch_size = 1
+rec_batch_size = 1
+
+# 当使用TRT时,分别给三个模型的runtime设置动态shape,并完成模型的创建.
+# 注意: 需要在检测模型创建完成后,再设置分类模型的动态输入并创建分类模型, 识别模型同理.
+# 如果用户想要自己改动检测模型的输入shape, 我们建议用户把检测模型的长和高设置为32的倍数.
+det_option = runtime_option
+det_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],
+ [1, 3, 960, 960])
+# 用户可以把TRT引擎文件保存至本地
+# det_option.set_trt_cache_file(args.det_model + "/det_trt_cache.trt")
+det_model = fd.vision.ocr.DBDetector(
+ det_model_file,
+ det_params_file,
+ runtime_option=det_option,
+ model_format=fd.ModelFormat.SOPHGO)
+
+cls_option = runtime_option
+cls_option.set_trt_input_shape("x", [1, 3, 48, 10],
+ [cls_batch_size, 3, 48, 320],
+ [cls_batch_size, 3, 48, 1024])
+# 用户可以把TRT引擎文件保存至本地
+# cls_option.set_trt_cache_file(args.cls_model + "/cls_trt_cache.trt")
+cls_model = fd.vision.ocr.Classifier(
+ cls_model_file,
+ cls_params_file,
+ runtime_option=cls_option,
+ model_format=fd.ModelFormat.SOPHGO)
+
+rec_option = runtime_option
+rec_option.set_trt_input_shape("x", [1, 3, 48, 10],
+ [rec_batch_size, 3, 48, 320],
+ [rec_batch_size, 3, 48, 2304])
+# 用户可以把TRT引擎文件保存至本地
+# rec_option.set_trt_cache_file(args.rec_model + "/rec_trt_cache.trt")
+rec_model = fd.vision.ocr.Recognizer(
+ rec_model_file,
+ rec_params_file,
+ rec_label_file,
+ runtime_option=rec_option,
+ model_format=fd.ModelFormat.SOPHGO)
+
+# 创建PP-OCR,串联3个模型,其中cls_model可选,如无需求,可设置为None
+ppocr_v3 = fd.vision.ocr.PPOCRv3(
+ det_model=det_model, cls_model=cls_model, rec_model=rec_model)
+
+# 需要使用下行代码, 来启用rec模型的静态shape推理,这里rec模型的静态输入为[3, 48, 584]
+rec_model.preprocessor.static_shape_infer = True
+rec_model.preprocessor.rec_image_shape = [3, 48, 584]
+
+# 给cls和rec模型设置推理时的batch size
+# 此值能为-1, 和1到正无穷
+# 当此值为-1时, cls和rec模型的batch size将默认和det模型检测出的框的数量相同
+ppocr_v3.cls_batch_size = cls_batch_size
+ppocr_v3.rec_batch_size = rec_batch_size
+
+# 预测图片准备
+im = cv2.imread(args.image)
+
+#预测并打印结果
+result = ppocr_v3.predict(im)
+
+print(result)
+
+# 可视化结果
+vis_im = fd.vision.vis_ppocr(im, result)
+cv2.imwrite("sophgo_result.jpg", vis_im)
+print("Visualized result save in ./sophgo_result.jpg")
diff --git a/deploy/fastdeploy/web/README.md b/deploy/fastdeploy/web/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ca9628d30630d538479e6df90c744a1eea52261
--- /dev/null
+++ b/deploy/fastdeploy/web/README.md
@@ -0,0 +1,33 @@
+[English](README.md) | 简体中文
+# PP-OCRv3 前端部署示例
+
+本节介绍部署PaddleOCR的PP-OCRv3模型在浏览器中运行,以及@paddle-js-models/ocr npm包中的js接口。
+
+
+## 1. 前端部署PP-OCRv3模型
+PP-OCRv3模型web demo使用[**参考文档**](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo)
+
+## 2. PP-OCRv3 js接口
+
+```
+import * as ocr from "@paddle-js-models/ocr";
+await ocr.init(detConfig, recConfig);
+const res = await ocr.recognize(img, option, postConfig);
+```
+ocr模型加载和初始化,其中模型为Paddle.js模型格式,js模型转换方式参考[文档](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/README.md)
+
+**init函数参数**
+
+> * **detConfig**(dict): 文本检测模型配置参数,默认值为 {modelPath: 'https://js-models.bj.bcebos.com/PaddleOCR/PP-OCRv3/ch_PP-OCRv3_det_infer_js_960/model.json', fill: '#fff', mean: [0.485, 0.456, 0.406],std: [0.229, 0.224, 0.225]}; 其中,modelPath为文本检测模型路径,fill 为图像预处理padding的值,mean和std分别为预处理的均值和标准差
+> * **recConfig**(dict)): 文本识别模型配置参数,默认值为 {modelPath: 'https://js-models.bj.bcebos.com/PaddleOCR/PP-OCRv3/ch_PP-OCRv3_rec_infer_js/model.json', fill: '#000', mean: [0.5, 0.5, 0.5], std: [0.5, 0.5, 0.5]}; 其中,modelPath为文本检测模型路径,fill 为图像预处理padding的值,mean和std分别为预处理的均值和标准差
+
+
+**recognize函数参数**
+
+> * **img**(HTMLImageElement): 输入图像参数,类型为HTMLImageElement。
+> * **option**(dict): 可视化文本检测框的canvas参数,可不用设置。
+> * **postConfig**(dict): 文本检测后处理参数,默认值为:{shape: 960, thresh: 0.3, box_thresh: 0.6, unclip_ratio:1.5}; thresh是输出预测图的二值化阈值;box_thresh是输出框的阈值,低于此值的预测框会被丢弃,unclip_ratio是输出框扩大的比例。
+
+
+## 其它文档
+- [PP-OCRv3 微信小程序部署文档](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program)
diff --git a/deploy/hubserving/ocr_det/module.py b/deploy/hubserving/ocr_det/module.py
index 8fef3be017eef1c6a52395348624f5bfcb6260e7..3dbaf161cdfd59528a36b5d5f645656cade2f1fc 100644
--- a/deploy/hubserving/ocr_det/module.py
+++ b/deploy/hubserving/ocr_det/module.py
@@ -122,7 +122,7 @@ class OCRDet(hub.Module):
rec_res_final = []
for dno in range(len(dt_boxes)):
rec_res_final.append({
- 'text_region': dt_boxes[dno].astype(np.int).tolist()
+ 'text_region': dt_boxes[dno].astype(np.int32).tolist()
})
all_results.append(rec_res_final)
return all_results
diff --git a/deploy/hubserving/ocr_system/module.py b/deploy/hubserving/ocr_system/module.py
index dff3abb48010946a9817b832383f1c95b7053970..192fff9650901df7889ae7b0620beea1d8b03e81 100644
--- a/deploy/hubserving/ocr_system/module.py
+++ b/deploy/hubserving/ocr_system/module.py
@@ -130,7 +130,7 @@ class OCRSystem(hub.Module):
rec_res_final.append({
'text': text,
'confidence': float(score),
- 'text_region': dt_boxes[dno].astype(np.int).tolist()
+ 'text_region': dt_boxes[dno].astype(np.int32).tolist()
})
all_results.append(rec_res_final)
return all_results
diff --git a/deploy/paddlejs/README.md b/deploy/paddlejs/README.md
index e80b7cce8249482f0e3e5ef06ed1e9e22b261644..eef39b6c9583e056c1413e335ed989dc957afa51 100644
--- a/deploy/paddlejs/README.md
+++ b/deploy/paddlejs/README.md
@@ -1,14 +1,26 @@
-English| [简体中文](README_ch.md)
+English| [简体中文](README_ch.md)
-# Paddle.js
+# Paddle.js Introduction
-[Paddle.js](https://github.com/PaddlePaddle/Paddle.js) is a web project for Baidu PaddlePaddle, which is an open source deep learning framework running in the browser. Paddle.js can either load a pre-trained model, or transforming a model from paddle-hub with model transforming tools provided by Paddle.js. It could run in every browser with WebGL/WebGPU/WebAssembly supported. It could also run in Baidu Smartprogram and WX miniprogram.
+[Paddle.js](https://github.com/PaddlePaddle/Paddle.js) is a web project for Baidu PaddlePaddle, which is an open source deep learning framework running in the browser. Paddle.js can either load a pre-trained model, or transforming a model from paddle-hub with model transforming tools provided by Paddle.js. It could run in every browser with WebGL/WebGPU/WebAssembly supported. It could also run in Baidu Smartprogram and wechat miniprogram.
+## Web Demo
+Run OCR demo in browser refer to [tutorial](https://github.com/PaddlePaddle/FastDeploy/blob/develop/examples/application/js/WebDemo.md).
-- [Online experience](https://paddlejs.baidu.com/ocr)
-- [Tutorial](https://github.com/PaddlePaddle/Paddle.js/blob/release/v2.2.3/packages/paddlejs-models/ocr/README_cn.md)
-- Visualization:
+|demo|web demo dicrctory|visualization|
+|-|-|-|
+|PP-OCRv3|[TextDetection、TextRecognition](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/src/pages/cv/ocr/)| |
+
+
+## Mini Program Demo
+The Mini Program demo running tutorial eference
+Run OCR demo in wechat miniprogram refer to [tutorial](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program).
+
+|demo|directory|
+|-|-|
+|Text Detection| [ocrdetecXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrdetectXcx/) |
+|Text Recognition| [ocrXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrXcx/) |
|
+
+
+## Mini Program Demo
+The Mini Program demo running tutorial eference
+Run OCR demo in wechat miniprogram refer to [tutorial](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program).
+
+|demo|directory|
+|-|-|
+|Text Detection| [ocrdetecXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrdetectXcx/) |
+|Text Recognition| [ocrXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrXcx/) |

-
\ No newline at end of file
+
diff --git a/deploy/paddlejs/README_ch.md b/deploy/paddlejs/README_ch.md
index 9e514df085b052e4163812d2b989bc27b15e2ba4..466661305962353e0fdb33ca9834d5880b21cf7a 100644
--- a/deploy/paddlejs/README_ch.md
+++ b/deploy/paddlejs/README_ch.md
@@ -5,10 +5,27 @@
[Paddle.js](https://github.com/PaddlePaddle/Paddle.js) 是百度 PaddlePaddle 的 web 方向子项目,是一个运行在浏览器中的开源深度学习框架。Paddle.js 可以加载提前训练好的 paddle 模型,通过 Paddle.js 的模型转换工具 paddlejs-converter 变成浏览器友好的模型进行在线推理预测使用。目前,Paddle.js 可以在支持 WebGL/WebGPU/WebAssembly 的浏览器中运行,也可以在百度小程序和微信小程序环境下运行。
-- [在线体验](https://paddlejs.baidu.com/ocr)
-- [直达教程](https://github.com/PaddlePaddle/Paddle.js/blob/release/v2.2.3/packages/paddlejs-models/ocr/README_cn.md)
+## Web Demo使用
+
+在浏览器中直接运行官方OCR demo参考[教程](https://github.com/PaddlePaddle/FastDeploy/blob/develop/examples/application/js/WebDemo.md)
+
+|demo名称|web demo目录|可视化|
+|-|-|-|
+|PP-OCRv3|[TextDetection、TextRecognition](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/src/pages/cv/ocr/)||
+
+
+## 微信小程序Demo使用
+
+在微信小程序运行官方demo参考[教程](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program)
+
+|名称|目录|
+|-|-|
+|OCR文本检测| [ocrdetecXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrdetectXcx/) |
+|OCR文本识别| [ocrXcx](https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/mini_program/ocrXcx/) |
+
+
- 效果:
-
-
 +
diff --git a/deploy/slim/prune/export_prune_model.py b/deploy/slim/prune/export_prune_model.py
index f4385972009e1b5382504754dc655381f0cc7717..b64b1d4c1e82b9d7db761aa65ba85f180f3299c6 100644
--- a/deploy/slim/prune/export_prune_model.py
+++ b/deploy/slim/prune/export_prune_model.py
@@ -25,7 +25,7 @@ sys.path.append(os.path.join(__dir__, '..', '..', '..'))
sys.path.append(os.path.join(__dir__, '..', '..', '..', 'tools'))
import paddle
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
@@ -39,6 +39,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
diff --git a/deploy/slim/prune/sensitivity_anal.py b/deploy/slim/prune/sensitivity_anal.py
index be64a6bcf860c3e2e7a8a6fa20c4c241149a147b..ded8ac04255a1c83f72a28ebba6e19c0387103ac 100644
--- a/deploy/slim/prune/sensitivity_anal.py
+++ b/deploy/slim/prune/sensitivity_anal.py
@@ -26,7 +26,7 @@ sys.path.append(os.path.join(__dir__, '..', '..', '..', 'tools'))
import paddle
import paddle.distributed as dist
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -57,6 +57,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
train_dataloader = build_dataloader(config, 'Train', device, logger)
if config['Eval']:
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
diff --git a/deploy/slim/quantization/README.md b/deploy/slim/quantization/README.md
index 7f1ff7ae22e78cded28f1689d66a5e41dd8950a2..d401d3ba0c8ba209994c43b72a7dbf240fe9dd3d 100644
--- a/deploy/slim/quantization/README.md
+++ b/deploy/slim/quantization/README.md
@@ -54,4 +54,7 @@ python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP
### 5. 量化模型部署
上述步骤导出的量化模型,参数精度仍然是FP32,但是参数的数值范围是int8,导出的模型可以通过PaddleLite的opt模型转换工具完成模型转换。
-量化模型部署的可参考 [移动端模型部署](../../lite/readme.md)
+
+量化模型移动端部署的可参考 [移动端模型部署](../../lite/readme.md)
+
+备注:量化训练后的模型参数是float32类型,转inference model预测时相对不量化无加速效果,原因是量化后模型结构之间存在量化和反量化算子,如果要使用量化模型部署,建议使用TensorRT并设置precision为INT8加速量化模型的预测时间。
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index bd132b625181cab853961efd2e2c38c411e9edf4..30696f3e3606da695156ecb3c7adbddf1a0071bb 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -34,7 +34,7 @@ from tools.program import load_config, merge_config, ArgsParser
from ppocr.metrics import build_metric
import tools.program as program
from paddleslim.dygraph.quant import QAT
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from tools.export_model import export_single_model
@@ -134,6 +134,7 @@ def main():
eval_class = build_metric(config['Metric'])
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
use_srn = config['Architecture']['algorithm'] == "SRN"
diff --git a/deploy/slim/quantization/quant.py b/deploy/slim/quantization/quant.py
index ef2c3e28f94e8b72d1aa7822fc88ecfd5c406b89..a580ce4346dab8c5593ed70f19114e33f9a7738b 100755
--- a/deploy/slim/quantization/quant.py
+++ b/deploy/slim/quantization/quant.py
@@ -31,7 +31,7 @@ import paddle.distributed as dist
paddle.seed(2)
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -95,6 +95,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
train_dataloader = build_dataloader(config, 'Train', device, logger)
if config['Eval']:
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
diff --git a/deploy/slim/quantization/quant_kl.py b/deploy/slim/quantization/quant_kl.py
index 73e1a957e8606fd7cc8269e96eec1e274484db06..fa2d16e8d3a167a87034d23bcd5794cb4acb8f84 100755
--- a/deploy/slim/quantization/quant_kl.py
+++ b/deploy/slim/quantization/quant_kl.py
@@ -31,7 +31,7 @@ import paddle.distributed as dist
paddle.seed(2)
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -117,6 +117,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
config['Train']['loader']['num_workers'] = 0
is_layoutxlm_ser = config['Architecture']['model_type'] =='kie' and config['Architecture']['Backbone']['name'] == 'LayoutXLMForSer'
train_dataloader = build_dataloader(config, 'Train', device, logger)
diff --git a/doc/doc_ch/PP-OCRv4_introduction.md b/doc/doc_ch/PP-OCRv4_introduction.md
new file mode 100644
index 0000000000000000000000000000000000000000..cf1ac63f864698c7b810b4efb91a3937f57de3e8
--- /dev/null
+++ b/doc/doc_ch/PP-OCRv4_introduction.md
@@ -0,0 +1,179 @@
+# PP-OCRv4
+
+- [1. 简介](#1)
+- [2. 检测优化](#2)
+- [3. 识别优化](#3)
+- [4. 端到端评估](#4)
+
+
+
+## 1. 简介
+
+PP-OCRv4在PP-OCRv3的基础上进一步升级。整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。 PP-OCRv4系统框图如下所示:
+
+
+
diff --git a/deploy/slim/prune/export_prune_model.py b/deploy/slim/prune/export_prune_model.py
index f4385972009e1b5382504754dc655381f0cc7717..b64b1d4c1e82b9d7db761aa65ba85f180f3299c6 100644
--- a/deploy/slim/prune/export_prune_model.py
+++ b/deploy/slim/prune/export_prune_model.py
@@ -25,7 +25,7 @@ sys.path.append(os.path.join(__dir__, '..', '..', '..'))
sys.path.append(os.path.join(__dir__, '..', '..', '..', 'tools'))
import paddle
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
@@ -39,6 +39,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
diff --git a/deploy/slim/prune/sensitivity_anal.py b/deploy/slim/prune/sensitivity_anal.py
index be64a6bcf860c3e2e7a8a6fa20c4c241149a147b..ded8ac04255a1c83f72a28ebba6e19c0387103ac 100644
--- a/deploy/slim/prune/sensitivity_anal.py
+++ b/deploy/slim/prune/sensitivity_anal.py
@@ -26,7 +26,7 @@ sys.path.append(os.path.join(__dir__, '..', '..', '..', 'tools'))
import paddle
import paddle.distributed as dist
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -57,6 +57,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
train_dataloader = build_dataloader(config, 'Train', device, logger)
if config['Eval']:
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
diff --git a/deploy/slim/quantization/README.md b/deploy/slim/quantization/README.md
index 7f1ff7ae22e78cded28f1689d66a5e41dd8950a2..d401d3ba0c8ba209994c43b72a7dbf240fe9dd3d 100644
--- a/deploy/slim/quantization/README.md
+++ b/deploy/slim/quantization/README.md
@@ -54,4 +54,7 @@ python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP
### 5. 量化模型部署
上述步骤导出的量化模型,参数精度仍然是FP32,但是参数的数值范围是int8,导出的模型可以通过PaddleLite的opt模型转换工具完成模型转换。
-量化模型部署的可参考 [移动端模型部署](../../lite/readme.md)
+
+量化模型移动端部署的可参考 [移动端模型部署](../../lite/readme.md)
+
+备注:量化训练后的模型参数是float32类型,转inference model预测时相对不量化无加速效果,原因是量化后模型结构之间存在量化和反量化算子,如果要使用量化模型部署,建议使用TensorRT并设置precision为INT8加速量化模型的预测时间。
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index bd132b625181cab853961efd2e2c38c411e9edf4..30696f3e3606da695156ecb3c7adbddf1a0071bb 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -34,7 +34,7 @@ from tools.program import load_config, merge_config, ArgsParser
from ppocr.metrics import build_metric
import tools.program as program
from paddleslim.dygraph.quant import QAT
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from tools.export_model import export_single_model
@@ -134,6 +134,7 @@ def main():
eval_class = build_metric(config['Metric'])
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
use_srn = config['Architecture']['algorithm'] == "SRN"
diff --git a/deploy/slim/quantization/quant.py b/deploy/slim/quantization/quant.py
index ef2c3e28f94e8b72d1aa7822fc88ecfd5c406b89..a580ce4346dab8c5593ed70f19114e33f9a7738b 100755
--- a/deploy/slim/quantization/quant.py
+++ b/deploy/slim/quantization/quant.py
@@ -31,7 +31,7 @@ import paddle.distributed as dist
paddle.seed(2)
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -95,6 +95,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
train_dataloader = build_dataloader(config, 'Train', device, logger)
if config['Eval']:
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
diff --git a/deploy/slim/quantization/quant_kl.py b/deploy/slim/quantization/quant_kl.py
index 73e1a957e8606fd7cc8269e96eec1e274484db06..fa2d16e8d3a167a87034d23bcd5794cb4acb8f84 100755
--- a/deploy/slim/quantization/quant_kl.py
+++ b/deploy/slim/quantization/quant_kl.py
@@ -31,7 +31,7 @@ import paddle.distributed as dist
paddle.seed(2)
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -117,6 +117,7 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
config['Train']['loader']['num_workers'] = 0
is_layoutxlm_ser = config['Architecture']['model_type'] =='kie' and config['Architecture']['Backbone']['name'] == 'LayoutXLMForSer'
train_dataloader = build_dataloader(config, 'Train', device, logger)
diff --git a/doc/doc_ch/PP-OCRv4_introduction.md b/doc/doc_ch/PP-OCRv4_introduction.md
new file mode 100644
index 0000000000000000000000000000000000000000..cf1ac63f864698c7b810b4efb91a3937f57de3e8
--- /dev/null
+++ b/doc/doc_ch/PP-OCRv4_introduction.md
@@ -0,0 +1,179 @@
+# PP-OCRv4
+
+- [1. 简介](#1)
+- [2. 检测优化](#2)
+- [3. 识别优化](#3)
+- [4. 端到端评估](#4)
+
+
+
+## 1. 简介
+
+PP-OCRv4在PP-OCRv3的基础上进一步升级。整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。 PP-OCRv4系统框图如下所示:
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
 +VI-LayoutXLM模型基于RE任务进行推理,可以执行如下命令:
+
+```bash
+cd ppstructure
+python3 kie/predict_kie_token_ser_re.py \
+ --kie_algorithm=LayoutXLM \
+ --re_model_dir=../inference/re_vi_layoutxlm \
+ --ser_model_dir=../inference/ser_vi_layoutxlm \
+ --use_visual_backbone=False \
+ --image_dir=./docs/kie/input/zh_val_42.jpg \
+ --ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --ocr_order_method="tb-yx"
+```
+
+RE可视化结果默认保存到`./output`文件夹里面,结果示例如下:
+
+
+VI-LayoutXLM模型基于RE任务进行推理,可以执行如下命令:
+
+```bash
+cd ppstructure
+python3 kie/predict_kie_token_ser_re.py \
+ --kie_algorithm=LayoutXLM \
+ --re_model_dir=../inference/re_vi_layoutxlm \
+ --ser_model_dir=../inference/ser_vi_layoutxlm \
+ --use_visual_backbone=False \
+ --image_dir=./docs/kie/input/zh_val_42.jpg \
+ --ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --ocr_order_method="tb-yx"
+```
+
+RE可视化结果默认保存到`./output`文件夹里面,结果示例如下:
+
+
+

+
', '', ...]}, # 表格的HTML字符串
+ 'structure': {'tokens': ['', '', '', ...]}, # 表格的HTML字符串
'cells': [
{
- 'tokens': ['P', 'a', 'd', 'd', 'l', 'e', 'P', 'a', 'd', 'd', 'l', 'e'], # 表格中的单个文本
- 'bbox': [x0, y0, x1, y1] # 表格中的单个文本的坐标
+ 'tokens': ['P', 'a', 'd', 'd', 'l', 'e', 'P', 'a', 'd', 'd', 'l', 'e'], # 表格中的单个文本
+ 'bbox': [x0, y0, x1, y1] # 表格中的单个文本的坐标
}
]
}
@@ -75,6 +79,10 @@ TableGeneration是一个开源表格数据集生成工具,其通过浏览器
|简单表格||
|彩色表格||
+## 1.4 数据标注
+
+数据标注可参考[PPOCRLabel](../../PPOCRLabel/README_ch.md)
+
# 2. 开始训练
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 [SLANet](../../configs/table/SLANet.yml) 模型训练PubTabNet英文数据集为例:
@@ -219,7 +227,39 @@ DCU设备上运行需要设置环境变量 `export HIP_VISIBLE_DEVICES=0,1,2,3`
## 2.7. 模型微调
-实际使用过程中,建议加载官方提供的预训练模型,在自己的数据集中进行微调,关于模型的微调方法,请参考:[模型微调教程](./finetune.md)。
+### 2.7.1 数据选择
+
+数据量:建议至少准备2000张的表格识别数据集用于模型微调。
+
+### 2.7.2 模型选择
+
+建议选择SLANet模型(配置文件:[SLANet_ch.yml](../../configs/table/SLANet_ch.yml),预训练模型:[ch_ppstructure_mobile_v2.0_SLANet_train.tar](https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_train.tar))进行微调,其精度与泛化性能是目前提供的最优中文表格预训练模型。
+
+更多表格识别模型,请参考[PP-Structure 系列模型库](../../ppstructure/docs/models_list.md)。
+
+### 2.7.3 训练超参选择
+
+在模型微调的时候,最重要的超参就是预训练模型路径`pretrained_model`, 学习率`learning_rate`,部分配置文件如下所示。
+
+```yaml
+Global:
+ pretrained_model: ./ch_ppstructure_mobile_v2.0_SLANet_train/best_accuracy.pdparams # 预训练模型路径
+Optimizer:
+ lr:
+ name: Cosine
+ learning_rate: 0.001 #
+ warmup_epoch: 0
+ regularizer:
+ name: 'L2'
+ factor: 0
+```
+
+上述配置文件中,首先需要将`pretrained_model`字段指定为`best_accuracy.pdparams`文件路径。
+
+PaddleOCR提供的配置文件是在4卡训练(相当于总的batch size是`4*48=192`)、且没有加载预训练模型情况下的配置文件,因此您的场景中,学习率与总的batch size需要对应线性调整,例如
+
+* 如果您的场景中是单卡训练,单卡batch_size=48,则总的batch_size=48,建议将学习率调整为`0.00025`左右。
+* 如果您的场景中是单卡训练,由于显存限制,只能设置单卡batch_size=32,则总的batch_size=32,建议将学习率调整为`0.00017`左右。
# 3. 模型评估与预测
diff --git a/doc/doc_ch/whl.md b/doc/doc_ch/whl.md
index 83f062801a343289f11681995549dded97982397..ba955c832bdeb8a686d70c089f6f8287c194aaef 100644
--- a/doc/doc_ch/whl.md
+++ b/doc/doc_ch/whl.md
@@ -294,7 +294,7 @@ paddleocr --image_dir PaddleOCR/doc/imgs_words/ch/word_1.jpg --use_angle_cls tru
## 3 自定义模型
-当内置模型无法满足需求时,需要使用到自己训练的模型。 首先,参照[inference.md](./inference.md) 第一节转换将检测、分类和识别模型转换为inference模型,然后按照如下方式使用
+当内置模型无法满足需求时,需要使用到自己训练的模型。 首先,参照[模型导出](./detection.md#4-模型导出与预测)将检测、分类和识别模型转换为inference模型,然后按照如下方式使用
### 3.1 代码使用
diff --git a/doc/doc_en/algorithm_det_east_en.md b/doc/doc_en/algorithm_det_east_en.md
index 3848464abfd275fd319a24b0d3f6b3522c06c4a2..85440debfabc9fc8edf9701ba991d173b9da58cb 100644
--- a/doc/doc_en/algorithm_det_east_en.md
+++ b/doc/doc_en/algorithm_det_east_en.md
@@ -26,8 +26,9 @@ On the ICDAR2015 dataset, the text detection result is as follows:
|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
| --- | --- | --- | --- | --- | --- | --- |
-|EAST|ResNet50_vd|88.71%| 81.36%| 84.88%| [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar)|
-|EAST| MobileNetV3| 78.20%| 79.10%| 78.65%| [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar)|
+|EAST|ResNet50_vd| [det_r50_vd_east.yml](../../configs/det/det_r50_vd_east.yml)|88.71%| 81.36%| 84.88%| [model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar)|
+|EAST|MobileNetV3|[det_mv3_east.yml](../../configs/det/det_mv3_east.yml) | 78.20%| 79.10%| 78.65%| [model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_east_v2.0_train.tar)|
+
diff --git a/doc/doc_en/algorithm_det_sast_en.md b/doc/doc_en/algorithm_det_sast_en.md
index e3437d22be9d75835aaa43e72363b498225db9e1..dde8eb32dc1d75270fa18155548a9fa6242c4215 100644
--- a/doc/doc_en/algorithm_det_sast_en.md
+++ b/doc/doc_en/algorithm_det_sast_en.md
@@ -74,10 +74,10 @@ First, convert the model saved in the SAST text detection training process into
python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
```
-For SAST curved text detection model inference, you need to set the parameter `--det_algorithm="SAST"` and `--det_sast_polygon=True`, run the following command:
+For SAST curved text detection model inference, you need to set the parameter `--det_algorithm="SAST"` and `--det_box_type=poly`, run the following command:
```
-python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_box_type='poly'
```
The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
diff --git a/doc/doc_en/algorithm_overview_en.md b/doc/doc_en/algorithm_overview_en.md
index 309d074ed4fc3cb39e53134d51a07fa07e1be621..2e25746dc071f25d4c17cabd6fb5fdcb85f4615d 100755
--- a/doc/doc_en/algorithm_overview_en.md
+++ b/doc/doc_en/algorithm_overview_en.md
@@ -3,6 +3,8 @@
- [1. Two-stage OCR Algorithms](#1)
- [1.1 Text Detection Algorithms](#11)
- [1.2 Text Recognition Algorithms](#12)
+ - [1.3 Text Super-Resolution Algorithms](#13)
+ - [1.4 Formula Recognition Algorithm](#14)
- [2. End-to-end OCR Algorithms](#2)
- [3. Table Recognition Algorithms](#3)
- [4. Key Information Extraction Algorithms](#4)
@@ -28,6 +30,7 @@ Supported text detection algorithms (Click the link to get the tutorial):
- [x] [PSENet](./algorithm_det_psenet_en.md)
- [x] [FCENet](./algorithm_det_fcenet_en.md)
- [x] [DRRG](./algorithm_det_drrg_en.md)
+- [x] [CT](./algorithm_det_ct_en.md)
On the ICDAR2015 dataset, the text detection result is as follows:
@@ -47,6 +50,7 @@ On Total-Text dataset, the text detection result is as follows:
|Model|Backbone|Precision|Recall|Hmean|Download link|
| --- | --- | --- | --- | --- | --- |
|SAST|ResNet50_vd|89.63%|78.44%|83.66%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+|CT|ResNet18_vd|88.68%|81.70%|85.05%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r18_ct_train.tar)|
On CTW1500 dataset, the text detection result is as follows:
@@ -104,6 +108,36 @@ Refer to [DTRB](https://arxiv.org/abs/1904.01906), the training and evaluation r
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | [trained model](https://paddleocr.bj.bcebos.com/contribution/rec_r31_robustscanner.tar)|
|RFL|ResNetRFL| 88.63% | rec_resnet_rfl_att | [trained model](https://paddleocr.bj.bcebos.com/contribution/rec_resnet_rfl_att_train.tar) |
+
+
+### 1.3 Text Super-Resolution Algorithms
+
+Supported text super-resolution algorithms (Click the link to get the tutorial):
+- [x] [Text Gestalt](./algorithm_sr_gestalt.md)
+- [x] [Text Telescope](./algorithm_sr_telescope.md)
+
+On the TextZoom public dataset, the effect of the algorithm is as follows:
+
+|Model|Backbone|PSNR_Avg|SSIM_Avg|Config|Download link|
+|---|---|---|---|---|---|
+|Text Gestalt|tsrn|19.28|0.6560| [configs/sr/sr_tsrn_transformer_strock.yml](../../configs/sr/sr_tsrn_transformer_strock.yml)|[trained model](https://paddleocr.bj.bcebos.com/sr_tsrn_transformer_strock_train.tar)|
+|Text Telescope|tbsrn|21.56|0.7411| [configs/sr/sr_telescope.yml](../../configs/sr/sr_telescope.yml)|[trained model](https://paddleocr.bj.bcebos.com/contribution/sr_telescope_train.tar)|
+
+
+
+### 1.4 Formula Recognition Algorithm
+
+Supported formula recognition algorithms (Click the link to get the tutorial):
+
+- [x] [CAN](./algorithm_rec_can_en.md)
+
+On the CROHME handwritten formula dataset, the effect of the algorithm is as follows:
+
+|Model |Backbone|Config|ExpRate|Download link|
+| ----- | ----- | ----- | ----- | ----- |
+|CAN|DenseNet|[rec_d28_can.yml](../../configs/rec/rec_d28_can.yml)|51.72%|[trained model](https://paddleocr.bj.bcebos.com/contribution/rec_d28_can_train.tar)|
+
+
## 2. End-to-end OCR Algorithms
@@ -122,7 +156,7 @@ On the PubTabNet dataset, the algorithm result is as follows:
|Model|Backbone|Config|Acc|Download link|
|---|---|---|---|---|
-|TableMaster|TableResNetExtra|[configs/table/table_master.yml](../../configs/table/table_master.yml)|77.47%|[trained](https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar) / [inference model](https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_infer.tar)|
+|TableMaster|TableResNetExtra|[configs/table/table_master.yml](../../configs/table/table_master.yml)|77.47%|[trained model](https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar) / [inference model](https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_infer.tar)|
diff --git a/doc/doc_en/algorithm_rec_svtr_en.md b/doc/doc_en/algorithm_rec_svtr_en.md
index 37cd35f35a2025cbb55ff85fe27b50e5d6e556aa..d22fe73e6fed1e30b4dc8317fb5fce69c4998a56 100644
--- a/doc/doc_en/algorithm_rec_svtr_en.md
+++ b/doc/doc_en/algorithm_rec_svtr_en.md
@@ -130,7 +130,23 @@ Not supported
## 5. FAQ
-1. Since most of the operators used by `SVTR` are matrix multiplication, in the GPU environment, the speed has an advantage, but in the environment where mkldnn is enabled on the CPU, `SVTR` has no advantage over the optimized convolutional network.
+- 1. Speed situation on CPU and GPU
+ - Since most of the operators used by `SVTR` are matrix multiplication, in the GPU environment, the speed has an advantage, but in the environment where mkldnn is enabled on the CPU, `SVTR` has no advantage over the optimized convolutional network.
+- 2. SVTR model convert to ONNX failed
+ - Ensure `paddle2onnx` and `onnxruntime` versions are up to date, refer to [SVTR model to onnx step-by-step example](https://github.com/PaddlePaddle/PaddleOCR/issues/7821#issuecomment-) for the convert onnx command. 1271214273).
+- 3. SVTR model convert to ONNX is successful but the inference result is incorrect
+ - The possible reason is that the model parameter `out_char_num` is not set correctly, it should be set to W//4, W//8 or W//12, please refer to [Section 3.3.3 of SVTR, a high-precision Chinese scene text recognition model](https://aistudio.baidu.com/aistudio/) projectdetail/5073182?contributionType=1).
+- 4. Optimization of long text recognition
+ - Refer to [Section 3.3 of SVTR, a high-precision Chinese scene text recognition model](https://aistudio.baidu.com/aistudio/projectdetail/5073182?contributionType=1).
+- 5. Notes on the reproduction of the paper results
+ - Dataset using provided by [ABINet](https://github.com/FangShancheng/ABINet).
+ - By default, 4 cards of GPUs are used for training, the default Batchsize of a single card is 512, and the total Batchsize is 2048, corresponding to a learning rate of 0.0005. When modifying the Batchsize or changing the number of GPU cards, the learning rate should be modified in equal proportion.
+- 6. Exploration Directions for further optimization
+ - Learning rate adjustment: adjusting to twice the default to keep Batchsize unchanged; or reducing Batchsize to 1/2 the default to keep the learning rate unchanged.
+ - Data augmentation strategies: optionally `RecConAug` and `RecAug`.
+ - If STN is not used, `Local` of `mixer` can be replaced by `Conv` and `local_mixer` can all be modified to `[5, 5]`.
+ - Grid search for optimal `embed_dim`, `depth`, `num_heads` configurations.
+ - Use the `Post-Normalization strategy`, which is to modify the model configuration `prenorm` to `True`.
## Citation
diff --git a/doc/doc_en/algorithm_sr_telescope_en.md b/doc/doc_en/algorithm_sr_telescope_en.md
index 9acb524312fc037bfc48b3c16e6f66024eb132b7..334b58b6e8238fe3b825f625527f6c84df94a510 100644
--- a/doc/doc_en/algorithm_sr_telescope_en.md
+++ b/doc/doc_en/algorithm_sr_telescope_en.md
@@ -27,7 +27,7 @@ Paper:
Referring to the [FudanOCR](https://github.com/FudanVI/FudanOCR/tree/main/scene-text-telescope) data download instructions, the effect of the super-score algorithm on the TextZoom test set is as follows:
|Model|Backbone|config|Acc|Download link|
-|---|---|---|---|---|---|
+|---|---|---|---|---|
|Text Gestalt|tsrn|21.56|0.7411| [configs/sr/sr_telescope.yml](../../configs/sr/sr_telescope.yml)|[train model](https://paddleocr.bj.bcebos.com/contribution/sr_telescope_train.tar)|
The [TextZoom dataset](https://paddleocr.bj.bcebos.com/dataset/TextZoom.tar) comes from two superfraction data sets, RealSR and SR-RAW, both of which contain LR-HR pairs. TextZoom has 17367 pairs of training data and 4373 pairs of test data.
diff --git a/doc/doc_en/detection_en.md b/doc/doc_en/detection_en.md
index c215e1a46636a84d372245097b460c095e9cb7fd..ab2e868c5401b8613425d09299b9473c79e3b819 100644
--- a/doc/doc_en/detection_en.md
+++ b/doc/doc_en/detection_en.md
@@ -13,6 +13,7 @@ This section uses the icdar2015 dataset as an example to introduce the training,
* [2.5 Distributed Training](#25-distributed-training)
* [2.6 Training with knowledge distillation](#26)
* [2.7 Training on other platform(Windows/macOS/Linux DCU)](#27)
+ * [2.8 Fine-tuning](#28)
- [3. Evaluation and Test](#3-evaluation-and-test)
- [3.1 Evaluation](#31-evaluation)
- [3.2 Test](#32-test)
@@ -178,6 +179,10 @@ GPU mode is not supported, you need to set `use_gpu` to False in the configurati
- Linux DCU
Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
+### 2.8 Fine-tuning
+
+In actual use, it is recommended to load the official pre-trained model and fine-tune it in your own data set. For the fine-tuning method of the detection model, please refer to: [Model Fine-tuning Tutorial](./finetune_en.md).
+
## 3. Evaluation and Test
### 3.1 Evaluation
diff --git a/doc/doc_en/finetune_en.md b/doc/doc_en/finetune_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e76eb1e26a257e41f16675988948f0ca178f8890
--- /dev/null
+++ b/doc/doc_en/finetune_en.md
@@ -0,0 +1,229 @@
+# Fine-tune
+
+## 1. background and meaning
+
+The PP-OCR series models provided by PaddleOCR have excellent performance in general scenarios and can solve detection and recognition problems in most cases. In vertical scenarios, if you want to obtain better model, you can further improve the accuracy of the PP-OCR series detection and recognition models through fine-tune.
+
+This article mainly introduces some precautions when fine-tuning the text detection and recognition model. Finally, you can obtain a text detection and recognition model with higher accuracy through model fine-tuning in your own scenarios.
+
+The core points of this article are as follows:
+
+1. The pre-trained model provided by PP-OCR has better generalization ability
+2. Adding a small amount of real data (detection:>=500, recognition:>=5000) will greatly improve the detection and recognition effect of vertical scenes
+3. When fine-tuning the model, adding real general scene data can further improve the model accuracy and generalization performance
+4. In the text detection task, increasing the prediction shape of the image can further improve the detection effect of the smaller text area
+5. When fine-tuning the model, it is necessary to properly adjust the hyperparameters (learning rate, batch size are the most important) to obtain a better fine-tuning effect.
+
+For more details, please refer to Chapter 2 and Chapter 3。
+
+## 2. Text detection model fine-tuning
+
+### 2.1 Dataset
+
+* Dataset: It is recommended to prepare at least 500 text detection datasets for model fine-tuning.
+
+* Dataset annotation: single-line text annotation format, it is recommended that the labeled detection frame be consistent with the actual semantic content. For example, in the train ticket scene, the surname and first name may be far apart, but they belong to the same detection field semantically. Here, the entire name also needs to be marked as a detection frame.
+
+### 2.2 Model
+
+It is recommended to choose the PP-OCRv3 model (configuration file: [ch_PP-OCRv3_det_student.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml),pre-trained model: [ch_PP-OCRv3_det_distill_train.tar](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar), its accuracy and generalization performance is the best pre-training model currently available.
+
+For more PP-OCR series models, please refer to [PP-OCR Series Model Library](./models_list_en.md)。
+
+Note: When using the above pre-trained model, you need to use the `student.pdparams` file in the folder as the pre-trained model, that is, only use the student model.
+
+
+### 2.3 Training hyperparameter
+
+When fine-tuning the model, the most important hyperparameter is the pre-training model path `pretrained_model`, `learning_rate`与`batch_size`,some hyperparameters are as follows:
+
+```yaml
+Global:
+ pretrained_model: ./ch_PP-OCRv3_det_distill_train/student.pdparams # pre-training model path
+Optimizer:
+ lr:
+ name: Cosine
+ learning_rate: 0.001 # learning_rate
+ warmup_epoch: 2
+ regularizer:
+ name: 'L2'
+ factor: 0
+
+Train:
+ loader:
+ shuffle: True
+ drop_last: False
+ batch_size_per_card: 8 # single gpu batch size
+ num_workers: 4
+```
+
+In the above configuration file, you need to specify the `pretrained_model` field as the `student.pdparams` file path.
+
+The configuration file provided by PaddleOCR is for 8-gpu training (equivalent to a total batch size of `8*8=64`) and no pre-trained model is loaded. Therefore, in your scenario, the learning rate is the same as the total The batch size needs to be adjusted linearly, for example
+
+* If your scenario is single-gpu training, single gpu batch_size=8, then the total batch_size=8, it is recommended to adjust the learning rate to about `1e-4`.
+* If your scenario is for single-gpu training, due to memory limitations, you can only set batch_size=4 for a single gpu, and the total batch_size=4. It is recommended to adjust the learning rate to about `5e-5`.
+
+### 2.4 Prediction hyperparameter
+
+When exporting and inferring the trained model, you can further adjust the predicted image scale to improve the detection effect of small-area text. The following are some hyperparameters during DBNet inference, which can be adjusted appropriately to improve the effect.
+
+| hyperparameter | type | default | meaning |
+| :--: | :--: | :--: | :--: |
+| det_db_thresh | float | 0.3 | In the probability map output by DB, pixels with a score greater than the threshold will be considered as text pixels |
+| det_db_box_thresh | float | 0.6 | When the average score of all pixels within the frame of the detection result is greater than the threshold, the result will be considered as a text area |
+| det_db_unclip_ratio | float | 1.5 | The expansion coefficient of `Vatti clipping`, using this method to expand the text area |
+| max_batch_size | int | 10 | batch size |
+| use_dilation | bool | False | Whether to expand the segmentation results to obtain better detection results |
+| det_db_score_mode | str | "fast" | DB's detection result score calculation method supports `fast` and `slow`. `fast` calculates the average score based on all pixels in the polygon’s circumscribed rectangle border, and `slow` calculates the average score based on all pixels in the original polygon. The calculation speed is relatively slower, but more accurate. |
+
+
+For more information on inference methods, please refer to[Paddle Inference doc](././inference_ppocr_en.md)。
+
+
+## 3. Text recognition model fine-tuning
+
+
+### 3.1 Dataset
+
+* Dataset:If the dictionary is not changed, it is recommended to prepare at least 5,000 text recognition datasets for model fine-tuning; if the dictionary is changed (not recommended), more quantities are required.
+
+* Data distribution: It is recommended that the distribution be as consistent as possible with the actual measurement scenario. If the actual scene contains a lot of short text, it is recommended to include more short text in the training data. If the actual scene has high requirements for the recognition effect of spaces, it is recommended to include more text content with spaces in the training data.
+
+* Data synthesis: In the case of some character recognition errors, it is recommended to obtain a batch of specific character dataset, add it to the original dataset and use a small learning rate for fine-tuning. The ratio of original dataset to new dataset can be 10:1 to 5:1 to avoid overfitting of the model caused by too much data in a single scene. At the same time, try to balance the word frequency of the corpus to ensure that the frequency of common words will not be too low.
+
+ Specific characters can be generated using the TextRenderer tool, for synthesis examples, please refer to [data synthesis](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/applications/%E5%85%89%E5%8A%9F%E7%8E%87%E8%AE%A1%E6%95%B0%E7%A0%81%E7%AE%A1%E5%AD%97%E7%AC%A6%E8%AF%86%E5%88%AB/%E5%85%89%E5%8A%9F%E7%8E%87%E8%AE%A1%E6%95%B0%E7%A0%81%E7%AE%A1%E5%AD%97%E7%AC%A6%E8%AF%86%E5%88%AB.md#31-%E6%95%B0%E6%8D%AE%E5%87%86%E5%A4%87)
+ . The synthetic data corpus should come from real usage scenarios as much as possible, and keep the richness of fonts and backgrounds on the basis of being close to the real scene, which will help improve the model effect.
+
+* Common Chinese and English data: During training, common real data can be added to the training set (for example, in the fine-tuning scenario without changing the dictionary, it is recommended to add real data such as LSVT, RCTW, MTWI) to further improve the generalization performance of the model.
+
+### 3.2 Model
+
+It is recommended to choose the PP-OCRv3 model (configuration file: [ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml),pre-trained model: [ch_PP-OCRv3_rec_train.tar](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar),its accuracy and generalization performance is the best pre-training model currently available.
+
+For more PP-OCR series models, please refer to [PP-OCR Series Model Library](./models_list_en.md)。
+
+The PP-OCRv3 model uses the GTC strategy. The SAR branch has a large number of parameters. When the training data is a simple scene, the model is easy to overfit, resulting in poor fine-tuning effect. It is recommended to remove the GTC strategy. The configuration file of the model structure is modified as follows:
+
+```yaml
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Neck:
+ name: SequenceEncoder
+ encoder_type: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: False
+ Head:
+ name: CTCHead
+ fc_decay: 0.00001
+Loss:
+ name: CTCLoss
+
+Train:
+ dataset:
+ ......
+ transforms:
+ # remove RecConAug
+ # - RecConAug:
+ # prob: 0.5
+ # ext_data_num: 2
+ # image_shape: [48, 320, 3]
+ # max_text_length: *max_text_length
+ - RecAug:
+ # modify Encode
+ - CTCLabelEncode:
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label
+ - length
+...
+
+Eval:
+ dataset:
+ ...
+ transforms:
+ ...
+ - CTCLabelEncode:
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label
+ - length
+...
+
+
+```
+
+### 3.3 Training hyperparameter
+
+Similar to text detection task fine-tuning, when fine-tuning the recognition model, the most important hyperparameters are the pre-trained model path `pretrained_model`, `learning_rate` and `batch_size`, some default configuration files are shown below.
+
+```yaml
+Global:
+ pretrained_model: # pre-training model path
+Optimizer:
+ lr:
+ name: Piecewise
+ decay_epochs : [700, 800]
+ values : [0.001, 0.0001] # learning_rate
+ warmup_epoch: 5
+ regularizer:
+ name: 'L2'
+ factor: 0
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ label_file_list:
+ - ./train_data/train_list.txt
+ ratio_list: [1.0] # Sampling ratio, the default value is [1.0]
+ loader:
+ shuffle: True
+ drop_last: False
+ batch_size_per_card: 128 # single gpu batch size
+ num_workers: 8
+
+```
+
+
+In the above configuration file, you first need to specify the `pretrained_model` field as the `ch_PP-OCRv3_rec_train/best_accuracy.pdparams` file path decompressed in Chapter 3.2.
+
+The configuration file provided by PaddleOCR is for 8-gpu training (equivalent to a total batch size of `8*128=1024`) and no pre-trained model is loaded. Therefore, in your scenario, the learning rate is the same as the total The batch size needs to be adjusted linearly, for example:
+
+* If your scenario is single-gpu training, single gpu batch_size=128, then the total batch_size=128, in the case of loading the pre-trained model, it is recommended to adjust the learning rate to about `[1e-4, 2e-5]` (For the piecewise learning rate strategy, two values need to be set, the same below).
+* If your scenario is for single-gpu training, due to memory limitations, you can only set batch_size=64 for a single gpu, and the total batch_size=64. When loading the pre-trained model, it is recommended to adjust the learning rate to `[5e-5 , 1e-5]`about.
+
+
+If there is general real scene data added, it is recommended that in each epoch, the amount of vertical scene data and real scene data should be kept at about 1:1.
+
+For example: your own vertical scene recognition data volume is 1W, the data label file is `vertical.txt`, the collected general scene recognition data volume is 10W, and the data label file is `general.txt`.
+
+Then, the `label_file_list` and `ratio_list` parameters can be set as shown below. In each epoch, `vertical.txt` will be fully sampled (sampling ratio is 1.0), including 1W pieces of data; `general.txt` will be sampled according to a sampling ratio of 0.1, including `10W*0.1=1W` pieces of data, the final ratio of the two is `1:1`.
+
+```yaml
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ label_file_list:
+ - vertical.txt
+ - general.txt
+ ratio_list: [1.0, 0.1]
+```
+
+### 3.4 training optimization
+
+The training process does not happen overnight. After completing a stage of training evaluation, it is recommended to collect and analyze the badcase of the current model in the real scene, adjust the proportion of training data in a targeted manner, or further add synthetic data. Through multiple iterations of training, the model effect is continuously optimized.
+
+If you modify the custom dictionary during training, since the parameters of the last layer of FC cannot be loaded, it is normal for acc=0 at the beginning of the iteration. Don't worry, loading the pre-trained model can still speed up the model convergence.
diff --git a/doc/doc_en/inference_args_en.md b/doc/doc_en/inference_args_en.md
index b28cd8436da62dcd10f96f17751db9384ebcaa8d..ee2faedf403a812f688532edcacdb4560027080b 100644
--- a/doc/doc_en/inference_args_en.md
+++ b/doc/doc_en/inference_args_en.md
@@ -1,6 +1,6 @@
# PaddleOCR Model Inference Parameter Explanation
-When using PaddleOCR for model inference, you can customize the modification parameters to modify the model, data, preprocessing, postprocessing, etc.(parameter file:[utility.py](../../tools/infer/utility.py)),The detailed parameter explanation is as follows:
+When using PaddleOCR for model inference, you can customize the modification parameters to modify the model, data, preprocessing, postprocessing, etc. (parameter file: [utility.py](../../tools/infer/utility.py)),The detailed parameter explanation is as follows:
* Global parameters
@@ -70,7 +70,7 @@ The relevant parameters of the SAST algorithm are as follows
| :--: | :--: | :--: | :--: |
| det_sast_score_thresh | float | 0.5 | Score thresholds in SAST postprocess |
| det_sast_nms_thresh | float | 0.5 | Thresholding of nms in SAST postprocess |
-| det_sast_polygon | bool | False | Whether polygon detection, curved text scene (such as Total-Text) is set to True |
+| det_box_type | str | 'quad' | Whether polygon detection, curved text scene (such as Total-Text) is set to 'poly' |
The relevant parameters of the PSE algorithm are as follows
@@ -79,7 +79,7 @@ The relevant parameters of the PSE algorithm are as follows
| det_pse_thresh | float | 0.0 | Threshold for binarizing the output image |
| det_pse_box_thresh | float | 0.85 | Threshold for filtering boxes, below this threshold is discarded |
| det_pse_min_area | float | 16 | The minimum area of the box, below this threshold is discarded |
-| det_pse_box_type | str | "box" | The type of the returned box, box: four point coordinates, poly: all point coordinates of the curved text |
+| det_box_type | str | "quad" | The type of the returned box, quad: four point coordinates, poly: all point coordinates of the curved text |
| det_pse_scale | int | 1 | The ratio of the input image relative to the post-processed image, such as an image of `640*640`, the network output is `160*160`, and when the scale is 2, the shape of the post-processed image is `320*320`. Increasing this value can speed up the post-processing speed, but it will bring about a decrease in accuracy |
* Text recognition model related parameters
@@ -88,7 +88,7 @@ The relevant parameters of the PSE algorithm are as follows
| :--: | :--: | :--: | :--: |
| rec_algorithm | str | "CRNN" | Text recognition algorithm name, currently supports `CRNN`, `SRN`, `RARE`, `NETR`, `SAR`, `ViTSTR`, `ABINet`, `VisionLAN`, `SPIN`, `RobustScanner`, `SVTR`, `SVTR_LCNet` |
| rec_model_dir | str | None, it is required if using the recognition model | recognition inference model paths |
-| rec_image_shape | list | [3, 48, 320] | Image size at the time of recognition |
+| rec_image_shape | str | "3,48,320" ] | Image size at the time of recognition |
| rec_batch_num | int | 6 | batch size |
| max_text_length | int | 25 | The maximum length of the recognition result, valid in `SRN` |
| rec_char_dict_path | str | "./ppocr/utils/ppocr_keys_v1.txt" | character dictionary file |
@@ -115,7 +115,16 @@ The relevant parameters of the PSE algorithm are as follows
| :--: | :--: | :--: | :--: |
| use_angle_cls | bool | False | whether to use an angle classifier |
| cls_model_dir | str | None, if you need to use, you must specify the path explicitly | angle classifier inference model path |
-| cls_image_shape | list | [3, 48, 192] | prediction shape |
+| cls_image_shape | str | "3,48,192" | prediction shape |
| label_list | list | ['0', '180'] | The angle value corresponding to the class id |
| cls_batch_num | int | 6 | batch size |
| cls_thresh | float | 0.9 | Prediction threshold, when the model prediction result is 180 degrees, and the score is greater than the threshold, the final prediction result is considered to be 180 degrees and needs to be flipped |
+
+
+* OCR image preprocessing parameters
+
+| parameters | type | default | implication |
+| :--: | :--: | :--: | :--: |
+| invert | bool | False | whether to invert image before processing |
+| binarize | bool | False | whether to threshold binarize image before processing |
+| alphacolor | tuple | "255,255,255" | Replacement color for the alpha channel, if the latter is present; R,G,B integers |
diff --git a/doc/doc_en/inference_en.md b/doc/doc_en/inference_en.md
index d1233780d89c175729e835d069db1bcc0bb9273f..95ac2c96bfdc84da53124c359e15c9b8f01a8ff2 100755
--- a/doc/doc_en/inference_en.md
+++ b/doc/doc_en/inference_en.md
@@ -10,30 +10,28 @@ For more details, please refer to the document [Classification Framework](https:
Next, we first introduce how to convert a trained model into an inference model, and then we will introduce text detection, text recognition, angle class, and the concatenation of them based on inference model.
-- [1. Convert Training Model to Inference Model](#CONVERT)
- - [1.1 Convert Detection Model to Inference Model](#Convert_detection_model)
- - [1.2 Convert Recognition Model to Inference Model](#Convert_recognition_model)
- - [1.3 Convert Angle Classification Model to Inference Model](#Convert_angle_class_model)
-
-
-- [2. Text Detection Model Inference](#DETECTION_MODEL_INFERENCE)
- - [2.1 Lightweight Chinese Detection Model Inference](#LIGHTWEIGHT_DETECTION)
- - [2.2 DB Text Detection Model Inference](#DB_DETECTION)
- - [2.3 East Text Detection Model Inference](#EAST_DETECTION)
- - [2.4 Sast Text Detection Model Inference](#SAST_DETECTION)
-
-- [3. Text Recognition Model Inference](#RECOGNITION_MODEL_INFERENCE)
- - [3.1 Lightweight Chinese Text Recognition Model Reference](#LIGHTWEIGHT_RECOGNITION)
- - [3.2 CTC-Based Text Recognition Model Inference](#CTC-BASED_RECOGNITION)
- - [3.3 SRN-Based Text Recognition Model Inference](#SRN-BASED_RECOGNITION)
- - [3.4 Text Recognition Model Inference Using Custom Characters Dictionary](#USING_CUSTOM_CHARACTERS)
- - [3.5 Multilingual Model Inference](#MULTILINGUAL_MODEL_INFERENCE)
-
-- [4. Angle Classification Model Inference](#ANGLE_CLASS_MODEL_INFERENCE)
-
-- [5. Text Detection Angle Classification And Recognition Inference Concatenation](#CONCATENATION)
- - [5.1 Lightweight Chinese Model](#LIGHTWEIGHT_CHINESE_MODEL)
- - [5.2 Other Models](#OTHER_MODELS)
+- [Inference Based on Python Prediction Engine](#inference-based-on-python-prediction-engine)
+ - [1. Convert Training Model to Inference Model](#1-convert-training-model-to-inference-model)
+ - [1.1 Convert Detection Model to Inference Model](#11-convert-detection-model-to-inference-model)
+ - [1.2 Convert Recognition Model to Inference Model](#12-convert-recognition-model-to-inference-model)
+ - [1.3 Convert Angle Classification Model to Inference Model](#13-convert-angle-classification-model-to-inference-model)
+ - [2. Text Detection Model Inference](#2-text-detection-model-inference)
+ - [2.1 Lightweight Chinese Detection Model Inference](#21-lightweight-chinese-detection-model-inference)
+ - [2.2 DB Text Detection Model Inference](#22-db-text-detection-model-inference)
+ - [2.3 EAST TEXT DETECTION MODEL INFERENCE](#23-east-text-detection-model-inference)
+ - [2.4 Sast Text Detection Model Inference](#24-sast-text-detection-model-inference)
+ - [(1). Quadrangle text detection model (ICDAR2015)](#1-quadrangle-text-detection-model-icdar2015)
+ - [(2). Curved text detection model (Total-Text)](#2-curved-text-detection-model-total-text)
+ - [3. Text Recognition Model Inference](#3-text-recognition-model-inference)
+ - [3.1 Lightweight Chinese Text Recognition Model Reference](#31-lightweight-chinese-text-recognition-model-reference)
+ - [3.2 CTC-Based Text Recognition Model Inference](#32-ctc-based-text-recognition-model-inference)
+ - [3.3 SRN-Based Text Recognition Model Inference](#33-srn-based-text-recognition-model-inference)
+ - [3.4 Text Recognition Model Inference Using Custom Characters Dictionary](#34-text-recognition-model-inference-using-custom-characters-dictionary)
+ - [3.5 Multilingual Model Inference](#35-multilingual-model-inference)
+ - [4. Angle Classification Model Inference](#4-angle-classification-model-inference)
+ - [5. Text Detection Angle Classification and Recognition Inference Concatenation](#5-text-detection-angle-classification-and-recognition-inference-concatenation)
+ - [5.1 Lightweight Chinese Model](#51-lightweight-chinese-model)
+ - [5.2 Other Models](#52-other-models)
## 1. Convert Training Model to Inference Model
@@ -371,7 +369,7 @@ After executing the command, the prediction results (classification angle and sc
### 5.1 Lightweight Chinese Model
-When performing prediction, you need to specify the path of a single image or a folder of images through the parameter `image_dir`, the parameter `det_model_dir` specifies the path to detect the inference model, the parameter `cls_model_dir` specifies the path to angle classification inference model and the parameter `rec_model_dir` specifies the path to identify the inference model. The parameter `use_angle_cls` is used to control whether to enable the angle classification model. The parameter `use_mp` specifies whether to use multi-process to infer `total_process_num` specifies process number when using multi-process. The parameter . The visualized recognition results are saved to the `./inference_results` folder by default.
+When performing prediction, you need to specify the path of a single image or a folder of images through the parameter `image_dir`, the parameter `det_model_dir` specifies the path to detect the inference model, the parameter `cls_model_dir` specifies the path to angle classification inference model and the parameter `rec_model_dir` specifies the path to identify the inference model. The parameter `use_angle_cls` is used to control whether to enable the angle classification model. The parameter `use_mp` specifies whether to use multi-process to infer `total_process_num` specifies process number when using multi-process. The parameter(Paddle Inference is not thread-safe, it is recommended to use multi-process) . The visualized recognition results are saved to the `./inference_results` folder by default.
```shell
# use direction classifier
diff --git a/doc/doc_en/kie_en.md b/doc/doc_en/kie_en.md
index 0c335a5ceb8991b80bc0cab6facdf402878abb50..cd1fffb27ac1c2a399a916e1ba5f5c3f87032515 100644
--- a/doc/doc_en/kie_en.md
+++ b/doc/doc_en/kie_en.md
@@ -457,14 +457,31 @@ inference/ser_vi_layoutxlm/
└── inference.pdmodel # The program file of recognition
```
-Export of RE model is also in adaptation.
+The RE model can be converted to the inference model using the following command.
+
+```bash
+# -c Set the training algorithm yml configuration file.
+# -o Set optional parameters.
+# Architecture.Backbone.checkpoints Set the training model address.
+# Global.save_inference_dir Set the address where the converted model will be saved.
+python3 tools/export_model.py -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./output/re_vi_layoutxlm_xfund_zh/best_accuracy Global.save_inference_dir=./inference/re_vi_layoutxlm
+```
+
+After the conversion is successful, there are three files in the model save directory:
+
+```
+inference/re_vi_layoutxlm/
+ ├── inference.pdiparams # The parameter file of recognition inference model
+ ├── inference.pdiparams.info # The parameter information of recognition inference model, which can be ignored
+ └── inference.pdmodel # The program file of recognition
+```
## 4.2 Model inference
The VI layoutxlm model performs reasoning based on the ser task, and can execute the following commands:
-Using the following command to infer the VI-LayoutXLM model.
+Using the following command to infer the VI-LayoutXLM SER model.
```bash
cd ppstructure
@@ -483,6 +500,26 @@ The visualized result will be saved in `./output`, which is shown as follows.
+Using the following command to infer the VI-LayoutXLM RE model.
+
+```bash
+cd ppstructure
+python3 kie/predict_kie_token_ser_re.py \
+ --kie_algorithm=LayoutXLM \
+ --re_model_dir=../inference/re_vi_layoutxlm \
+ --ser_model_dir=../inference/ser_vi_layoutxlm \
+ --use_visual_backbone=False \
+ --image_dir=./docs/kie/input/zh_val_42.jpg \
+ --ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --ocr_order_method="tb-yx"
+```
+
+The visualized result will be saved in `./output`, which is shown as follows.
+
+
+
+
+ 
+  +
+
diff --git a/doc/doc_en/quickstart_en.md b/doc/doc_en/quickstart_en.md
index ea38845f503192705a4d87f3faacdaf25bb27ba9..430f1a7a29ebeeb5401115a439c3a274e456e1d9 100644
--- a/doc/doc_en/quickstart_en.md
+++ b/doc/doc_en/quickstart_en.md
@@ -28,13 +28,13 @@
- If you have CUDA 9 or CUDA 10 installed on your machine, please run the following command to install
```bash
- python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
+ python -m pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
```
- If you have no available GPU on your machine, please run the following command to install the CPU version
```bash
- python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
```
For more software version requirements, please refer to the instructions in [Installation Document](https://www.paddlepaddle.org.cn/install/quick) for operation.
@@ -120,9 +120,10 @@ If you do not use the provided test image, you can replace the following `--imag
```
**Version**
-paddleocr uses the PP-OCRv3 model by default(`--ocr_version PP-OCRv3`). If you want to use other versions, you can set the parameter `--ocr_version`, the specific version description is as follows:
+paddleocr uses the PP-OCRv4 model by default(`--ocr_version PP-OCRv4`). If you want to use other versions, you can set the parameter `--ocr_version`, the specific version description is as follows:
| version name | description |
| --- | --- |
+| PP-OCRv4 | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
| PP-OCRv3 | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
| PP-OCRv2 | only supports Chinese and English detection and recognition, direction classifier, multilingual model is not updated |
| PP-OCR | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
@@ -223,7 +224,7 @@ from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan`
# to switch the language model in order.
-ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
+ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
img_path = './xxx.pdf'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
@@ -266,4 +267,4 @@ for idx in range(len(result)):
In this section, you have mastered the use of PaddleOCR whl package.
-PaddleOCR is a rich and practical OCR tool library that get through the whole process of data production, model training, compression, inference and deployment, please refer to the [tutorials](../../README.md#tutorials) to start the journey of PaddleOCR.
+PaddleX provides a high-quality ecological model of the paddle. It is a one-stop full-process high-efficiency development platform for training, pressing and pushing. Its mission is to help AI technology to be implemented quickly. The vision is to make everyone an AI Developer! Currently PP-OCRv4 has been launched on PaddleX, you can enter [General OCR](https://aistudio.baidu.com/aistudio/modelsdetail?modelId=286) to experience the whole process of model training, compression and inference deployment.
diff --git a/doc/doc_en/recognition_en.md b/doc/doc_en/recognition_en.md
index 7d31b0ffe28c59ad3397d06fa178bcf8cbb822e9..78917aea90c2082a5fcff8be1342b21bfb8e88d8 100644
--- a/doc/doc_en/recognition_en.md
+++ b/doc/doc_en/recognition_en.md
@@ -15,6 +15,7 @@
* [2.6 Training with knowledge distillation](#kd)
* [2.7 Multi-language Training](#Multi_language)
* [2.8 Training on other platform(Windows/macOS/Linux DCU)](#28)
+ * [2.9 Fine-tuning](#29)
- [3. Evaluation and Test](#3-evaluation-and-test)
* [3.1 Evaluation](#31-evaluation)
* [3.2 Test](#32-test)
@@ -384,6 +385,11 @@ GPU mode is not supported, you need to set `use_gpu` to False in the configurati
- Linux DCU
Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
+
+## 2.9 Fine-tuning
+
+In actual use, it is recommended to load the official pre-trained model and fine-tune it in your own data set. For the fine-tuning method of the recognition model, please refer to: [Model Fine-tuning Tutorial](./finetune_en.md).
+
## 3. Evaluation and Test
diff --git a/doc/doc_en/table_recognition_en.md b/doc/doc_en/table_recognition_en.md
index cff2933df22249353b47f5a0a74098be7dd6a2ae..c0a1aa9d61ebb00e4f7e013ee5feb59b1835c78c 100644
--- a/doc/doc_en/table_recognition_en.md
+++ b/doc/doc_en/table_recognition_en.md
@@ -6,6 +6,7 @@ This article provides a full-process guide for the PaddleOCR table recognition m
- [1.1. DataSet Format](#11-dataset-format)
- [1.2. Data Download](#12-data-download)
- [1.3. Dataset Generation](#13-dataset-generation)
+ - [1.4 Data annotation](#14-data-annotation)
- [2. Training](#2-training)
- [2.1. Start Training](#21-start-training)
- [2.2. Resume Training](#22-resume-training)
@@ -14,6 +15,9 @@ This article provides a full-process guide for the PaddleOCR table recognition m
- [2.5. Distributed Training](#25-distributed-training)
- [2.6. Training on other platform(Windows/macOS/Linux DCU)](#26-training-on-other-platformwindowsmacoslinux-dcu)
- [2.7. Fine-tuning](#27-fine-tuning)
+ - [2.7.1 Dataset](#271-dataset)
+ - [2.7.2 model selection](#272-model-selection)
+ - [2.7.3 Training hyperparameter selection](#273-training-hyperparameter-selection)
- [3. Evaluation and Test](#3-evaluation-and-test)
- [3.1. Evaluation](#31-evaluation)
- [3.2. Test table structure recognition effect](#32-test-table-structure-recognition-effect)
@@ -77,6 +81,10 @@ Some samples are as follows:
|Simple Table||
|Simple Color Table||
+## 1.4 Data annotation
+
+Data annotation can refer to[PPOCRLabel](../../PPOCRLabel/README.md)
+
# 2. Training
PaddleOCR provides training scripts, evaluation scripts, and prediction scripts. In this section, the [SLANet](../../configs/table/SLANet.yml) model will be used as an example:
@@ -226,8 +234,40 @@ Running on a DCU device requires setting the environment variable `export HIP_VI
## 2.7. Fine-tuning
-In the actual use process, it is recommended to load the officially provided pre-training model and fine-tune it in your own data set. For the fine-tuning method of the table recognition model, please refer to: [Model fine-tuning tutorial](./finetune.md).
+### 2.7.1 Dataset
+
+Data number: It is recommended to prepare at least 2000 table recognition datasets for model fine-tuning.
+
+### 2.7.2 model selection
+
+It is recommended to choose the SLANet model (configuration file: [SLANet_ch.yml](../../configs/table/SLANet_ch.yml), pre-training model: [ch_ppstructure_mobile_v2.0_SLANet_train.tar](https://paddleocr.bj.bcebos .com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_train.tar)) for fine-tuning, its accuracy and generalization performance is the best Chinese table pre-training model currently available.
+
+For more table recognition models, please refer to [PP-Structure Series Model Library](../../ppstructure/docs/models_list.md).
+
+### 2.7.3 Training hyperparameter selection
+
+When fine-tuning the model, the most important hyperparameters are the pretrained model path `pretrained_model`, the learning rate `learning_rate`, and some configuration files are shown below.
+
+```yaml
+Global:
+ pretrained_model: ./ch_ppstructure_mobile_v2.0_SLANet_train/best_accuracy.pdparams # Pre-trained model path
+Optimizer:
+ lr:
+ name: Cosine
+ learning_rate: 0.001 #
+ warmup_epoch: 0
+ regularizer:
+ name: 'L2'
+ factor: 0
+```
+
+In the above configuration file, you first need to specify the `pretrained_model` field as the `best_accuracy.pdparams` file path.
+
+The configuration file provided by PaddleOCR is for 4-card training (equivalent to a total batch size of `4*48=192`) and no pre-trained model is loaded. Therefore, in your scenario, the learning rate is the same as the total The batch size needs to be adjusted linearly, for example
+
+* If your scenario is single card training, single card batch_size=48, then the total batch_size=48, it is recommended to adjust the learning rate to about `0.00025`.
+* If your scenario is for single-card training, due to memory limitations, you can only set batch_size=32 for a single card, then the total batch_size=32, it is recommended to adjust the learning rate to about `0.00017`.
# 3. Evaluation and Test
diff --git a/doc/doc_en/whl_en.md b/doc/doc_en/whl_en.md
index 77e80faa688392db5b2959f4fd1705275cb37d6b..5283391e5ef8b35eb56f0355fd70049f40a4ae04 100644
--- a/doc/doc_en/whl_en.md
+++ b/doc/doc_en/whl_en.md
@@ -261,7 +261,7 @@ Output will be a list, each item contains classification result and confidence
## 3 Use custom model
When the built-in model cannot meet the needs, you need to use your own trained model.
-First, refer to the first section of [inference_en.md](./inference_en.md) to convert your det and rec model to inference model, and then use it as follows
+First, refer to [export](./detection_en.md#4-inference) doc to convert your det and rec model to inference model, and then use it as follows
### 3.1 Use by code
@@ -335,7 +335,7 @@ ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to downlo
img_path = 'PaddleOCR/doc/imgs/11.jpg'
img = cv2.imread(img_path)
# img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY), If your own training model supports grayscale images, you can uncomment this line
-result = ocr.ocr(img_path, cls=True)
+result = ocr.ocr(img, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
diff --git a/doc/joinus.PNG b/doc/joinus.PNG
index 6489247e05d70896e2ca8a5929948437c6c82b5f..aef92ec8d1f61f6fa8766e8e7a9e56993a3e6f13 100644
Binary files a/doc/joinus.PNG and b/doc/joinus.PNG differ
diff --git a/doc/joinus_paddlex.jpg b/doc/joinus_paddlex.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6b70dda865534210d35caa16497d49328d6dd25b
Binary files /dev/null and b/doc/joinus_paddlex.jpg differ
diff --git a/doc/ppocr_v4/DF.png b/doc/ppocr_v4/DF.png
new file mode 100644
index 0000000000000000000000000000000000000000..f14953d4811adb4d77fe020eaaa325c89dffc4ce
Binary files /dev/null and b/doc/ppocr_v4/DF.png differ
diff --git a/doc/ppocr_v4/PFHead.png b/doc/ppocr_v4/PFHead.png
new file mode 100644
index 0000000000000000000000000000000000000000..3728dc44e5c86c0ba80705ad83ada65da390928d
Binary files /dev/null and b/doc/ppocr_v4/PFHead.png differ
diff --git a/doc/ppocr_v4/multi_scale.png b/doc/ppocr_v4/multi_scale.png
new file mode 100644
index 0000000000000000000000000000000000000000..673d306399db004cbb66474368ac5055e48dbe8f
Binary files /dev/null and b/doc/ppocr_v4/multi_scale.png differ
diff --git a/doc/ppocr_v4/ppocrv4_det_cml.png b/doc/ppocr_v4/ppocrv4_det_cml.png
new file mode 100644
index 0000000000000000000000000000000000000000..9132c0a67c4215cfe19af27628ee37cfbab44720
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_det_cml.png differ
diff --git a/doc/ppocr_v4/ppocrv4_framework.png b/doc/ppocr_v4/ppocrv4_framework.png
new file mode 100644
index 0000000000000000000000000000000000000000..4aac40bae8e67b0b4964ddd4e84445845049bbad
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_framework.png differ
diff --git a/doc/ppocr_v4/ppocrv4_gtc.png b/doc/ppocr_v4/ppocrv4_gtc.png
new file mode 100644
index 0000000000000000000000000000000000000000..7e6a3f5c13ca4c3012d0dd98ba857153c75e607a
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_gtc.png differ
diff --git a/doc/ppocr_v4/v4_rec_pipeline.png b/doc/ppocr_v4/v4_rec_pipeline.png
new file mode 100644
index 0000000000000000000000000000000000000000..b1ec7a96892c6fa992c79531da4979164027b99c
Binary files /dev/null and b/doc/ppocr_v4/v4_rec_pipeline.png differ
diff --git a/paddleocr.py b/paddleocr.py
index af0145b48b7d8a8e6860cfb69e36b7a973a1149c..dc92cbf6b7c1789af629ba764ad1c0c12b936e4c 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -26,37 +26,133 @@ import cv2
import logging
import numpy as np
from pathlib import Path
+import base64
+from io import BytesIO
+from PIL import Image
-tools = importlib.import_module('.', 'tools')
-ppocr = importlib.import_module('.', 'ppocr')
-ppstructure = importlib.import_module('.', 'ppstructure')
-from tools.infer import predict_system
-from ppocr.utils.logging import get_logger
+def _import_file(module_name, file_path, make_importable=False):
+ spec = importlib.util.spec_from_file_location(module_name, file_path)
+ module = importlib.util.module_from_spec(spec)
+ spec.loader.exec_module(module)
+ if make_importable:
+ sys.modules[module_name] = module
+ return module
-logger = get_logger()
-from ppocr.utils.utility import check_and_read, get_image_file_list
+
+tools = _import_file(
+ 'tools', os.path.join(__dir__, 'tools/__init__.py'), make_importable=True)
+ppocr = importlib.import_module('ppocr', 'paddleocr')
+ppstructure = importlib.import_module('ppstructure', 'paddleocr')
+from ppocr.utils.logging import get_logger
+from tools.infer import predict_system
+from ppocr.utils.utility import check_and_read, get_image_file_list, alpha_to_color, binarize_img
from ppocr.utils.network import maybe_download, download_with_progressbar, is_link, confirm_model_dir_url
from tools.infer.utility import draw_ocr, str2bool, check_gpu
from ppstructure.utility import init_args, draw_structure_result
from ppstructure.predict_system import StructureSystem, save_structure_res, to_excel
+logger = get_logger()
__all__ = [
'PaddleOCR', 'PPStructure', 'draw_ocr', 'draw_structure_result',
'save_structure_res', 'download_with_progressbar', 'to_excel'
]
SUPPORT_DET_MODEL = ['DB']
-VERSION = '2.6.1.0'
+VERSION = '2.7.0.2'
SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
-DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
-SUPPORT_OCR_MODEL_VERSION = ['PP-OCR', 'PP-OCRv2', 'PP-OCRv3']
+DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv4'
+SUPPORT_OCR_MODEL_VERSION = ['PP-OCR', 'PP-OCRv2', 'PP-OCRv3', 'PP-OCRv4']
DEFAULT_STRUCTURE_MODEL_VERSION = 'PP-StructureV2'
SUPPORT_STRUCTURE_MODEL_VERSION = ['PP-Structure', 'PP-StructureV2']
MODEL_URLS = {
'OCR': {
+ 'PP-OCRv4': {
+ 'det': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar',
+ },
+ 'en': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar',
+ },
+ 'ml': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar'
+ }
+ },
+ 'rec': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/ppocr_keys_v1.txt'
+ },
+ 'en': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/english/en_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/en_dict.txt'
+ },
+ 'korean': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/korean_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/korean_dict.txt'
+ },
+ 'japan': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/japan_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/japan_dict.txt'
+ },
+ 'chinese_cht': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/chinese_cht_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/chinese_cht_dict.txt'
+ },
+ 'ta': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/ta_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/ta_dict.txt'
+ },
+ 'te': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/te_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/te_dict.txt'
+ },
+ 'ka': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/ka_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/ka_dict.txt'
+ },
+ 'latin': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/latin_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/latin_dict.txt'
+ },
+ 'arabic': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/arabic_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/arabic_dict.txt'
+ },
+ 'cyrillic': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/cyrillic_dict.txt'
+ },
+ 'devanagari': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/devanagari_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/devanagari_dict.txt'
+ },
+ },
+ 'cls': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar',
+ }
+ },
+ },
'PP-OCRv3': {
'det': {
'ch': {
@@ -312,13 +408,14 @@ def parse_args(mMain=True):
parser.add_argument("--det", type=str2bool, default=True)
parser.add_argument("--rec", type=str2bool, default=True)
parser.add_argument("--type", type=str, default='ocr')
+ parser.add_argument("--savefile", type=str2bool, default=False)
parser.add_argument(
"--ocr_version",
type=str,
choices=SUPPORT_OCR_MODEL_VERSION,
- default='PP-OCRv3',
+ default='PP-OCRv4',
help='OCR Model version, the current model support list is as follows: '
- '1. PP-OCRv3 Support Chinese and English detection and recognition model, and direction classifier model'
+ '1. PP-OCRv4/v3 Support Chinese and English detection and recognition model, and direction classifier model'
'2. PP-OCRv2 Support Chinese detection and recognition model. '
'3. PP-OCR support Chinese detection, recognition and direction classifier and multilingual recognition model.'
)
@@ -416,7 +513,7 @@ def get_model_config(type, version, model_type, lang):
def img_decode(content: bytes):
np_arr = np.frombuffer(content, dtype=np.uint8)
- return cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
+ return cv2.imdecode(np_arr, cv2.IMREAD_UNCHANGED)
def check_img(img):
@@ -431,7 +528,25 @@ def check_img(img):
img, flag_gif, flag_pdf = check_and_read(image_file)
if not flag_gif and not flag_pdf:
with open(image_file, 'rb') as f:
- img = img_decode(f.read())
+ img_str = f.read()
+ img = img_decode(img_str)
+ if img is None:
+ try:
+ buf = BytesIO()
+ image = BytesIO(img_str)
+ im = Image.open(image)
+ rgb = im.convert('RGB')
+ rgb.save(buf, 'jpeg')
+ buf.seek(0)
+ image_bytes = buf.read()
+ data_base64 = str(base64.b64encode(image_bytes),
+ encoding="utf-8")
+ image_decode = base64.b64decode(data_base64)
+ img_array = np.frombuffer(image_decode, np.uint8)
+ img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
+ except:
+ logger.error("error in loading image:{}".format(image_file))
+ return None
if img is None:
logger.error("error in loading image:{}".format(image_file))
return None
@@ -476,7 +591,7 @@ class PaddleOCR(predict_system.TextSystem):
params.cls_model_dir, cls_url = confirm_model_dir_url(
params.cls_model_dir,
os.path.join(BASE_DIR, 'whl', 'cls'), cls_model_config['url'])
- if params.ocr_version == 'PP-OCRv3':
+ if params.ocr_version in ['PP-OCRv3', 'PP-OCRv4']:
params.rec_image_shape = "3, 48, 320"
else:
params.rec_image_shape = "3, 32, 320"
@@ -502,14 +617,17 @@ class PaddleOCR(predict_system.TextSystem):
super().__init__(params)
self.page_num = params.page_num
- def ocr(self, img, det=True, rec=True, cls=True):
+ def ocr(self, img, det=True, rec=True, cls=True, bin=False, inv=False, alpha_color=(255, 255, 255)):
"""
- ocr with paddleocr
- args:
- img: img for ocr, support ndarray, img_path and list or ndarray
- det: use text detection or not. If false, only rec will be exec. Default is True
- rec: use text recognition or not. If false, only det will be exec. Default is True
- cls: use angle classifier or not. Default is True. If true, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
+ OCR with PaddleOCR
+ args:
+ img: img for OCR, support ndarray, img_path and list or ndarray
+ det: use text detection or not. If False, only rec will be exec. Default is True
+ rec: use text recognition or not. If False, only det will be exec. Default is True
+ cls: use angle classifier or not. Default is True. If True, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
+ bin: binarize image to black and white. Default is False.
+ inv: invert image colors. Default is False.
+ alpha_color: set RGB color Tuple for transparent parts replacement. Default is pure white.
"""
assert isinstance(img, (np.ndarray, list, str, bytes))
if isinstance(img, list) and det == True:
@@ -517,7 +635,7 @@ class PaddleOCR(predict_system.TextSystem):
exit(0)
if cls == True and self.use_angle_cls == False:
logger.warning(
- 'Since the angle classifier is not initialized, the angle classifier will not be uesd during the forward process'
+ 'Since the angle classifier is not initialized, it will not be used during the forward process'
)
img = check_img(img)
@@ -528,10 +646,23 @@ class PaddleOCR(predict_system.TextSystem):
imgs = img[:self.page_num]
else:
imgs = [img]
+
+ def preprocess_image(_image):
+ _image = alpha_to_color(_image, alpha_color)
+ if inv:
+ _image = cv2.bitwise_not(_image)
+ if bin:
+ _image = binarize_img(_image)
+ return _image
+
if det and rec:
ocr_res = []
for idx, img in enumerate(imgs):
+ img = preprocess_image(img)
dt_boxes, rec_res, _ = self.__call__(img, cls)
+ if not dt_boxes and not rec_res:
+ ocr_res.append(None)
+ continue
tmp_res = [[box.tolist(), res]
for box, res in zip(dt_boxes, rec_res)]
ocr_res.append(tmp_res)
@@ -539,7 +670,11 @@ class PaddleOCR(predict_system.TextSystem):
elif det and not rec:
ocr_res = []
for idx, img in enumerate(imgs):
+ img = preprocess_image(img)
dt_boxes, elapse = self.text_detector(img)
+ if not dt_boxes:
+ ocr_res.append(None)
+ continue
tmp_res = [box.tolist() for box in dt_boxes]
ocr_res.append(tmp_res)
return ocr_res
@@ -548,6 +683,7 @@ class PaddleOCR(predict_system.TextSystem):
cls_res = []
for idx, img in enumerate(imgs):
if not isinstance(img, list):
+ img = preprocess_image(img)
img = [img]
if self.use_angle_cls and cls:
img, cls_res_tmp, elapse = self.text_classifier(img)
@@ -649,15 +785,35 @@ def main():
img_name = os.path.basename(img_path).split('.')[0]
logger.info('{}{}{}'.format('*' * 10, img_path, '*' * 10))
if args.type == 'ocr':
- result = engine.ocr(img_path,
- det=args.det,
- rec=args.rec,
- cls=args.use_angle_cls)
+ result = engine.ocr(
+ img_path,
+ det=args.det,
+ rec=args.rec,
+ cls=args.use_angle_cls,
+ bin=args.binarize,
+ inv=args.invert,
+ alpha_color=args.alphacolor
+ )
if result is not None:
+ lines = []
for idx in range(len(result)):
res = result[idx]
for line in res:
logger.info(line)
+ val = '['
+ for box in line[0]:
+ val += str(box[0]) + ',' + str(box[1]) + ','
+
+ val = val[:-1]
+ val += '],' + line[1][0] + ',' + str(line[1][1]) + '\n'
+ lines.append(val)
+ if args.savefile:
+ if os.path.exists(args.output) is False:
+ os.mkdir(args.output)
+ outfile = args.output + '/' + img_name + '.txt'
+ with open(outfile,'w',encoding='utf-8') as f:
+ f.writelines(lines)
+
elif args.type == 'structure':
img, flag_gif, flag_pdf = check_and_read(img_path)
if not flag_gif and not flag_pdf:
@@ -694,7 +850,7 @@ def main():
logger.info('processing {}/{} page:'.format(index + 1,
len(img_paths)))
new_img_name = os.path.basename(new_img_path).split('.')[0]
- result = engine(new_img_path, img_idx=index)
+ result = engine(img, img_idx=index)
save_structure_res(result, args.output, img_name, index)
if args.recovery and result != []:
diff --git a/ppocr/data/__init__.py b/ppocr/data/__init__.py
index b602a346dbe4b0d45af287f25f05ead0f62daf44..48cd8ad8c5ccef9b0dd3c9a0c66eb028a70c8334 100644
--- a/ppocr/data/__init__.py
+++ b/ppocr/data/__init__.py
@@ -33,12 +33,22 @@ from paddle.io import Dataset, DataLoader, BatchSampler, DistributedBatchSampler
import paddle.distributed as dist
from ppocr.data.imaug import transform, create_operators
-from ppocr.data.simple_dataset import SimpleDataSet
-from ppocr.data.lmdb_dataset import LMDBDataSet, LMDBDataSetSR
+from ppocr.data.simple_dataset import SimpleDataSet, MultiScaleDataSet
+from ppocr.data.lmdb_dataset import LMDBDataSet, LMDBDataSetSR, LMDBDataSetTableMaster
from ppocr.data.pgnet_dataset import PGDataSet
from ppocr.data.pubtab_dataset import PubTabDataSet
+from ppocr.data.multi_scale_sampler import MultiScaleSampler
-__all__ = ['build_dataloader', 'transform', 'create_operators']
+# for PaddleX dataset_type
+TextDetDataset = SimpleDataSet
+TextRecDataset = SimpleDataSet
+MSTextRecDataset = MultiScaleDataSet
+PubTabTableRecDataset = PubTabDataSet
+KieDataset = SimpleDataSet
+
+__all__ = [
+ 'build_dataloader', 'transform', 'create_operators', 'set_signal_handlers'
+]
def term_mp(sig_num, frame):
@@ -50,12 +60,43 @@ def term_mp(sig_num, frame):
os.killpg(pgid, signal.SIGKILL)
+def set_signal_handlers():
+ pid = os.getpid()
+ try:
+ pgid = os.getpgid(pid)
+ except AttributeError:
+ # In case `os.getpgid` is not available, no signal handler will be set,
+ # because we cannot do safe cleanup.
+ pass
+ else:
+ # XXX: `term_mp` kills all processes in the process group, which in
+ # some cases includes the parent process of current process and may
+ # cause unexpected results. To solve this problem, we set signal
+ # handlers only when current process is the group leader. In the
+ # future, it would be better to consider killing only descendants of
+ # the current process.
+ if pid == pgid:
+ # support exit using ctrl+c
+ signal.signal(signal.SIGINT, term_mp)
+ signal.signal(signal.SIGTERM, term_mp)
+
+
def build_dataloader(config, mode, device, logger, seed=None):
config = copy.deepcopy(config)
support_dict = [
- 'SimpleDataSet', 'LMDBDataSet', 'PGDataSet', 'PubTabDataSet',
- 'LMDBDataSetSR'
+ 'SimpleDataSet',
+ 'LMDBDataSet',
+ 'PGDataSet',
+ 'PubTabDataSet',
+ 'LMDBDataSetSR',
+ 'LMDBDataSetTableMaster',
+ 'MultiScaleDataSet',
+ 'TextDetDataset',
+ 'TextRecDataset',
+ 'MSTextRecDataset',
+ 'PubTabTableRecDataset',
+ 'KieDataset',
]
module_name = config[mode]['dataset']['name']
assert module_name in support_dict, Exception(
@@ -76,11 +117,16 @@ def build_dataloader(config, mode, device, logger, seed=None):
if mode == "Train":
# Distribute data to multiple cards
- batch_sampler = DistributedBatchSampler(
- dataset=dataset,
- batch_size=batch_size,
- shuffle=shuffle,
- drop_last=drop_last)
+ if 'sampler' in config[mode]:
+ config_sampler = config[mode]['sampler']
+ sampler_name = config_sampler.pop("name")
+ batch_sampler = eval(sampler_name)(dataset, **config_sampler)
+ else:
+ batch_sampler = DistributedBatchSampler(
+ dataset=dataset,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ drop_last=drop_last)
else:
# Distribute data to single card
batch_sampler = BatchSampler(
@@ -103,8 +149,4 @@ def build_dataloader(config, mode, device, logger, seed=None):
use_shared_memory=use_shared_memory,
collate_fn=collate_fn)
- # support exit using ctrl+c
- signal.signal(signal.SIGINT, term_mp)
- signal.signal(signal.SIGTERM, term_mp)
-
return data_loader
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 93d97446d44070b9c10064fbe10b0b5e05628a6a..121582b4908750fca6612dc592a3671ef4dcb328 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -27,7 +27,7 @@ from .make_pse_gt import MakePseGt
from .rec_img_aug import BaseDataAugmentation, RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
SRNRecResizeImg, GrayRecResizeImg, SARRecResizeImg, PRENResizeImg, \
ABINetRecResizeImg, SVTRRecResizeImg, ABINetRecAug, VLRecResizeImg, SPINRecResizeImg, RobustScannerRecResizeImg, \
- RFLRecResizeImg
+ RFLRecResizeImg, SVTRRecAug
from .ssl_img_aug import SSLRotateResize
from .randaugment import RandAugment
from .copy_paste import CopyPaste
diff --git a/ppocr/data/imaug/abinet_aug.py b/ppocr/data/imaug/abinet_aug.py
index eefdc75d5a5c0ac3f7136bf22a2adb31129bd313..bcbdadb1bae06d0a58de4743df9ce0d8c15fcfa1 100644
--- a/ppocr/data/imaug/abinet_aug.py
+++ b/ppocr/data/imaug/abinet_aug.py
@@ -205,7 +205,7 @@ class CVRandomAffine(object):
for x, y in startpoints]
rect = cv2.minAreaRect(np.array(endpoints))
- bbox = cv2.boxPoints(rect).astype(dtype=np.int)
+ bbox = cv2.boxPoints(rect).astype(dtype=np.int32)
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
@@ -234,9 +234,9 @@ class CVRandomPerspective(object):
def get_params(self, width, height, distortion):
offset_h = sample_asym(
- distortion * height / 2, size=4).astype(dtype=np.int)
+ distortion * height / 2, size=4).astype(dtype=np.int32)
offset_w = sample_asym(
- distortion * width / 2, size=4).astype(dtype=np.int)
+ distortion * width / 2, size=4).astype(dtype=np.int32)
topleft = (offset_w[0], offset_h[0])
topright = (width - 1 - offset_w[1], offset_h[1])
botright = (width - 1 - offset_w[2], height - 1 - offset_h[2])
@@ -256,7 +256,7 @@ class CVRandomPerspective(object):
# TODO: more robust way to crop image
rect = cv2.minAreaRect(endpoints)
- bbox = cv2.boxPoints(rect).astype(dtype=np.int)
+ bbox = cv2.boxPoints(rect).astype(dtype=np.int32)
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
min_x, min_y = max(min_x, 0), max(min_y, 0)
@@ -405,3 +405,55 @@ class CVColorJitter(object):
def __call__(self, img):
if random.random() < self.p: return self.transforms(img)
else: return img
+
+
+class SVTRDeterioration(object):
+ def __init__(self, var, degrees, factor, p=0.5):
+ self.p = p
+ transforms = []
+ if var is not None:
+ transforms.append(CVGaussianNoise(var=var))
+ if degrees is not None:
+ transforms.append(CVMotionBlur(degrees=degrees))
+ if factor is not None:
+ transforms.append(CVRescale(factor=factor))
+ self.transforms = transforms
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ random.shuffle(self.transforms)
+ transforms = Compose(self.transforms)
+ return transforms(img)
+ else:
+ return img
+
+
+class SVTRGeometry(object):
+ def __init__(self,
+ aug_type=0,
+ degrees=15,
+ translate=(0.3, 0.3),
+ scale=(0.5, 2.),
+ shear=(45, 15),
+ distortion=0.5,
+ p=0.5):
+ self.aug_type = aug_type
+ self.p = p
+ self.transforms = []
+ self.transforms.append(CVRandomRotation(degrees=degrees))
+ self.transforms.append(
+ CVRandomAffine(
+ degrees=degrees, translate=translate, scale=scale, shear=shear))
+ self.transforms.append(CVRandomPerspective(distortion=distortion))
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ if self.aug_type:
+ random.shuffle(self.transforms)
+ transforms = Compose(self.transforms[:random.randint(1, 3)])
+ img = transforms(img)
+ else:
+ img = self.transforms[random.randint(0, 2)](img)
+ return img
+ else:
+ return img
diff --git a/ppocr/data/imaug/ct_process.py b/ppocr/data/imaug/ct_process.py
index 59715090036e1020800950b02b9ea06ab5c8d4c2..933d42f98c068780c2140740eddbc553cec02ee6 100644
--- a/ppocr/data/imaug/ct_process.py
+++ b/ppocr/data/imaug/ct_process.py
@@ -19,7 +19,8 @@ import pyclipper
import paddle
import numpy as np
-import Polygon as plg
+from ppocr.utils.utility import check_install
+
import scipy.io as scio
from PIL import Image
@@ -70,6 +71,8 @@ class MakeShrink():
return peri
def shrink(self, bboxes, rate, max_shr=20):
+ check_install('Polygon', 'Polygon3')
+ import Polygon as plg
rate = rate * rate
shrinked_bboxes = []
for bbox in bboxes:
diff --git a/ppocr/data/imaug/drrg_targets.py b/ppocr/data/imaug/drrg_targets.py
index c56e878b837328ef2efde40b96b5571dffbb4791..7fdfd096819b266290353d842ef531e8220c586c 100644
--- a/ppocr/data/imaug/drrg_targets.py
+++ b/ppocr/data/imaug/drrg_targets.py
@@ -18,7 +18,7 @@ https://github.com/open-mmlab/mmocr/blob/main/mmocr/datasets/pipelines/textdet_t
import cv2
import numpy as np
-from lanms import merge_quadrangle_n9 as la_nms
+from ppocr.utils.utility import check_install
from numpy.linalg import norm
@@ -543,6 +543,8 @@ class DRRGTargets(object):
score = np.ones((text_comps.shape[0], 1), dtype=np.float32)
text_comps = np.hstack([text_comps, score])
+ check_install('lanms', 'lanms-neo')
+ from lanms import merge_quadrangle_n9 as la_nms
text_comps = la_nms(text_comps, self.text_comp_nms_thr)
if text_comps.shape[0] >= 1:
diff --git a/ppocr/data/imaug/fce_aug.py b/ppocr/data/imaug/fce_aug.py
index 66bafef13caaaa958c89f865bde04cb25f031329..baaaa3355558bb6919f6b0b3b58016680f15f31c 100644
--- a/ppocr/data/imaug/fce_aug.py
+++ b/ppocr/data/imaug/fce_aug.py
@@ -208,7 +208,7 @@ class RandomCropFlip:
for polygon in all_polys:
rect = cv2.minAreaRect(polygon.astype(np.int32).reshape(-1, 2))
box = cv2.boxPoints(rect)
- box = np.int0(box)
+ box = np.int64(box)
text_polys.append([box[0], box[1], box[2], box[3]])
polys = np.array(text_polys, dtype=np.int32)
diff --git a/ppocr/data/imaug/fce_targets.py b/ppocr/data/imaug/fce_targets.py
index 8c64276e26665d2779d35154bf9cd77edddad580..054631cb2ddee4e4fd4d5532538f318379568ded 100644
--- a/ppocr/data/imaug/fce_targets.py
+++ b/ppocr/data/imaug/fce_targets.py
@@ -22,10 +22,12 @@ from numpy.fft import fft
from numpy.linalg import norm
import sys
+
def vector_slope(vec):
assert len(vec) == 2
return abs(vec[1] / (vec[0] + 1e-8))
+
class FCENetTargets:
"""Generate the ground truth targets of FCENet: Fourier Contour Embedding
for Arbitrary-Shaped Text Detection.
@@ -107,7 +109,9 @@ class FCENetTargets:
for i in range(1, n):
current_line_len = i * delta_length
- while current_edge_ind + 1 < len(length_cumsum) and current_line_len >= length_cumsum[current_edge_ind + 1]:
+ while current_edge_ind + 1 < len(
+ length_cumsum) and current_line_len >= length_cumsum[
+ current_edge_ind + 1]:
current_edge_ind += 1
current_edge_end_shift = current_line_len - length_cumsum[
@@ -239,10 +243,9 @@ class FCENetTargets:
head_inds = [head_start, head_end]
tail_inds = [tail_start, tail_end]
else:
- if vector_slope(points[1] - points[0]) + vector_slope(
- points[3] - points[2]) < vector_slope(points[
- 2] - points[1]) + vector_slope(points[0] - points[
- 3]):
+ if vector_slope(points[1] - points[0]) + vector_slope(points[
+ 3] - points[2]) < vector_slope(points[2] - points[
+ 1]) + vector_slope(points[0] - points[3]):
horizontal_edge_inds = [[0, 1], [2, 3]]
vertical_edge_inds = [[3, 0], [1, 2]]
else:
@@ -582,7 +585,7 @@ class FCENetTargets:
lv_ignore_polys = [[] for i in range(len(lv_size_divs))]
level_maps = []
for poly in text_polys:
- polygon = np.array(poly, dtype=np.int).reshape((1, -1, 2))
+ polygon = np.array(poly, dtype=np.int32).reshape((1, -1, 2))
_, _, box_w, box_h = cv2.boundingRect(polygon)
proportion = max(box_h, box_w) / (h + 1e-8)
@@ -591,7 +594,7 @@ class FCENetTargets:
lv_text_polys[ind].append(poly / lv_size_divs[ind])
for ignore_poly in ignore_polys:
- polygon = np.array(ignore_poly, dtype=np.int).reshape((1, -1, 2))
+ polygon = np.array(ignore_poly, dtype=np.int32).reshape((1, -1, 2))
_, _, box_w, box_h = cv2.boundingRect(polygon)
proportion = max(box_h, box_w) / (h + 1e-8)
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 63c5d6aa7851422e21a567dfe938c417793ca7ea..148b09368717a09fcc20e0852c69a948311cb511 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -64,7 +64,7 @@ class DetLabelEncode(object):
return None
boxes = self.expand_points_num(boxes)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['texts'] = txts
@@ -218,7 +218,7 @@ class E2ELabelEncodeTest(BaseRecLabelEncode):
else:
txt_tags.append(False)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['ignore_tags'] = txt_tags
temp_texts = []
@@ -254,7 +254,7 @@ class E2ELabelEncodeTrain(object):
else:
txt_tags.append(False)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['texts'] = txts
@@ -886,6 +886,62 @@ class SARLabelEncode(BaseRecLabelEncode):
return [self.padding_idx]
+class SATRNLabelEncode(BaseRecLabelEncode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ lower=False,
+ **kwargs):
+ super(SATRNLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+ self.lower = lower
+
+ def add_special_char(self, dict_character):
+ beg_end_str = ""
+ unknown_str = ""
+ padding_str = ""
+ dict_character = dict_character + [unknown_str]
+ self.unknown_idx = len(dict_character) - 1
+ dict_character = dict_character + [beg_end_str]
+ self.start_idx = len(dict_character) - 1
+ self.end_idx = len(dict_character) - 1
+ dict_character = dict_character + [padding_str]
+ self.padding_idx = len(dict_character) - 1
+
+ return dict_character
+
+ def encode(self, text):
+ if self.lower:
+ text = text.lower()
+ text_list = []
+ for char in text:
+ text_list.append(self.dict.get(char, self.unknown_idx))
+ if len(text_list) == 0:
+ return None
+ return text_list
+
+ def __call__(self, data):
+ text = data['label']
+ text = self.encode(text)
+ if text is None:
+ return None
+ data['length'] = np.array(len(text))
+ target = [self.start_idx] + text + [self.end_idx]
+ padded_text = [self.padding_idx for _ in range(self.max_text_len)]
+ if len(target) > self.max_text_len:
+ padded_text = target[:self.max_text_len]
+ else:
+ padded_text[:len(target)] = target
+ data['label'] = np.array(padded_text)
+ return data
+
+ def get_ignored_tokens(self):
+ return [self.padding_idx]
+
+
class PRENLabelEncode(BaseRecLabelEncode):
def __init__(self,
max_text_length,
@@ -1185,27 +1241,36 @@ class MultiLabelEncode(BaseRecLabelEncode):
max_text_length,
character_dict_path=None,
use_space_char=False,
+ gtc_encode=None,
**kwargs):
super(MultiLabelEncode, self).__init__(
max_text_length, character_dict_path, use_space_char)
self.ctc_encode = CTCLabelEncode(max_text_length, character_dict_path,
use_space_char, **kwargs)
- self.sar_encode = SARLabelEncode(max_text_length, character_dict_path,
- use_space_char, **kwargs)
+ self.gtc_encode_type = gtc_encode
+ if gtc_encode is None:
+ self.gtc_encode = SARLabelEncode(
+ max_text_length, character_dict_path, use_space_char, **kwargs)
+ else:
+ self.gtc_encode = eval(gtc_encode)(
+ max_text_length, character_dict_path, use_space_char, **kwargs)
def __call__(self, data):
data_ctc = copy.deepcopy(data)
- data_sar = copy.deepcopy(data)
+ data_gtc = copy.deepcopy(data)
data_out = dict()
data_out['img_path'] = data.get('img_path', None)
data_out['image'] = data['image']
ctc = self.ctc_encode.__call__(data_ctc)
- sar = self.sar_encode.__call__(data_sar)
- if ctc is None or sar is None:
+ gtc = self.gtc_encode.__call__(data_gtc)
+ if ctc is None or gtc is None:
return None
data_out['label_ctc'] = ctc['label']
- data_out['label_sar'] = sar['label']
+ if self.gtc_encode_type is not None:
+ data_out['label_gtc'] = gtc['label']
+ else:
+ data_out['label_sar'] = gtc['label']
data_out['length'] = ctc['length']
return data_out
@@ -1396,10 +1461,9 @@ class VLLabelEncode(BaseRecLabelEncode):
max_text_length,
character_dict_path=None,
use_space_char=False,
- lower=True,
**kwargs):
- super(VLLabelEncode, self).__init__(
- max_text_length, character_dict_path, use_space_char, lower)
+ super(VLLabelEncode, self).__init__(max_text_length,
+ character_dict_path, use_space_char)
self.dict = {}
for i, char in enumerate(self.character):
self.dict[char] = i
diff --git a/ppocr/data/imaug/make_border_map.py b/ppocr/data/imaug/make_border_map.py
index abab38368db2de84e54b060598fc509a65219296..03b7817cfbe2068184981b18a7aa539c8d350e3b 100644
--- a/ppocr/data/imaug/make_border_map.py
+++ b/ppocr/data/imaug/make_border_map.py
@@ -44,6 +44,10 @@ class MakeBorderMap(object):
self.shrink_ratio = shrink_ratio
self.thresh_min = thresh_min
self.thresh_max = thresh_max
+ if 'total_epoch' in kwargs and 'epoch' in kwargs and kwargs[
+ 'epoch'] != "None":
+ self.shrink_ratio = self.shrink_ratio + 0.2 * kwargs[
+ 'epoch'] / float(kwargs['total_epoch'])
def __call__(self, data):
diff --git a/ppocr/data/imaug/make_shrink_map.py b/ppocr/data/imaug/make_shrink_map.py
index 6c65c20e5621f91a5b1fba549b059c92923fca6f..d0317b61fe05ce75c479a2485cef540742f489e0 100644
--- a/ppocr/data/imaug/make_shrink_map.py
+++ b/ppocr/data/imaug/make_shrink_map.py
@@ -38,6 +38,10 @@ class MakeShrinkMap(object):
def __init__(self, min_text_size=8, shrink_ratio=0.4, **kwargs):
self.min_text_size = min_text_size
self.shrink_ratio = shrink_ratio
+ if 'total_epoch' in kwargs and 'epoch' in kwargs and kwargs[
+ 'epoch'] != "None":
+ self.shrink_ratio = self.shrink_ratio + 0.2 * kwargs[
+ 'epoch'] / float(kwargs['total_epoch'])
def __call__(self, data):
image = data['image']
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index e22153bdeab06565feed79715633172a275aecc7..9780082f1cc3629c7b05a24747537d473d2a42a4 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -18,8 +18,9 @@ import numpy as np
import random
import copy
from PIL import Image
+import PIL
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
-from .abinet_aug import CVGeometry, CVDeterioration, CVColorJitter
+from .abinet_aug import CVGeometry, CVDeterioration, CVColorJitter, SVTRGeometry, SVTRDeterioration
from paddle.vision.transforms import Compose
@@ -69,6 +70,8 @@ class BaseDataAugmentation(object):
self.jitter_prob = jitter_prob
self.blur_prob = blur_prob
self.hsv_aug_prob = hsv_aug_prob
+ # for GaussianBlur
+ self.fil = cv2.getGaussianKernel(ksize=5, sigma=1, ktype=cv2.CV_32F)
def __call__(self, data):
img = data['image']
@@ -78,7 +81,8 @@ class BaseDataAugmentation(object):
img = get_crop(img)
if random.random() <= self.blur_prob:
- img = blur(img)
+ # GaussianBlur
+ img = cv2.sepFilter2D(img, -1, self.fil, self.fil)
if random.random() <= self.hsv_aug_prob:
img = hsv_aug(img)
@@ -169,6 +173,38 @@ class RecConAug(object):
return data
+class SVTRRecAug(object):
+ def __init__(self,
+ aug_type=0,
+ geometry_p=0.5,
+ deterioration_p=0.25,
+ colorjitter_p=0.25,
+ **kwargs):
+ self.transforms = Compose([
+ SVTRGeometry(
+ aug_type=aug_type,
+ degrees=45,
+ translate=(0.0, 0.0),
+ scale=(0.5, 2.),
+ shear=(45, 15),
+ distortion=0.5,
+ p=geometry_p), SVTRDeterioration(
+ var=20, degrees=6, factor=4, p=deterioration_p),
+ CVColorJitter(
+ brightness=0.5,
+ contrast=0.5,
+ saturation=0.5,
+ hue=0.1,
+ p=colorjitter_p)
+ ])
+
+ def __call__(self, data):
+ img = data['image']
+ img = self.transforms(img)
+ data['image'] = img
+ return data
+
+
class ClsResizeImg(object):
def __init__(self, image_shape, **kwargs):
self.image_shape = image_shape
@@ -184,17 +220,20 @@ class RecResizeImg(object):
def __init__(self,
image_shape,
infer_mode=False,
+ eval_mode=False,
character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
padding=True,
**kwargs):
self.image_shape = image_shape
self.infer_mode = infer_mode
+ self.eval_mode = eval_mode
self.character_dict_path = character_dict_path
self.padding = padding
def __call__(self, data):
img = data['image']
- if self.infer_mode and self.character_dict_path is not None:
+ if self.eval_mode or (self.infer_mode and
+ self.character_dict_path is not None):
norm_img, valid_ratio = resize_norm_img_chinese(img,
self.image_shape)
else:
@@ -368,7 +407,7 @@ class GrayRecResizeImg(object):
def __init__(self,
image_shape,
resize_type,
- inter_type='Image.ANTIALIAS',
+ inter_type="Image.Resampling.LANCZOS",
scale=True,
padding=False,
**kwargs):
@@ -538,7 +577,7 @@ def resize_norm_img_chinese(img, image_shape):
max_wh_ratio = imgW * 1.0 / imgH
h, w = img.shape[0], img.shape[1]
ratio = w * 1.0 / h
- max_wh_ratio = min(max(max_wh_ratio, ratio), max_wh_ratio)
+ max_wh_ratio = max(max_wh_ratio, ratio)
imgW = int(imgH * max_wh_ratio)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
diff --git a/ppocr/data/lmdb_dataset.py b/ppocr/data/lmdb_dataset.py
index 295643e401481d30cf433346727f39d4a4c7d2f4..f3efb604285a2dbc0062f80c95ad1ee8a9b3a127 100644
--- a/ppocr/data/lmdb_dataset.py
+++ b/ppocr/data/lmdb_dataset.py
@@ -18,6 +18,7 @@ import lmdb
import cv2
import string
import six
+import pickle
from PIL import Image
from .imaug import transform, create_operators
@@ -203,3 +204,87 @@ class LMDBDataSetSR(LMDBDataSet):
if outs is None:
return self.__getitem__(np.random.randint(self.__len__()))
return outs
+
+
+class LMDBDataSetTableMaster(LMDBDataSet):
+ def load_hierarchical_lmdb_dataset(self, data_dir):
+ lmdb_sets = {}
+ dataset_idx = 0
+ env = lmdb.open(
+ data_dir,
+ max_readers=32,
+ readonly=True,
+ lock=False,
+ readahead=False,
+ meminit=False)
+ txn = env.begin(write=False)
+ num_samples = int(pickle.loads(txn.get(b"__len__")))
+ lmdb_sets[dataset_idx] = {"dirpath":data_dir, "env":env, \
+ "txn":txn, "num_samples":num_samples}
+ return lmdb_sets
+
+ def get_img_data(self, value):
+ """get_img_data"""
+ if not value:
+ return None
+ imgdata = np.frombuffer(value, dtype='uint8')
+ if imgdata is None:
+ return None
+ imgori = cv2.imdecode(imgdata, 1)
+ if imgori is None:
+ return None
+ return imgori
+
+ def get_lmdb_sample_info(self, txn, index):
+ def convert_bbox(bbox_str_list):
+ bbox_list = []
+ for bbox_str in bbox_str_list:
+ bbox_list.append(int(bbox_str))
+ return bbox_list
+
+ try:
+ data = pickle.loads(txn.get(str(index).encode('utf8')))
+ except:
+ return None
+
+ # img_name, img, info_lines
+ file_name = data[0]
+ bytes = data[1]
+ info_lines = data[2] # raw data from TableMASTER annotation file.
+ # parse info_lines
+ raw_data = info_lines.strip().split('\n')
+ raw_name, text = raw_data[0], raw_data[
+ 1] # don't filter the samples's length over max_seq_len.
+ text = text.split(',')
+ bbox_str_list = raw_data[2:]
+ bbox_split = ','
+ bboxes = [{
+ 'bbox': convert_bbox(bsl.strip().split(bbox_split)),
+ 'tokens': ['1', '2']
+ } for bsl in bbox_str_list]
+
+ # advance parse bbox
+ # import pdb;pdb.set_trace()
+
+ line_info = {}
+ line_info['file_name'] = file_name
+ line_info['structure'] = text
+ line_info['cells'] = bboxes
+ line_info['image'] = bytes
+ return line_info
+
+ def __getitem__(self, idx):
+ lmdb_idx, file_idx = self.data_idx_order_list[idx]
+ lmdb_idx = int(lmdb_idx)
+ file_idx = int(file_idx)
+ data = self.get_lmdb_sample_info(self.lmdb_sets[lmdb_idx]['txn'],
+ file_idx)
+ if data is None:
+ return self.__getitem__(np.random.randint(self.__len__()))
+ outs = transform(data, self.ops)
+ if outs is None:
+ return self.__getitem__(np.random.randint(self.__len__()))
+ return outs
+
+ def __len__(self):
+ return self.data_idx_order_list.shape[0]
diff --git a/ppocr/data/multi_scale_sampler.py b/ppocr/data/multi_scale_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..45793e2ba1f5c5a4f4388dd22e7146725854fa76
--- /dev/null
+++ b/ppocr/data/multi_scale_sampler.py
@@ -0,0 +1,171 @@
+from paddle.io import Sampler
+import paddle.distributed as dist
+
+import numpy as np
+import random
+import math
+
+
+class MultiScaleSampler(Sampler):
+ def __init__(self,
+ data_source,
+ scales,
+ first_bs=128,
+ fix_bs=True,
+ divided_factor=[8, 16],
+ is_training=True,
+ ratio_wh=0.8,
+ max_w=480.,
+ seed=None):
+ """
+ multi scale samper
+ Args:
+ data_source(dataset)
+ scales(list): several scales for image resolution
+ first_bs(int): batch size for the first scale in scales
+ divided_factor(list[w, h]): ImageNet models down-sample images by a factor, ensure that width and height dimensions are multiples are multiple of devided_factor.
+ is_training(boolean): mode
+ """
+ # min. and max. spatial dimensions
+ self.data_source = data_source
+ self.data_idx_order_list = np.array(data_source.data_idx_order_list)
+ self.ds_width = data_source.ds_width
+ self.seed = data_source.seed
+ if self.ds_width:
+ self.wh_ratio = data_source.wh_ratio
+ self.wh_ratio_sort = data_source.wh_ratio_sort
+ self.n_data_samples = len(self.data_source)
+ self.ratio_wh = ratio_wh
+ self.max_w = max_w
+
+ if isinstance(scales[0], list):
+ width_dims = [i[0] for i in scales]
+ height_dims = [i[1] for i in scales]
+ elif isinstance(scales[0], int):
+ width_dims = scales
+ height_dims = scales
+ base_im_w = width_dims[0]
+ base_im_h = height_dims[0]
+ base_batch_size = first_bs
+
+ # Get the GPU and node related information
+ num_replicas = dist.get_world_size()
+ rank = dist.get_rank()
+ # adjust the total samples to avoid batch dropping
+ num_samples_per_replica = int(self.n_data_samples * 1.0 / num_replicas)
+
+ img_indices = [idx for idx in range(self.n_data_samples)]
+
+ self.shuffle = False
+ if is_training:
+ # compute the spatial dimensions and corresponding batch size
+ # ImageNet models down-sample images by a factor of 32.
+ # Ensure that width and height dimensions are multiples are multiple of 32.
+ width_dims = [
+ int((w // divided_factor[0]) * divided_factor[0])
+ for w in width_dims
+ ]
+ height_dims = [
+ int((h // divided_factor[1]) * divided_factor[1])
+ for h in height_dims
+ ]
+
+ img_batch_pairs = list()
+ base_elements = base_im_w * base_im_h * base_batch_size
+ for (h, w) in zip(height_dims, width_dims):
+ if fix_bs:
+ batch_size = base_batch_size
+ else:
+ batch_size = int(max(1, (base_elements / (h * w))))
+ img_batch_pairs.append((w, h, batch_size))
+ self.img_batch_pairs = img_batch_pairs
+ self.shuffle = True
+ else:
+ self.img_batch_pairs = [(base_im_w, base_im_h, base_batch_size)]
+
+ self.img_indices = img_indices
+ self.n_samples_per_replica = num_samples_per_replica
+ self.epoch = 0
+ self.rank = rank
+ self.num_replicas = num_replicas
+
+ self.batch_list = []
+ self.current = 0
+ last_index = num_samples_per_replica * num_replicas
+ indices_rank_i = self.img_indices[self.rank:last_index:
+ self.num_replicas]
+ while self.current < self.n_samples_per_replica:
+ for curr_w, curr_h, curr_bsz in self.img_batch_pairs:
+ end_index = min(self.current + curr_bsz,
+ self.n_samples_per_replica)
+ batch_ids = indices_rank_i[self.current:end_index]
+ n_batch_samples = len(batch_ids)
+ if n_batch_samples != curr_bsz:
+ batch_ids += indices_rank_i[:(curr_bsz - n_batch_samples)]
+ self.current += curr_bsz
+
+ if len(batch_ids) > 0:
+ batch = [curr_w, curr_h, len(batch_ids)]
+ self.batch_list.append(batch)
+ random.shuffle(self.batch_list)
+ self.length = len(self.batch_list)
+ self.batchs_in_one_epoch = self.iter()
+ self.batchs_in_one_epoch_id = [
+ i for i in range(len(self.batchs_in_one_epoch))
+ ]
+
+ def __iter__(self):
+ if self.seed is None:
+ random.seed(self.epoch)
+ self.epoch += 1
+ else:
+ random.seed(self.seed)
+ random.shuffle(self.batchs_in_one_epoch_id)
+ for batch_tuple_id in self.batchs_in_one_epoch_id:
+ yield self.batchs_in_one_epoch[batch_tuple_id]
+
+ def iter(self):
+ if self.shuffle:
+ if self.seed is not None:
+ random.seed(self.seed)
+ else:
+ random.seed(self.epoch)
+ if not self.ds_width:
+ random.shuffle(self.img_indices)
+ random.shuffle(self.img_batch_pairs)
+ indices_rank_i = self.img_indices[self.rank:len(self.img_indices):
+ self.num_replicas]
+ else:
+ indices_rank_i = self.img_indices[self.rank:len(self.img_indices):
+ self.num_replicas]
+
+ start_index = 0
+ batchs_in_one_epoch = []
+ for batch_tuple in self.batch_list:
+ curr_w, curr_h, curr_bsz = batch_tuple
+ end_index = min(start_index + curr_bsz, self.n_samples_per_replica)
+ batch_ids = indices_rank_i[start_index:end_index]
+ n_batch_samples = len(batch_ids)
+ if n_batch_samples != curr_bsz:
+ batch_ids += indices_rank_i[:(curr_bsz - n_batch_samples)]
+ start_index += curr_bsz
+
+ if len(batch_ids) > 0:
+ if self.ds_width:
+ wh_ratio_current = self.wh_ratio[self.wh_ratio_sort[
+ batch_ids]]
+ ratio_current = wh_ratio_current.mean()
+ ratio_current = ratio_current if ratio_current * curr_h < self.max_w else self.max_w / curr_h
+ else:
+ ratio_current = None
+ batch = [(curr_w, curr_h, b_id, ratio_current)
+ for b_id in batch_ids]
+ # yield batch
+ batchs_in_one_epoch.append(batch)
+ return batchs_in_one_epoch
+
+ def set_epoch(self, epoch: int):
+ self.epoch = epoch
+
+ def __len__(self):
+ return self.length
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index 402f1e38fed9e32722e2dd160f10f779028807a3..f7c4c8f1a21ddb36e27fe4c1a217ce3fa9caff41 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -12,6 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
+import cv2
+import math
import os
import json
import random
@@ -48,11 +50,31 @@ class SimpleDataSet(Dataset):
self.data_idx_order_list = list(range(len(self.data_lines)))
if self.mode == "train" and self.do_shuffle:
self.shuffle_data_random()
+
+ self.set_epoch_as_seed(self.seed, dataset_config)
+
self.ops = create_operators(dataset_config['transforms'], global_config)
self.ext_op_transform_idx = dataset_config.get("ext_op_transform_idx",
2)
self.need_reset = True in [x < 1 for x in ratio_list]
+ def set_epoch_as_seed(self, seed, dataset_config):
+ if self.mode == 'train':
+ try:
+ border_map_id = [index
+ for index, dictionary in enumerate(dataset_config['transforms'])
+ if 'MakeBorderMap' in dictionary][0]
+ shrink_map_id = [index
+ for index, dictionary in enumerate(dataset_config['transforms'])
+ if 'MakeShrinkMap' in dictionary][0]
+ dataset_config['transforms'][border_map_id]['MakeBorderMap'][
+ 'epoch'] = seed if seed is not None else 0
+ dataset_config['transforms'][shrink_map_id]['MakeShrinkMap'][
+ 'epoch'] = seed if seed is not None else 0
+ except Exception as E:
+ print(E)
+ return
+
def get_image_info_list(self, file_list, ratio_list):
if isinstance(file_list, str):
file_list = [file_list]
@@ -149,3 +171,96 @@ class SimpleDataSet(Dataset):
def __len__(self):
return len(self.data_idx_order_list)
+
+
+class MultiScaleDataSet(SimpleDataSet):
+ def __init__(self, config, mode, logger, seed=None):
+ super(MultiScaleDataSet, self).__init__(config, mode, logger, seed)
+ self.ds_width = config[mode]['dataset'].get('ds_width', False)
+ if self.ds_width:
+ self.wh_aware()
+
+ def wh_aware(self):
+ data_line_new = []
+ wh_ratio = []
+ for lins in self.data_lines:
+ data_line_new.append(lins)
+ lins = lins.decode('utf-8')
+ name, label, w, h = lins.strip("\n").split(self.delimiter)
+ wh_ratio.append(float(w) / float(h))
+
+ self.data_lines = data_line_new
+ self.wh_ratio = np.array(wh_ratio)
+ self.wh_ratio_sort = np.argsort(self.wh_ratio)
+ self.data_idx_order_list = list(range(len(self.data_lines)))
+
+ def resize_norm_img(self, data, imgW, imgH, padding=True):
+ img = data['image']
+ h = img.shape[0]
+ w = img.shape[1]
+ if not padding:
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ else:
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ padding_im = np.zeros((3, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, :resized_w] = resized_image
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ data['image'] = padding_im
+ data['valid_ratio'] = valid_ratio
+ return data
+
+ def __getitem__(self, properties):
+ # properites is a tuple, contains (width, height, index)
+ img_height = properties[1]
+ idx = properties[2]
+ if self.ds_width and properties[3] is not None:
+ wh_ratio = properties[3]
+ img_width = img_height * (1 if int(round(wh_ratio)) == 0 else
+ int(round(wh_ratio)))
+ file_idx = self.wh_ratio_sort[idx]
+ else:
+ file_idx = self.data_idx_order_list[idx]
+ img_width = properties[0]
+ wh_ratio = None
+
+ data_line = self.data_lines[file_idx]
+ try:
+ data_line = data_line.decode('utf-8')
+ substr = data_line.strip("\n").split(self.delimiter)
+ file_name = substr[0]
+ file_name = self._try_parse_filename_list(file_name)
+ label = substr[1]
+ img_path = os.path.join(self.data_dir, file_name)
+ data = {'img_path': img_path, 'label': label}
+ if not os.path.exists(img_path):
+ raise Exception("{} does not exist!".format(img_path))
+ with open(data['img_path'], 'rb') as f:
+ img = f.read()
+ data['image'] = img
+ data['ext_data'] = self.get_ext_data()
+ outs = transform(data, self.ops[:-1])
+ if outs is not None:
+ outs = self.resize_norm_img(outs, img_width, img_height)
+ outs = transform(outs, self.ops[-1:])
+ except:
+ self.logger.error(
+ "When parsing line {}, error happened with msg: {}".format(
+ data_line, traceback.format_exc()))
+ outs = None
+ if outs is None:
+ # during evaluation, we should fix the idx to get same results for many times of evaluation.
+ rnd_idx = (idx + 1) % self.__len__()
+ return self.__getitem__([img_width, img_height, rnd_idx, wh_ratio])
+ return outs
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index c7142e3e5e73e25764dde4631a47be939905e3be..9e6a45478e108637494db694d6a05c8db5b5a40e 100644
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -41,6 +41,8 @@ from .rec_vl_loss import VLLoss
from .rec_spin_att_loss import SPINAttentionLoss
from .rec_rfl_loss import RFLLoss
from .rec_can_loss import CANLoss
+from .rec_satrn_loss import SATRNLoss
+from .rec_nrtr_loss import NRTRLoss
# cls loss
from .cls_loss import ClsLoss
@@ -73,7 +75,8 @@ def build_loss(config):
'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss',
'TableMasterLoss', 'SPINAttentionLoss', 'VLLoss', 'StrokeFocusLoss',
- 'SLALoss', 'CTLoss', 'RFLLoss', 'DRRGLoss', 'CANLoss', 'TelescopeLoss'
+ 'SLALoss', 'CTLoss', 'RFLLoss', 'DRRGLoss', 'CANLoss', 'TelescopeLoss',
+ 'SATRNLoss', 'NRTRLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index 58410b4db2157074c2cb0f7db590c84021e10ace..9ad854cd120c996e2c18c61f00718e5826b25372 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -165,3 +165,79 @@ class LossFromOutput(nn.Layer):
elif self.reduction == 'sum':
loss = paddle.sum(loss)
return {'loss': loss}
+
+
+class KLDivLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self):
+ super().__init__()
+
+ def _kldiv(self, x, target, mask=None):
+ eps = 1.0e-10
+ loss = target * (paddle.log(target + eps) - x)
+ if mask is not None:
+ loss = loss.flatten(0, 1).sum(axis=1)
+ loss = loss.masked_select(mask).mean()
+ else:
+ # batch mean loss
+ loss = paddle.sum(loss) / loss.shape[0]
+ return loss
+
+ def forward(self, logits_s, logits_t, mask=None):
+ log_out_s = F.log_softmax(logits_s, axis=-1)
+ out_t = F.softmax(logits_t, axis=-1)
+ loss = self._kldiv(log_out_s, out_t, mask)
+ return loss
+
+
+class DKDLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self, temperature=1.0, alpha=1.0, beta=1.0):
+ super().__init__()
+ self.temperature = temperature
+ self.alpha = alpha
+ self.beta = beta
+
+ def _cat_mask(self, t, mask1, mask2):
+ t1 = (t * mask1).sum(axis=1, keepdim=True)
+ t2 = (t * mask2).sum(axis=1, keepdim=True)
+ rt = paddle.concat([t1, t2], axis=1)
+ return rt
+
+ def _kl_div(self, x, label, mask=None):
+ y = (label * (paddle.log(label + 1e-10) - x)).sum(axis=1)
+ if mask is not None:
+ y = y.masked_select(mask).mean()
+ else:
+ y = y.mean()
+ return y
+
+ def forward(self, logits_student, logits_teacher, target, mask=None):
+ gt_mask = F.one_hot(
+ target.reshape([-1]), num_classes=logits_student.shape[-1])
+ other_mask = 1 - gt_mask
+ logits_student = logits_student.flatten(0, 1)
+ logits_teacher = logits_teacher.flatten(0, 1)
+ pred_student = F.softmax(logits_student / self.temperature, axis=1)
+ pred_teacher = F.softmax(logits_teacher / self.temperature, axis=1)
+ pred_student = self._cat_mask(pred_student, gt_mask, other_mask)
+ pred_teacher = self._cat_mask(pred_teacher, gt_mask, other_mask)
+ log_pred_student = paddle.log(pred_student)
+ tckd_loss = self._kl_div(log_pred_student,
+ pred_teacher) * (self.temperature**2)
+ pred_teacher_part2 = F.softmax(
+ logits_teacher / self.temperature - 1000.0 * gt_mask, axis=1)
+ log_pred_student_part2 = F.log_softmax(
+ logits_student / self.temperature - 1000.0 * gt_mask, axis=1)
+ nckd_loss = self._kl_div(log_pred_student_part2,
+ pred_teacher_part2) * (self.temperature**2)
+
+ loss = self.alpha * tckd_loss + self.beta * nckd_loss
+
+ return loss
diff --git a/ppocr/losses/combined_loss.py b/ppocr/losses/combined_loss.py
index 8d697d544b51899cdafeff94be2ecce067b907a2..a520f10ffb6a83b444fb98c7d461bbcfaf4ce14d 100644
--- a/ppocr/losses/combined_loss.py
+++ b/ppocr/losses/combined_loss.py
@@ -20,9 +20,9 @@ from .center_loss import CenterLoss
from .ace_loss import ACELoss
from .rec_sar_loss import SARLoss
-from .distillation_loss import DistillationCTCLoss
-from .distillation_loss import DistillationSARLoss
-from .distillation_loss import DistillationDMLLoss
+from .distillation_loss import DistillationCTCLoss, DistillCTCLogits
+from .distillation_loss import DistillationSARLoss, DistillationNRTRLoss
+from .distillation_loss import DistillationDMLLoss, DistillationKLDivLoss, DistillationDKDLoss
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
from .distillation_loss import DistillationVQASerTokenLayoutLMLoss, DistillationSERDMLLoss
from .distillation_loss import DistillationLossFromOutput
diff --git a/ppocr/losses/det_db_loss.py b/ppocr/losses/det_db_loss.py
index 708ffbdb47f349304e2bfd781a836e79348475f4..ce31ef124591ce3e5351460eb94ca50490bcf0e5 100755
--- a/ppocr/losses/det_db_loss.py
+++ b/ppocr/losses/det_db_loss.py
@@ -20,6 +20,7 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
+import paddle
from paddle import nn
from .det_basic_loss import BalanceLoss, MaskL1Loss, DiceLoss
@@ -66,11 +67,21 @@ class DBLoss(nn.Layer):
label_shrink_mask)
loss_shrink_maps = self.alpha * loss_shrink_maps
loss_threshold_maps = self.beta * loss_threshold_maps
+ # CBN loss
+ if 'distance_maps' in predicts.keys():
+ distance_maps = predicts['distance_maps']
+ cbn_maps = predicts['cbn_maps']
+ cbn_loss = self.bce_loss(cbn_maps[:, 0, :, :], label_shrink_map,
+ label_shrink_mask)
+ else:
+ dis_loss = paddle.to_tensor([0.])
+ cbn_loss = paddle.to_tensor([0.])
loss_all = loss_shrink_maps + loss_threshold_maps \
+ loss_binary_maps
- losses = {'loss': loss_all, \
+ losses = {'loss': loss_all+ cbn_loss, \
"loss_shrink_maps": loss_shrink_maps, \
"loss_threshold_maps": loss_threshold_maps, \
- "loss_binary_maps": loss_binary_maps}
+ "loss_binary_maps": loss_binary_maps, \
+ "loss_cbn": cbn_loss}
return losses
diff --git a/ppocr/losses/distillation_loss.py b/ppocr/losses/distillation_loss.py
index 4bfbed75a338e2bd3bca0b80d16028030bf2f0b5..5812544e91d8357c161e4faa4d0e36ce4dbd9374 100644
--- a/ppocr/losses/distillation_loss.py
+++ b/ppocr/losses/distillation_loss.py
@@ -14,12 +14,14 @@
import paddle
import paddle.nn as nn
+import paddle.nn.functional as F
import numpy as np
import cv2
from .rec_ctc_loss import CTCLoss
from .rec_sar_loss import SARLoss
-from .basic_loss import DMLLoss
+from .rec_ce_loss import CELoss
+from .basic_loss import DMLLoss, KLDivLoss, DKDLoss
from .basic_loss import DistanceLoss
from .basic_loss import LossFromOutput
from .det_db_loss import DBLoss
@@ -102,7 +104,6 @@ class DistillationDMLLoss(DMLLoss):
if self.key is not None:
out1 = out1[self.key]
out2 = out2[self.key]
-
if self.maps_name is None:
if self.multi_head:
loss = super().forward(out1[self.dis_head],
@@ -133,6 +134,449 @@ class DistillationDMLLoss(DMLLoss):
return loss_dict
+class DistillationKLDivLoss(KLDivLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="kl_div"):
+ super().__init__()
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head], non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationDKDLoss(DKDLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="dkd",
+ temperature=1.0,
+ alpha=1.0,
+ beta=1.0):
+ super().__init__(temperature, alpha, beta)
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 +
+ max_len] # [batch_size, max_len + 1]
+
+ tgt = tgt.reshape([-1]) # batch_size * (max_len + 1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape,
+ dtype=tgt.dtype)) # batch_size * (max_len + 1)
+
+ loss = super().forward(
+ out1[self.dis_head], out2[self.dis_head], tgt,
+ non_pad_mask) # [batch_size, max_len + 1, num_char]
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationNRTRDMLLoss(DistillationDMLLoss):
+ """
+ """
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head], out2[self.dis_head],
+ non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationKLDivLoss(KLDivLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="kl_div"):
+ super().__init__()
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head], non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationDKDLoss(DKDLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="dkd",
+ temperature=1.0,
+ alpha=1.0,
+ beta=1.0):
+ super().__init__(temperature, alpha, beta)
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 +
+ max_len] # [batch_size, max_len + 1]
+
+ tgt = tgt.reshape([-1]) # batch_size * (max_len + 1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape,
+ dtype=tgt.dtype)) # batch_size * (max_len + 1)
+
+ loss = super().forward(
+ out1[self.dis_head], out2[self.dis_head], tgt,
+ non_pad_mask) # [batch_size, max_len + 1, num_char]
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
class DistillationCTCLoss(CTCLoss):
def __init__(self,
model_name_list=[],
@@ -199,6 +643,40 @@ class DistillationSARLoss(SARLoss):
return loss_dict
+class DistillationNRTRLoss(CELoss):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ smoothing=True,
+ name="loss_nrtr",
+ **kwargs):
+ super().__init__(smoothing=smoothing)
+ self.model_name_list = model_name_list
+ self.key = key
+ self.name = name
+ self.multi_head = multi_head
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, model_name in enumerate(self.model_name_list):
+ out = predicts[model_name]
+ if self.key is not None:
+ out = out[self.key]
+ if self.multi_head:
+ assert 'gtc' in out, 'multi head has multi out'
+ loss = super().forward(out['gtc'], batch[:1] + batch[2:])
+ else:
+ loss = super().forward(out, batch)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, model_name)] = loss
+ return loss_dict
+
+
class DistillationDBLoss(DBLoss):
def __init__(self,
model_name_list=[],
@@ -459,3 +937,212 @@ class DistillationVQADistanceLoss(DistanceLoss):
loss_dict["{}_{}_{}_{}".format(self.name, pair[0], pair[1],
idx)] = loss
return loss_dict
+
+
+class CTCDKDLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self, temperature=0.5, alpha=1.0, beta=1.0):
+ super().__init__()
+ self.temperature = temperature
+ self.alpha = alpha
+ self.beta = beta
+ self.eps = 1e-6
+ self.t = temperature
+ self.act = nn.Softmax(axis=-1)
+ self.use_log = True
+
+ def kl_loss(self, p1, p2): # predict, label
+ loss = paddle.multiply(
+ p2, paddle.log((p2 + self.eps) / (p1 + self.eps) + self.eps))
+ bs = loss.shape[0]
+ loss = paddle.sum(loss) / bs
+ return loss
+
+ def _cat_mask(self, t, mask1, mask2):
+ t1 = (t * mask1).sum(axis=1, keepdim=True)
+ t2 = (t * mask2).sum(axis=1, keepdim=True)
+ rt = paddle.concat([t1, t2], axis=1)
+ return rt
+
+ def multi_label_mask(self, targets):
+
+ targets = targets.astype("int32")
+ res = F.one_hot(targets, num_classes=11465)
+ mask = paddle.clip(paddle.sum(res, axis=1), 0, 1)
+ mask[:, 0] = 0 # ingore ctc blank label
+ return mask
+
+ def forward(self, logits_student, logits_teacher, targets, mask=None):
+
+ gt_mask = self.multi_label_mask(targets)
+ other_mask = paddle.ones_like(gt_mask) - gt_mask
+
+ pred_student = F.softmax(logits_student / self.temperature, axis=-1)
+ pred_teacher = F.softmax(logits_teacher / self.temperature, axis=-1)
+
+ # differents with dkd
+ pred_student = paddle.mean(pred_student, axis=1)
+ pred_teacher = paddle.mean(pred_teacher, axis=1)
+
+ pred_student = self._cat_mask(pred_student, gt_mask, other_mask)
+ pred_teacher = self._cat_mask(pred_teacher, gt_mask, other_mask)
+
+ # differents with dkd
+ tckd_loss = self.kl_loss(pred_student, pred_teacher)
+
+ gt_mask_ex = paddle.expand_as(gt_mask.unsqueeze(axis=1), logits_teacher)
+ pred_teacher_part2 = F.softmax(
+ logits_teacher / self.temperature - 1000.0 * gt_mask_ex, axis=-1)
+ pred_student_part2 = F.softmax(
+ logits_student / self.temperature - 1000.0 * gt_mask_ex, axis=-1)
+ # differents with dkd
+ pred_teacher_part2 = paddle.mean(pred_teacher_part2, axis=1)
+ pred_student_part2 = paddle.mean(pred_student_part2, axis=1)
+
+ # differents with dkd
+ nckd_loss = self.kl_loss(pred_student_part2, pred_teacher_part2)
+ loss = self.alpha * tckd_loss + self.beta * nckd_loss
+ return loss
+
+
+class KLCTCLogits(nn.Layer):
+ def __init__(self, weight=1.0, reduction='mean', mode="mean"):
+ super().__init__()
+ self.weight = weight
+ self.reduction = reduction
+ self.eps = 1e-6
+ self.t = 0.5
+ self.act = nn.Softmax(axis=-1)
+ self.use_log = True
+ self.mode = mode
+ self.ctc_dkd_loss = CTCDKDLoss()
+
+ def kl_loss(self, p1, p2): # predict, label
+ loss = paddle.multiply(
+ p2, paddle.log((p2 + self.eps) / (p1 + self.eps) + self.eps))
+ bs = loss.shape[0]
+ loss = paddle.sum(loss) / bs
+ return loss
+
+ def forward_meanmax(self, stu_out, tea_out):
+
+ stu_out = paddle.mean(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.mean(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ loss = self.kl_loss(stu_out, tea_out)
+
+ return loss
+
+ def forward_meanlog(self, stu_out, tea_out):
+ stu_out = paddle.mean(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.mean(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ if self.use_log is True:
+ # for recognition distillation, log is needed for feature map
+ log_out1 = paddle.log(stu_out)
+ log_out2 = paddle.log(tea_out)
+ loss = (
+ self._kldiv(log_out1, tea_out) + self._kldiv(log_out2, stu_out)
+ ) / 2.0
+
+ return loss
+
+ def forward_sum(self, stu_out, tea_out):
+ stu_out = paddle.sum(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.sum(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ stu_out = paddle.log(stu_out)
+ bs = stu_out.shape[0]
+ loss = tea_out * (paddle.log(tea_out + self.eps) - stu_out)
+ loss = paddle.sum(loss, axis=1) / loss.shape[0]
+ return loss
+
+ def _kldiv(self, x, target):
+ eps = 1.0e-10
+ loss = target * (paddle.log(target + eps) - x)
+ loss = paddle.sum(paddle.mean(loss, axis=1)) / loss.shape[0]
+ return loss
+
+ def forward(self, stu_out, tea_out, targets=None):
+ if self.mode == "log":
+ return self.forward_log(stu_out, tea_out)
+ elif self.mode == "mean":
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.forward_meanmax(stu_out, tea_out)
+ elif self.mode == "sum":
+ return self.forward_sum(stu_out, tea_out)
+ elif self.mode == "meanlog":
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.forward_meanlog(stu_out, tea_out)
+ elif self.mode == "ctcdkd":
+ # ingore ctc blank logits
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.ctc_dkd_loss(stu_out, tea_out, targets)
+ else:
+ raise ValueError("error!!!!!!")
+
+ def forward_log(self, out1, out2):
+ if self.act is not None:
+ out1 = self.act(out1) + 1e-10
+ out2 = self.act(out2) + 1e-10
+ if self.use_log is True:
+ # for recognition distillation, log is needed for feature map
+ log_out1 = paddle.log(out1)
+ log_out2 = paddle.log(out2)
+ loss = (
+ self._kldiv(log_out1, out2) + self._kldiv(log_out2, out1)) / 2.0
+
+ return loss
+
+
+class DistillCTCLogits(KLCTCLogits):
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ name="ctc_logits",
+ reduction="mean"):
+ super().__init__(reduction=reduction)
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.key = key
+ self.name = name
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+
+ if self.key is not None:
+ out1 = out1[self.key]['ctc']
+ out2 = out2[self.key]['ctc']
+
+ ctc_label = batch[1]
+ loss = super().forward(out1, out2, ctc_label)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ return loss_dict
diff --git a/ppocr/losses/rec_aster_loss.py b/ppocr/losses/rec_aster_loss.py
index 52605e46db35339cc22f7f1e6642456bfaf02f11..9b0a34eeac57089ae1d45ad9d8c0427b234c50c9 100644
--- a/ppocr/losses/rec_aster_loss.py
+++ b/ppocr/losses/rec_aster_loss.py
@@ -28,7 +28,7 @@ class CosineEmbeddingLoss(nn.Layer):
def forward(self, x1, x2, target):
similarity = paddle.sum(
- x1 * x2, dim=-1) / (paddle.norm(
+ x1 * x2, axis=-1) / (paddle.norm(
x1, axis=-1) * paddle.norm(
x2, axis=-1) + self.epsilon)
one_list = paddle.full_like(target, fill_value=1)
diff --git a/ppocr/losses/rec_multi_loss.py b/ppocr/losses/rec_multi_loss.py
index 09f007afe6303e83b9a6948df553ec0fca8b6b2d..4f9365750b29368b6fa70e300e6d1b6562ccd4db 100644
--- a/ppocr/losses/rec_multi_loss.py
+++ b/ppocr/losses/rec_multi_loss.py
@@ -21,6 +21,7 @@ from paddle import nn
from .rec_ctc_loss import CTCLoss
from .rec_sar_loss import SARLoss
+from .rec_nrtr_loss import NRTRLoss
class MultiLoss(nn.Layer):
@@ -30,7 +31,6 @@ class MultiLoss(nn.Layer):
self.loss_list = kwargs.pop('loss_config_list')
self.weight_1 = kwargs.get('weight_1', 1.0)
self.weight_2 = kwargs.get('weight_2', 1.0)
- self.gtc_loss = kwargs.get('gtc_loss', 'sar')
for loss_info in self.loss_list:
for name, param in loss_info.items():
if param is not None:
@@ -49,6 +49,9 @@ class MultiLoss(nn.Layer):
elif name == 'SARLoss':
loss = loss_func(predicts['sar'],
batch[:1] + batch[2:])['loss'] * self.weight_2
+ elif name == 'NRTRLoss':
+ loss = loss_func(predicts['nrtr'],
+ batch[:1] + batch[2:])['loss'] * self.weight_2
else:
raise NotImplementedError(
'{} is not supported in MultiLoss yet'.format(name))
diff --git a/ppocr/losses/rec_nrtr_loss.py b/ppocr/losses/rec_nrtr_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbd397fbf0be638d9b43ae5abb36ae1cfc3bb9eb
--- /dev/null
+++ b/ppocr/losses/rec_nrtr_loss.py
@@ -0,0 +1,32 @@
+import paddle
+from paddle import nn
+import paddle.nn.functional as F
+
+
+class NRTRLoss(nn.Layer):
+ def __init__(self, smoothing=True, ignore_index=0, **kwargs):
+ super(NRTRLoss, self).__init__()
+ if ignore_index >= 0 and not smoothing:
+ self.loss_func = nn.CrossEntropyLoss(
+ reduction='mean', ignore_index=ignore_index)
+ self.smoothing = smoothing
+
+ def forward(self, pred, batch):
+ max_len = batch[2].max()
+ tgt = batch[1][:, 1:2 + max_len]
+ pred = pred.reshape([-1, pred.shape[2]])
+ tgt = tgt.reshape([-1])
+ if self.smoothing:
+ eps = 0.1
+ n_class = pred.shape[1]
+ one_hot = F.one_hot(tgt, pred.shape[1])
+ one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)
+ log_prb = F.log_softmax(pred, axis=1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = -(one_hot * log_prb).sum(axis=1)
+ loss = loss.masked_select(non_pad_mask).mean()
+ else:
+ loss = self.loss_func(pred, tgt)
+ return {'loss': loss}
diff --git a/ppocr/losses/rec_satrn_loss.py b/ppocr/losses/rec_satrn_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc7b517878d5349154fa6a9c6e05fe6d45a00dd7
--- /dev/null
+++ b/ppocr/losses/rec_satrn_loss.py
@@ -0,0 +1,46 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/module_losses/ce_module_loss.py
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import nn
+
+
+class SATRNLoss(nn.Layer):
+ def __init__(self, **kwargs):
+ super(SATRNLoss, self).__init__()
+ ignore_index = kwargs.get('ignore_index', 92) # 6626
+ self.loss_func = paddle.nn.loss.CrossEntropyLoss(
+ reduction="none", ignore_index=ignore_index)
+
+ def forward(self, predicts, batch):
+ predict = predicts[:, :
+ -1, :] # ignore last index of outputs to be in same seq_len with targets
+ label = batch[1].astype(
+ "int64")[:, 1:] # ignore first index of target in loss calculation
+ batch_size, num_steps, num_classes = predict.shape[0], predict.shape[
+ 1], predict.shape[2]
+ assert len(label.shape) == len(list(predict.shape)) - 1, \
+ "The target's shape and inputs's shape is [N, d] and [N, num_steps]"
+
+ inputs = paddle.reshape(predict, [-1, num_classes])
+ targets = paddle.reshape(label, [-1])
+ loss = self.loss_func(inputs, targets)
+ return {'loss': loss.mean()}
diff --git a/ppocr/modeling/architectures/__init__.py b/ppocr/modeling/architectures/__init__.py
index 1c955ef3abe9c38e816616cc9b5399c6832aa5f1..00220d28de9387859102d6cf9bc4bb66c923a3fe 100755
--- a/ppocr/modeling/architectures/__init__.py
+++ b/ppocr/modeling/architectures/__init__.py
@@ -38,9 +38,11 @@ def build_model(config):
def apply_to_static(model, config, logger):
if config["Global"].get("to_static", False) is not True:
return model
- assert "image_shape" in config[
- "Global"], "image_shape must be assigned for static training mode..."
- supported_list = ["DB", "SVTR"]
+ assert "d2s_train_image_shape" in config[
+ "Global"], "d2s_train_image_shape must be assigned for static training mode..."
+ supported_list = [
+ "DB", "SVTR_LCNet", "TableMaster", "LayoutXLM", "SLANet", "SVTR"
+ ]
if config["Architecture"]["algorithm"] in ["Distillation"]:
algo = list(config["Architecture"]["Models"].values())[0]["algorithm"]
else:
@@ -49,10 +51,10 @@ def apply_to_static(model, config, logger):
specs = [
InputSpec(
- [None] + config["Global"]["image_shape"], dtype='float32')
+ [None] + config["Global"]["d2s_train_image_shape"], dtype='float32')
]
- if algo == "SVTR":
+ if algo == "SVTR_LCNet":
specs.append([
InputSpec(
[None, config["Global"]["max_text_length"]],
@@ -62,7 +64,55 @@ def apply_to_static(model, config, logger):
[None], dtype='int64'), InputSpec(
[None], dtype='float64')
])
-
+ elif algo == "TableMaster":
+ specs.append(
+ [
+ InputSpec(
+ [None, config["Global"]["max_text_length"]], dtype='int64'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"], 4],
+ dtype='float32'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"], 1],
+ dtype='float32'),
+ InputSpec(
+ [None, 6], dtype='float32'),
+ ])
+ elif algo == "LayoutXLM":
+ specs = [[
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # input_ids
+ InputSpec(
+ shape=[None, 512, 4], dtype="int64"), # bbox
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # attention_mask
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # token_type_ids
+ InputSpec(
+ shape=[None, 3, 224, 224], dtype="float32"), # image
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # label
+ ]]
+ elif algo == "SLANet":
+ specs.append([
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2], dtype='int64'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2, 4],
+ dtype='float32'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2, 1],
+ dtype='float32'),
+ InputSpec(
+ [None, 6], dtype='float64'),
+ ])
+ elif algo == "SVTR":
+ specs.append([
+ InputSpec(
+ [None, config["Global"]["max_text_length"]], dtype='int64'),
+ InputSpec(
+ [None], dtype='int64')
+ ])
model = to_static(model, input_spec=specs)
logger.info("Successfully to apply @to_static with specs: {}".format(specs))
return model
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index e2c2e9c4a4ed526b36d512d824ae8a8a701c17bc..873e8f6de1249bc8f76c4b720b1555d794ba9c4c 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -22,8 +22,11 @@ def build_backbone(config, model_type):
from .det_resnet_vd import ResNet_vd
from .det_resnet_vd_sast import ResNet_SAST
from .det_pp_lcnet import PPLCNet
+ from .rec_lcnetv3 import PPLCNetV3
+ from .rec_hgnet import PPHGNet_small
support_dict = [
- "MobileNetV3", "ResNet", "ResNet_vd", "ResNet_SAST", "PPLCNet"
+ "MobileNetV3", "ResNet", "ResNet_vd", "ResNet_SAST", "PPLCNet",
+ "PPLCNetV3", "PPHGNet_small"
]
if model_type == "table":
from .table_master_resnet import TableResNetExtra
@@ -44,11 +47,14 @@ def build_backbone(config, model_type):
from .rec_vitstr import ViTSTR
from .rec_resnet_rfl import ResNetRFL
from .rec_densenet import DenseNet
+ from .rec_shallow_cnn import ShallowCNN
+ from .rec_lcnetv3 import PPLCNetV3
+ from .rec_hgnet import PPHGNet_small
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
'ResNet31', 'ResNet45', 'ResNet_ASTER', 'MicroNet',
'EfficientNetb3_PREN', 'SVTRNet', 'ViTSTR', 'ResNet32', 'ResNetRFL',
- 'DenseNet'
+ 'DenseNet', 'ShallowCNN', 'PPLCNetV3', 'PPHGNet_small'
]
elif model_type == 'e2e':
from .e2e_resnet_vd_pg import ResNet
diff --git a/ppocr/modeling/backbones/rec_hgnet.py b/ppocr/modeling/backbones/rec_hgnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d990453308a47f3e68f2d899c01edf3ecbdae8db
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_hgnet.py
@@ -0,0 +1,350 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle.nn.initializer import KaimingNormal, Constant
+from paddle.nn import Conv2D, BatchNorm2D, ReLU, AdaptiveAvgPool2D, MaxPool2D
+from paddle.regularizer import L2Decay
+from paddle import ParamAttr
+
+kaiming_normal_ = KaimingNormal()
+zeros_ = Constant(value=0.)
+ones_ = Constant(value=1.)
+
+
+class ConvBNAct(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=1,
+ use_act=True):
+ super().__init__()
+ self.use_act = use_act
+ self.conv = Conv2D(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ bias_attr=False)
+ self.bn = BatchNorm2D(
+ out_channels,
+ weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
+ bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
+ if self.use_act:
+ self.act = ReLU()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.bn(x)
+ if self.use_act:
+ x = self.act(x)
+ return x
+
+
+class ESEModule(nn.Layer):
+ def __init__(self, channels):
+ super().__init__()
+ self.avg_pool = AdaptiveAvgPool2D(1)
+ self.conv = Conv2D(
+ in_channels=channels,
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ self.sigmoid = nn.Sigmoid()
+
+ def forward(self, x):
+ identity = x
+ x = self.avg_pool(x)
+ x = self.conv(x)
+ x = self.sigmoid(x)
+ return paddle.multiply(x=identity, y=x)
+
+
+class HG_Block(nn.Layer):
+ def __init__(
+ self,
+ in_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=False, ):
+ super().__init__()
+ self.identity = identity
+
+ self.layers = nn.LayerList()
+ self.layers.append(
+ ConvBNAct(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=3,
+ stride=1))
+ for _ in range(layer_num - 1):
+ self.layers.append(
+ ConvBNAct(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=3,
+ stride=1))
+
+ # feature aggregation
+ total_channels = in_channels + layer_num * mid_channels
+ self.aggregation_conv = ConvBNAct(
+ in_channels=total_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1)
+ self.att = ESEModule(out_channels)
+
+ def forward(self, x):
+ identity = x
+ output = []
+ output.append(x)
+ for layer in self.layers:
+ x = layer(x)
+ output.append(x)
+ x = paddle.concat(output, axis=1)
+ x = self.aggregation_conv(x)
+ x = self.att(x)
+ if self.identity:
+ x += identity
+ return x
+
+
+class HG_Stage(nn.Layer):
+ def __init__(self,
+ in_channels,
+ mid_channels,
+ out_channels,
+ block_num,
+ layer_num,
+ downsample=True,
+ stride=[2, 1]):
+ super().__init__()
+ self.downsample = downsample
+ if downsample:
+ self.downsample = ConvBNAct(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=stride,
+ groups=in_channels,
+ use_act=False)
+
+ blocks_list = []
+ blocks_list.append(
+ HG_Block(
+ in_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=False))
+ for _ in range(block_num - 1):
+ blocks_list.append(
+ HG_Block(
+ out_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=True))
+ self.blocks = nn.Sequential(*blocks_list)
+
+ def forward(self, x):
+ if self.downsample:
+ x = self.downsample(x)
+ x = self.blocks(x)
+ return x
+
+
+class PPHGNet(nn.Layer):
+ """
+ PPHGNet
+ Args:
+ stem_channels: list. Stem channel list of PPHGNet.
+ stage_config: dict. The configuration of each stage of PPHGNet. such as the number of channels, stride, etc.
+ layer_num: int. Number of layers of HG_Block.
+ use_last_conv: boolean. Whether to use a 1x1 convolutional layer before the classification layer.
+ class_expand: int=2048. Number of channels for the last 1x1 convolutional layer.
+ dropout_prob: float. Parameters of dropout, 0.0 means dropout is not used.
+ class_num: int=1000. The number of classes.
+ Returns:
+ model: nn.Layer. Specific PPHGNet model depends on args.
+ """
+
+ def __init__(
+ self,
+ stem_channels,
+ stage_config,
+ layer_num,
+ in_channels=3,
+ det=False,
+ out_indices=None, ):
+ super().__init__()
+ self.det = det
+ self.out_indices = out_indices if out_indices is not None else [
+ 0, 1, 2, 3
+ ]
+
+ # stem
+ stem_channels.insert(0, in_channels)
+ self.stem = nn.Sequential(* [
+ ConvBNAct(
+ in_channels=stem_channels[i],
+ out_channels=stem_channels[i + 1],
+ kernel_size=3,
+ stride=2 if i == 0 else 1) for i in range(
+ len(stem_channels) - 1)
+ ])
+
+ if self.det:
+ self.pool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
+ # stages
+ self.stages = nn.LayerList()
+ self.out_channels = []
+ for block_id, k in enumerate(stage_config):
+ in_channels, mid_channels, out_channels, block_num, downsample, stride = stage_config[
+ k]
+ self.stages.append(
+ HG_Stage(in_channels, mid_channels, out_channels, block_num,
+ layer_num, downsample, stride))
+ if block_id in self.out_indices:
+ self.out_channels.append(out_channels)
+
+ if not self.det:
+ self.out_channels = stage_config["stage4"][2]
+
+ self._init_weights()
+
+ def _init_weights(self):
+ for m in self.sublayers():
+ if isinstance(m, nn.Conv2D):
+ kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2D)):
+ ones_(m.weight)
+ zeros_(m.bias)
+ elif isinstance(m, nn.Linear):
+ zeros_(m.bias)
+
+ def forward(self, x):
+ x = self.stem(x)
+ if self.det:
+ x = self.pool(x)
+
+ out = []
+ for i, stage in enumerate(self.stages):
+ x = stage(x)
+ if self.det and i in self.out_indices:
+ out.append(x)
+ if self.det:
+ return out
+
+ if self.training:
+ x = F.adaptive_avg_pool2d(x, [1, 40])
+ else:
+ x = F.avg_pool2d(x, [3, 2])
+ return x
+
+
+def PPHGNet_tiny(pretrained=False, use_ssld=False, **kwargs):
+ """
+ PPHGNet_tiny
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_tiny` model depends on args.
+ """
+ stage_config = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [96, 96, 224, 1, False, [2, 1]],
+ "stage2": [224, 128, 448, 1, True, [1, 2]],
+ "stage3": [448, 160, 512, 2, True, [2, 1]],
+ "stage4": [512, 192, 768, 1, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[48, 48, 96],
+ stage_config=stage_config,
+ layer_num=5,
+ **kwargs)
+ return model
+
+
+def PPHGNet_small(pretrained=False, use_ssld=False, det=False, **kwargs):
+ """
+ PPHGNet_small
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_small` model depends on args.
+ """
+ stage_config_det = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [128, 128, 256, 1, False, 2],
+ "stage2": [256, 160, 512, 1, True, 2],
+ "stage3": [512, 192, 768, 2, True, 2],
+ "stage4": [768, 224, 1024, 1, True, 2],
+ }
+
+ stage_config_rec = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [128, 128, 256, 1, True, [2, 1]],
+ "stage2": [256, 160, 512, 1, True, [1, 2]],
+ "stage3": [512, 192, 768, 2, True, [2, 1]],
+ "stage4": [768, 224, 1024, 1, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[64, 64, 128],
+ stage_config=stage_config_det if det else stage_config_rec,
+ layer_num=6,
+ det=det,
+ **kwargs)
+ return model
+
+
+def PPHGNet_base(pretrained=False, use_ssld=True, **kwargs):
+ """
+ PPHGNet_base
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_base` model depends on args.
+ """
+ stage_config = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [160, 192, 320, 1, False, [2, 1]],
+ "stage2": [320, 224, 640, 2, True, [1, 2]],
+ "stage3": [640, 256, 960, 3, True, [2, 1]],
+ "stage4": [960, 288, 1280, 2, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[96, 96, 160],
+ stage_config=stage_config,
+ layer_num=7,
+ dropout_prob=0.2,
+ **kwargs)
+ return model
diff --git a/ppocr/modeling/backbones/rec_lcnetv3.py b/ppocr/modeling/backbones/rec_lcnetv3.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab0951761d0c13d9ad8e0884118086a93f39269b
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_lcnetv3.py
@@ -0,0 +1,491 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import ParamAttr
+from paddle.nn.initializer import Constant, KaimingNormal
+from paddle.nn import AdaptiveAvgPool2D, BatchNorm2D, Conv2D, Dropout, Hardsigmoid, Hardswish, Identity, Linear, ReLU
+from paddle.regularizer import L2Decay
+
+NET_CONFIG_det = {
+ "blocks2":
+ #k, in_c, out_c, s, use_se
+ [[3, 16, 32, 1, False]],
+ "blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
+ "blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
+ "blocks5":
+ [[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False],
+ [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
+ "blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True],
+ [5, 512, 512, 1, False], [5, 512, 512, 1, False]]
+}
+
+NET_CONFIG_rec = {
+ "blocks2":
+ #k, in_c, out_c, s, use_se
+ [[3, 16, 32, 1, False]],
+ "blocks3": [[3, 32, 64, 1, False], [3, 64, 64, 1, False]],
+ "blocks4": [[3, 64, 128, (2, 1), False], [3, 128, 128, 1, False]],
+ "blocks5":
+ [[3, 128, 256, (1, 2), False], [5, 256, 256, 1, False],
+ [5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
+ "blocks6": [[5, 256, 512, (2, 1), True], [5, 512, 512, 1, True],
+ [5, 512, 512, (2, 1), False], [5, 512, 512, 1, False]]
+}
+
+
+def make_divisible(v, divisor=16, min_value=None):
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
+
+
+class LearnableAffineBlock(nn.Layer):
+ def __init__(self, scale_value=1.0, bias_value=0.0, lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.scale = self.create_parameter(
+ shape=[1, ],
+ default_initializer=Constant(value=scale_value),
+ attr=ParamAttr(learning_rate=lr_mult * lab_lr))
+ self.add_parameter("scale", self.scale)
+ self.bias = self.create_parameter(
+ shape=[1, ],
+ default_initializer=Constant(value=bias_value),
+ attr=ParamAttr(learning_rate=lr_mult * lab_lr))
+ self.add_parameter("bias", self.bias)
+
+ def forward(self, x):
+ return self.scale * x + self.bias
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=1,
+ lr_mult=1.0):
+ super().__init__()
+ self.conv = Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(
+ initializer=KaimingNormal(), learning_rate=lr_mult),
+ bias_attr=False)
+
+ self.bn = BatchNorm2D(
+ out_channels,
+ weight_attr=ParamAttr(
+ regularizer=L2Decay(0.0), learning_rate=lr_mult),
+ bias_attr=ParamAttr(
+ regularizer=L2Decay(0.0), learning_rate=lr_mult))
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.bn(x)
+ return x
+
+
+class Act(nn.Layer):
+ def __init__(self, act="hswish", lr_mult=1.0, lab_lr=0.1):
+ super().__init__()
+ if act == "hswish":
+ self.act = Hardswish()
+ else:
+ assert act == "relu"
+ self.act = ReLU()
+ self.lab = LearnableAffineBlock(lr_mult=lr_mult, lab_lr=lab_lr)
+
+ def forward(self, x):
+ return self.lab(self.act(x))
+
+
+class LearnableRepLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ groups=1,
+ num_conv_branches=1,
+ lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.is_repped = False
+ self.groups = groups
+ self.stride = stride
+ self.kernel_size = kernel_size
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_conv_branches = num_conv_branches
+ self.padding = (kernel_size - 1) // 2
+
+ self.identity = BatchNorm2D(
+ num_features=in_channels,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult)
+ ) if out_channels == in_channels and stride == 1 else None
+
+ self.conv_kxk = nn.LayerList([
+ ConvBNLayer(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=groups,
+ lr_mult=lr_mult) for _ in range(self.num_conv_branches)
+ ])
+
+ self.conv_1x1 = ConvBNLayer(
+ in_channels,
+ out_channels,
+ 1,
+ stride,
+ groups=groups,
+ lr_mult=lr_mult) if kernel_size > 1 else None
+
+ self.lab = LearnableAffineBlock(lr_mult=lr_mult, lab_lr=lab_lr)
+ self.act = Act(lr_mult=lr_mult, lab_lr=lab_lr)
+
+ def forward(self, x):
+ # for export
+ if self.is_repped:
+ out = self.lab(self.reparam_conv(x))
+ if self.stride != 2:
+ out = self.act(out)
+ return out
+
+ out = 0
+ if self.identity is not None:
+ out += self.identity(x)
+
+ if self.conv_1x1 is not None:
+ out += self.conv_1x1(x)
+
+ for conv in self.conv_kxk:
+ out += conv(x)
+
+ out = self.lab(out)
+ if self.stride != 2:
+ out = self.act(out)
+ return out
+
+ def rep(self):
+ if self.is_repped:
+ return
+ kernel, bias = self._get_kernel_bias()
+ self.reparam_conv = Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ groups=self.groups)
+ self.reparam_conv.weight.set_value(kernel)
+ self.reparam_conv.bias.set_value(bias)
+ self.is_repped = True
+
+ def _pad_kernel_1x1_to_kxk(self, kernel1x1, pad):
+ if not isinstance(kernel1x1, paddle.Tensor):
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [pad, pad, pad, pad])
+
+ def _get_kernel_bias(self):
+ kernel_conv_1x1, bias_conv_1x1 = self._fuse_bn_tensor(self.conv_1x1)
+ kernel_conv_1x1 = self._pad_kernel_1x1_to_kxk(kernel_conv_1x1,
+ self.kernel_size // 2)
+
+ kernel_identity, bias_identity = self._fuse_bn_tensor(self.identity)
+
+ kernel_conv_kxk = 0
+ bias_conv_kxk = 0
+ for conv in self.conv_kxk:
+ kernel, bias = self._fuse_bn_tensor(conv)
+ kernel_conv_kxk += kernel
+ bias_conv_kxk += bias
+
+ kernel_reparam = kernel_conv_kxk + kernel_conv_1x1 + kernel_identity
+ bias_reparam = bias_conv_kxk + bias_conv_1x1 + bias_identity
+ return kernel_reparam, bias_reparam
+
+ def _fuse_bn_tensor(self, branch):
+ if not branch:
+ return 0, 0
+ elif isinstance(branch, ConvBNLayer):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = paddle.zeros(
+ (self.in_channels, input_dim, self.kernel_size,
+ self.kernel_size),
+ dtype=branch.weight.dtype)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, self.kernel_size // 2,
+ self.kernel_size // 2] = 1
+ self.id_tensor = kernel_value
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+class SELayer(nn.Layer):
+ def __init__(self, channel, reduction=4, lr_mult=1.0):
+ super().__init__()
+ self.avg_pool = AdaptiveAvgPool2D(1)
+ self.conv1 = Conv2D(
+ in_channels=channel,
+ out_channels=channel // reduction,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult))
+ self.relu = ReLU()
+ self.conv2 = Conv2D(
+ in_channels=channel // reduction,
+ out_channels=channel,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult))
+ self.hardsigmoid = Hardsigmoid()
+
+ def forward(self, x):
+ identity = x
+ x = self.avg_pool(x)
+ x = self.conv1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.hardsigmoid(x)
+ x = paddle.multiply(x=identity, y=x)
+ return x
+
+
+class LCNetV3Block(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ dw_size,
+ use_se=False,
+ conv_kxk_num=4,
+ lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.use_se = use_se
+ self.dw_conv = LearnableRepLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=dw_size,
+ stride=stride,
+ groups=in_channels,
+ num_conv_branches=conv_kxk_num,
+ lr_mult=lr_mult,
+ lab_lr=lab_lr)
+ if use_se:
+ self.se = SELayer(in_channels, lr_mult=lr_mult)
+ self.pw_conv = LearnableRepLayer(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ num_conv_branches=conv_kxk_num,
+ lr_mult=lr_mult,
+ lab_lr=lab_lr)
+
+ def forward(self, x):
+ x = self.dw_conv(x)
+ if self.use_se:
+ x = self.se(x)
+ x = self.pw_conv(x)
+ return x
+
+
+class PPLCNetV3(nn.Layer):
+ def __init__(self,
+ scale=1.0,
+ conv_kxk_num=4,
+ lr_mult_list=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
+ lab_lr=0.1,
+ det=False,
+ **kwargs):
+ super().__init__()
+ self.scale = scale
+ self.lr_mult_list = lr_mult_list
+ self.det = det
+
+ self.net_config = NET_CONFIG_det if self.det else NET_CONFIG_rec
+
+ assert isinstance(self.lr_mult_list, (
+ list, tuple
+ )), "lr_mult_list should be in (list, tuple) but got {}".format(
+ type(self.lr_mult_list))
+ assert len(self.lr_mult_list
+ ) == 6, "lr_mult_list length should be 6 but got {}".format(
+ len(self.lr_mult_list))
+
+ self.conv1 = ConvBNLayer(
+ in_channels=3,
+ out_channels=make_divisible(16 * scale),
+ kernel_size=3,
+ stride=2,
+ lr_mult=self.lr_mult_list[0])
+
+ self.blocks2 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[1],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks2"])
+ ])
+
+ self.blocks3 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[2],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks3"])
+ ])
+
+ self.blocks4 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[3],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks4"])
+ ])
+
+ self.blocks5 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[4],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks5"])
+ ])
+
+ self.blocks6 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[5],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks6"])
+ ])
+ self.out_channels = make_divisible(512 * scale)
+
+ if self.det:
+ mv_c = [16, 24, 56, 480]
+ self.out_channels = [
+ make_divisible(self.net_config["blocks3"][-1][2] * scale),
+ make_divisible(self.net_config["blocks4"][-1][2] * scale),
+ make_divisible(self.net_config["blocks5"][-1][2] * scale),
+ make_divisible(self.net_config["blocks6"][-1][2] * scale),
+ ]
+
+ self.layer_list = nn.LayerList([
+ nn.Conv2D(self.out_channels[0], int(mv_c[0] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[1], int(mv_c[1] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[2], int(mv_c[2] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[3], int(mv_c[3] * scale), 1, 1, 0)
+ ])
+ self.out_channels = [
+ int(mv_c[0] * scale), int(mv_c[1] * scale),
+ int(mv_c[2] * scale), int(mv_c[3] * scale)
+ ]
+
+ def forward(self, x):
+ out_list = []
+ x = self.conv1(x)
+
+ x = self.blocks2(x)
+ x = self.blocks3(x)
+ out_list.append(x)
+ x = self.blocks4(x)
+ out_list.append(x)
+ x = self.blocks5(x)
+ out_list.append(x)
+ x = self.blocks6(x)
+ out_list.append(x)
+
+ if self.det:
+ out_list[0] = self.layer_list[0](out_list[0])
+ out_list[1] = self.layer_list[1](out_list[1])
+ out_list[2] = self.layer_list[2](out_list[2])
+ out_list[3] = self.layer_list[3](out_list[3])
+ return out_list
+
+ if self.training:
+ x = F.adaptive_avg_pool2d(x, [1, 40])
+ else:
+ x = F.avg_pool2d(x, [3, 2])
+ return x
diff --git a/ppocr/modeling/backbones/rec_mv1_enhance.py b/ppocr/modeling/backbones/rec_mv1_enhance.py
index bb6af5e82cf13ac42d9a970787596a65986ade54..2d4efe720991618f33cbc42c0fb84bc795bc7437 100644
--- a/ppocr/modeling/backbones/rec_mv1_enhance.py
+++ b/ppocr/modeling/backbones/rec_mv1_enhance.py
@@ -108,6 +108,7 @@ class MobileNetV1Enhance(nn.Layer):
scale=0.5,
last_conv_stride=1,
last_pool_type='max',
+ last_pool_kernel_size=[3, 2],
**kwargs):
super().__init__()
self.scale = scale
@@ -214,7 +215,10 @@ class MobileNetV1Enhance(nn.Layer):
self.block_list = nn.Sequential(*self.block_list)
if last_pool_type == 'avg':
- self.pool = nn.AvgPool2D(kernel_size=2, stride=2, padding=0)
+ self.pool = nn.AvgPool2D(
+ kernel_size=last_pool_kernel_size,
+ stride=last_pool_kernel_size,
+ padding=0)
else:
self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = int(1024 * scale)
diff --git a/ppocr/modeling/backbones/rec_shallow_cnn.py b/ppocr/modeling/backbones/rec_shallow_cnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..544f108d26397421ae77ee025b15f31e319ab54c
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_shallow_cnn.py
@@ -0,0 +1,87 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/backbones/shallow_cnn.py
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+import numpy as np
+import paddle
+from paddle import ParamAttr
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle.nn import MaxPool2D
+from paddle.nn.initializer import KaimingNormal, Uniform, Constant
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ num_channels,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ num_groups=1):
+ super(ConvBNLayer, self).__init__()
+
+ self.conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False)
+
+ self.bn = nn.BatchNorm2D(
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(0, 1)),
+ bias_attr=ParamAttr(initializer=Constant(0)))
+ self.relu = nn.ReLU()
+
+ def forward(self, inputs):
+ y = self.conv(inputs)
+ y = self.bn(y)
+ y = self.relu(y)
+ return y
+
+
+class ShallowCNN(nn.Layer):
+ def __init__(self, in_channels=1, hidden_dim=512):
+ super().__init__()
+ assert isinstance(in_channels, int)
+ assert isinstance(hidden_dim, int)
+
+ self.conv1 = ConvBNLayer(
+ in_channels, 3, hidden_dim // 2, stride=1, padding=1)
+ self.conv2 = ConvBNLayer(
+ hidden_dim // 2, 3, hidden_dim, stride=1, padding=1)
+ self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
+ self.out_channels = hidden_dim
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = self.pool(x)
+
+ x = self.conv2(x)
+ x = self.pool(x)
+
+ return x
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
index c2c07f4476929d49237c8e9a10713f881f5f556b..ea865a2da148bc5a0afe9eea4f74c1f26d782649 100644
--- a/ppocr/modeling/backbones/rec_svtrnet.py
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -32,7 +32,7 @@ def drop_path(x, drop_prob=0., training=False):
"""
if drop_prob == 0. or not training:
return x
- keep_prob = paddle.to_tensor(1 - drop_prob)
+ keep_prob = paddle.to_tensor(1 - drop_prob, dtype=x.dtype)
shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
@@ -155,8 +155,9 @@ class Attention(nn.Layer):
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim**-0.5
+ self.dim = dim
+ self.head_dim = dim // num_heads
+ self.scale = qk_scale or self.head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
@@ -183,13 +184,9 @@ class Attention(nn.Layer):
self.mixer = mixer
def forward(self, x):
- if self.HW is not None:
- N = self.N
- C = self.C
- else:
- _, N, C = x.shape
- qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
- self.num_heads)).transpose((2, 0, 3, 1, 4))
+ qkv = self.qkv(x).reshape(
+ (0, -1, 3, self.num_heads, self.head_dim)).transpose(
+ (2, 0, 3, 1, 4))
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = (q.matmul(k.transpose((0, 1, 3, 2))))
@@ -198,7 +195,7 @@ class Attention(nn.Layer):
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
- x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, -1, self.dim))
x = self.proj(x)
x = self.proj_drop(x)
return x
diff --git a/ppocr/modeling/backbones/vqa_layoutlm.py b/ppocr/modeling/backbones/vqa_layoutlm.py
index acb1315cc0a588396549e5b8928bd2e4d3c769be..4357b5664587d74ecf0e1fc54a427a138a2f656e 100644
--- a/ppocr/modeling/backbones/vqa_layoutlm.py
+++ b/ppocr/modeling/backbones/vqa_layoutlm.py
@@ -54,18 +54,11 @@ class NLPBaseModel(nn.Layer):
if checkpoints is not None: # load the trained model
self.model = model_class.from_pretrained(checkpoints)
else: # load the pretrained-model
- pretrained_model_name = pretrained_model_dict[base_model_class][
- mode]
- if pretrained is True:
- base_model = base_model_class.from_pretrained(
- pretrained_model_name)
- else:
- base_model = base_model_class.from_pretrained(pretrained)
+ pretrained_model_name = pretrained_model_dict[base_model_class][mode]
if type == "ser":
- self.model = model_class(
- base_model, num_classes=kwargs["num_classes"], dropout=None)
+ self.model = model_class.from_pretrained(pretrained_model_name, num_classes=kwargs["num_classes"], dropout=0)
else:
- self.model = model_class(base_model, dropout=None)
+ self.model = model_class.from_pretrained(pretrained_model_name, dropout=0)
self.out_channels = 1
self.use_visual_backbone = True
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index 65afaf84f4453f2d4199371576ac71bb93a1e6d5..440d9e0293af2c92c3c3bfbba82b39a851fd1331 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -17,14 +17,13 @@ __all__ = ['build_head']
def build_head(config):
# det head
- from .det_db_head import DBHead
+ from .det_db_head import DBHead, PFHeadLocal
from .det_east_head import EASTHead
from .det_sast_head import SASTHead
from .det_pse_head import PSEHead
from .det_fce_head import FCEHead
from .e2e_pg_head import PGHead
from .det_ct_head import CT_Head
-
# rec head
from .rec_ctc_head import CTCHead
from .rec_att_head import AttentionHead
@@ -40,6 +39,7 @@ def build_head(config):
from .rec_visionlan_head import VLHead
from .rec_rfl_head import RFLHead
from .rec_can_head import CANHead
+ from .rec_satrn_head import SATRNHead
# cls head
from .cls_head import ClsHead
@@ -56,7 +56,7 @@ def build_head(config):
'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
'MultiHead', 'ABINetHead', 'TableMasterHead', 'SPINAttentionHead',
'VLHead', 'SLAHead', 'RobustScannerHead', 'CT_Head', 'RFLHead',
- 'DRRGHead', 'CANHead'
+ 'DRRGHead', 'CANHead', 'SATRNHead', 'PFHeadLocal'
]
if config['name'] == 'DRRGHead':
diff --git a/ppocr/modeling/heads/det_db_head.py b/ppocr/modeling/heads/det_db_head.py
index a686ae5ab0662ad31ddfd339bd1999c45c370cf0..8db14d7f6f043b53f2df3c929579c202358e5345 100644
--- a/ppocr/modeling/heads/det_db_head.py
+++ b/ppocr/modeling/heads/det_db_head.py
@@ -21,6 +21,7 @@ import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
+from ppocr.modeling.backbones.det_mobilenet_v3 import ConvBNLayer
def get_bias_attr(k):
@@ -31,7 +32,7 @@ def get_bias_attr(k):
class Head(nn.Layer):
- def __init__(self, in_channels, name_list, kernel_list=[3, 2, 2], **kwargs):
+ def __init__(self, in_channels, kernel_list=[3, 2, 2], **kwargs):
super(Head, self).__init__()
self.conv1 = nn.Conv2D(
@@ -48,6 +49,7 @@ class Head(nn.Layer):
bias_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1e-4)),
act='relu')
+
self.conv2 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=in_channels // 4,
@@ -72,13 +74,17 @@ class Head(nn.Layer):
initializer=paddle.nn.initializer.KaimingUniform()),
bias_attr=get_bias_attr(in_channels // 4), )
- def forward(self, x):
+ def forward(self, x, return_f=False):
x = self.conv1(x)
x = self.conv_bn1(x)
x = self.conv2(x)
x = self.conv_bn2(x)
+ if return_f is True:
+ f = x
x = self.conv3(x)
x = F.sigmoid(x)
+ if return_f is True:
+ return x, f
return x
@@ -93,16 +99,8 @@ class DBHead(nn.Layer):
def __init__(self, in_channels, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
- binarize_name_list = [
- 'conv2d_56', 'batch_norm_47', 'conv2d_transpose_0', 'batch_norm_48',
- 'conv2d_transpose_1', 'binarize'
- ]
- thresh_name_list = [
- 'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
- 'conv2d_transpose_3', 'thresh'
- ]
- self.binarize = Head(in_channels, binarize_name_list, **kwargs)
- self.thresh = Head(in_channels, thresh_name_list, **kwargs)
+ self.binarize = Head(in_channels, **kwargs)
+ self.thresh = Head(in_channels, **kwargs)
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
@@ -116,3 +114,41 @@ class DBHead(nn.Layer):
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
return {'maps': y}
+
+
+class LocalModule(nn.Layer):
+ def __init__(self, in_c, mid_c, use_distance=True):
+ super(self.__class__, self).__init__()
+ self.last_3 = ConvBNLayer(in_c + 1, mid_c, 3, 1, 1, act='relu')
+ self.last_1 = nn.Conv2D(mid_c, 1, 1, 1, 0)
+
+ def forward(self, x, init_map, distance_map):
+ outf = paddle.concat([init_map, x], axis=1)
+ # last Conv
+ out = self.last_1(self.last_3(outf))
+ return out
+
+
+class PFHeadLocal(DBHead):
+ def __init__(self, in_channels, k=50, mode='small', **kwargs):
+ super(PFHeadLocal, self).__init__(in_channels, k, **kwargs)
+ self.mode = mode
+
+ self.up_conv = nn.Upsample(scale_factor=2, mode="nearest", align_mode=1)
+ if self.mode == 'large':
+ self.cbn_layer = LocalModule(in_channels // 4, in_channels // 4)
+ elif self.mode == 'small':
+ self.cbn_layer = LocalModule(in_channels // 4, in_channels // 8)
+
+ def forward(self, x, targets=None):
+ shrink_maps, f = self.binarize(x, return_f=True)
+ base_maps = shrink_maps
+ cbn_maps = self.cbn_layer(self.up_conv(f), shrink_maps, None)
+ cbn_maps = F.sigmoid(cbn_maps)
+ if not self.training:
+ return {'maps': 0.5 * (base_maps + cbn_maps), 'cbn_maps': cbn_maps}
+
+ threshold_maps = self.thresh(x)
+ binary_maps = self.step_function(shrink_maps, threshold_maps)
+ y = paddle.concat([cbn_maps, threshold_maps, binary_maps], axis=1)
+ return {'maps': y, 'distance_maps': cbn_maps, 'cbn_maps': binary_maps}
diff --git a/ppocr/modeling/heads/proposal_local_graph.py b/ppocr/modeling/heads/proposal_local_graph.py
index 7887c4ff42f8ae9d1826a71f01208cd81bb2d52c..a48656135b2292f32c7285e767f8fea1a7318e08 100644
--- a/ppocr/modeling/heads/proposal_local_graph.py
+++ b/ppocr/modeling/heads/proposal_local_graph.py
@@ -40,7 +40,7 @@ def fill_hole(input_mask):
mask = np.zeros((h + 4, w + 4), np.uint8)
cv2.floodFill(canvas, mask, (0, 0), 1)
- canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool_)
return ~canvas | input_mask
diff --git a/ppocr/modeling/heads/rec_multi_head.py b/ppocr/modeling/heads/rec_multi_head.py
index 2f10e7bdf90025d3304128e720ce561c8bb269c1..0b4fa939eecad15c79f5e37384944720b1879205 100644
--- a/ppocr/modeling/heads/rec_multi_head.py
+++ b/ppocr/modeling/heads/rec_multi_head.py
@@ -25,12 +25,28 @@ import paddle.nn.functional as F
from ppocr.modeling.necks.rnn import Im2Seq, EncoderWithRNN, EncoderWithFC, SequenceEncoder, EncoderWithSVTR
from .rec_ctc_head import CTCHead
from .rec_sar_head import SARHead
+from .rec_nrtr_head import Transformer
+
+
+class FCTranspose(nn.Layer):
+ def __init__(self, in_channels, out_channels, only_transpose=False):
+ super().__init__()
+ self.only_transpose = only_transpose
+ if not self.only_transpose:
+ self.fc = nn.Linear(in_channels, out_channels, bias_attr=False)
+
+ def forward(self, x):
+ if self.only_transpose:
+ return x.transpose([0, 2, 1])
+ else:
+ return self.fc(x.transpose([0, 2, 1]))
class MultiHead(nn.Layer):
def __init__(self, in_channels, out_channels_list, **kwargs):
super().__init__()
self.head_list = kwargs.pop('head_list')
+
self.gtc_head = 'sar'
assert len(self.head_list) >= 2
for idx, head_name in enumerate(self.head_list):
@@ -40,12 +56,27 @@ class MultiHead(nn.Layer):
sar_args = self.head_list[idx][name]
self.sar_head = eval(name)(in_channels=in_channels, \
out_channels=out_channels_list['SARLabelDecode'], **sar_args)
+ elif name == 'NRTRHead':
+ gtc_args = self.head_list[idx][name]
+ max_text_length = gtc_args.get('max_text_length', 25)
+ nrtr_dim = gtc_args.get('nrtr_dim', 256)
+ num_decoder_layers = gtc_args.get('num_decoder_layers', 4)
+ self.before_gtc = nn.Sequential(
+ nn.Flatten(2), FCTranspose(in_channels, nrtr_dim))
+ self.gtc_head = Transformer(
+ d_model=nrtr_dim,
+ nhead=nrtr_dim // 32,
+ num_encoder_layers=-1,
+ beam_size=-1,
+ num_decoder_layers=num_decoder_layers,
+ max_len=max_text_length,
+ dim_feedforward=nrtr_dim * 4,
+ out_channels=out_channels_list['NRTRLabelDecode'])
elif name == 'CTCHead':
# ctc neck
self.encoder_reshape = Im2Seq(in_channels)
neck_args = self.head_list[idx][name]['Neck']
encoder_type = neck_args.pop('name')
- self.encoder = encoder_type
self.ctc_encoder = SequenceEncoder(in_channels=in_channels, \
encoder_type=encoder_type, **neck_args)
# ctc head
@@ -57,6 +88,7 @@ class MultiHead(nn.Layer):
'{} is not supported in MultiHead yet'.format(name))
def forward(self, x, targets=None):
+
ctc_encoder = self.ctc_encoder(x)
ctc_out = self.ctc_head(ctc_encoder, targets)
head_out = dict()
@@ -68,6 +100,7 @@ class MultiHead(nn.Layer):
if self.gtc_head == 'sar':
sar_out = self.sar_head(x, targets[1:])
head_out['sar'] = sar_out
- return head_out
else:
- return head_out
+ gtc_out = self.gtc_head(self.before_gtc(x), targets[1:])
+ head_out['nrtr'] = gtc_out
+ return head_out
diff --git a/ppocr/modeling/heads/rec_nrtr_head.py b/ppocr/modeling/heads/rec_nrtr_head.py
index bf9ef56145e6edfb15bd30235b4a62588396ba96..eb279400203b9ef173793bc0d90e5ab99701cb3a 100644
--- a/ppocr/modeling/heads/rec_nrtr_head.py
+++ b/ppocr/modeling/heads/rec_nrtr_head.py
@@ -162,7 +162,7 @@ class Transformer(nn.Layer):
memory = src
dec_seq = paddle.full((bs, 1), 2, dtype=paddle.int64)
dec_prob = paddle.full((bs, 1), 1., dtype=paddle.float32)
- for len_dec_seq in range(1, self.max_len):
+ for len_dec_seq in range(1, paddle.to_tensor(self.max_len)):
dec_seq_embed = self.embedding(dec_seq)
dec_seq_embed = self.positional_encoding(dec_seq_embed)
tgt_mask = self.generate_square_subsequent_mask(
@@ -304,7 +304,7 @@ class Transformer(nn.Layer):
inst_idx_to_position_map = get_inst_idx_to_tensor_position_map(
active_inst_idx_list)
# Decode
- for len_dec_seq in range(1, self.max_len):
+ for len_dec_seq in range(1, paddle.to_tensor(self.max_len)):
src_enc_copy = src_enc.clone()
active_inst_idx_list = beam_decode_step(
inst_dec_beams, len_dec_seq, src_enc_copy,
diff --git a/ppocr/modeling/heads/rec_robustscanner_head.py b/ppocr/modeling/heads/rec_robustscanner_head.py
index 7956059ecfe01f27db364d3d748d6af24dad0aac..550836bd401b0b8799e2afb9b185de8ed6b3d5b1 100644
--- a/ppocr/modeling/heads/rec_robustscanner_head.py
+++ b/ppocr/modeling/heads/rec_robustscanner_head.py
@@ -99,10 +99,11 @@ class DotProductAttentionLayer(nn.Layer):
logits = paddle.reshape(logits, [n, c, h, w])
if valid_ratios is not None:
# cal mask of attention weight
- for i, valid_ratio in enumerate(valid_ratios):
- valid_width = min(w, int(w * valid_ratio + 0.5))
- if valid_width < w:
- logits[i, :, :, valid_width:] = float('-inf')
+ with paddle.fluid.framework._stride_in_no_check_dy2st_diff():
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, int(w * valid_ratio + 0.5))
+ if valid_width < w:
+ logits[i, :, :, valid_width:] = float('-inf')
# reshape to (n, c, h, w)
logits = paddle.reshape(logits, [n, c, t])
diff --git a/ppocr/modeling/heads/rec_sar_head.py b/ppocr/modeling/heads/rec_sar_head.py
index 5e64cae85afafc555f2519ed6dd3f05eafff7ea2..11fe253b67f82ec321bcd3b51c39de318a7aec2f 100644
--- a/ppocr/modeling/heads/rec_sar_head.py
+++ b/ppocr/modeling/heads/rec_sar_head.py
@@ -276,7 +276,9 @@ class ParallelSARDecoder(BaseDecoder):
hf_c = holistic_feat.shape[-1]
holistic_feat = paddle.expand(
holistic_feat, shape=[bsz, seq_len, hf_c])
- y = self.prediction(paddle.concat((y, attn_feat, holistic_feat), 2))
+ y = self.prediction(
+ paddle.concat((y, attn_feat.astype(y.dtype),
+ holistic_feat.astype(y.dtype)), 2))
else:
y = self.prediction(attn_feat)
# bsz * (seq_len + 1) * num_classes
@@ -298,7 +300,7 @@ class ParallelSARDecoder(BaseDecoder):
lab_embedding = self.embedding(label)
# bsz * seq_len * emb_dim
- out_enc = out_enc.unsqueeze(1)
+ out_enc = out_enc.unsqueeze(1).astype(lab_embedding.dtype)
# bsz * 1 * emb_dim
in_dec = paddle.concat((out_enc, lab_embedding), axis=1)
# bsz * (seq_len + 1) * C
diff --git a/ppocr/modeling/heads/rec_satrn_head.py b/ppocr/modeling/heads/rec_satrn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b969c89693b677489b7191a9120f16d02c322802
--- /dev/null
+++ b/ppocr/modeling/heads/rec_satrn_head.py
@@ -0,0 +1,568 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/encoders/satrn_encoder.py
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/decoders/nrtr_decoder.py
+"""
+
+import math
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import ParamAttr, reshape, transpose
+from paddle.nn import Conv2D, BatchNorm, Linear, Dropout
+from paddle.nn import AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
+from paddle.nn.initializer import KaimingNormal, Uniform, Constant
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ num_channels,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ num_groups=1):
+ super(ConvBNLayer, self).__init__()
+
+ self.conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ bias_attr=False)
+
+ self.bn = nn.BatchNorm2D(
+ num_filters,
+ weight_attr=ParamAttr(initializer=Constant(1)),
+ bias_attr=ParamAttr(initializer=Constant(0)))
+ self.relu = nn.ReLU()
+
+ def forward(self, inputs):
+ y = self.conv(inputs)
+ y = self.bn(y)
+ y = self.relu(y)
+ return y
+
+
+class SATRNEncoderLayer(nn.Layer):
+ def __init__(self,
+ d_model=512,
+ d_inner=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.norm1 = nn.LayerNorm(d_model)
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.feed_forward = LocalityAwareFeedforward(
+ d_model, d_inner, dropout=dropout)
+
+ def forward(self, x, h, w, mask=None):
+ n, hw, c = x.shape
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+ residual = x
+ x = self.norm2(x)
+ x = x.transpose([0, 2, 1]).reshape([n, c, h, w])
+ x = self.feed_forward(x)
+ x = x.reshape([n, c, hw]).transpose([0, 2, 1])
+ x = residual + x
+ return x
+
+
+class LocalityAwareFeedforward(nn.Layer):
+ def __init__(
+ self,
+ d_in,
+ d_hid,
+ dropout=0.1, ):
+ super().__init__()
+ self.conv1 = ConvBNLayer(d_in, 1, d_hid, stride=1, padding=0)
+
+ self.depthwise_conv = ConvBNLayer(
+ d_hid, 3, d_hid, stride=1, padding=1, num_groups=d_hid)
+
+ self.conv2 = ConvBNLayer(d_hid, 1, d_in, stride=1, padding=0)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.depthwise_conv(x)
+ x = self.conv2(x)
+
+ return x
+
+
+class Adaptive2DPositionalEncoding(nn.Layer):
+ def __init__(self, d_hid=512, n_height=100, n_width=100, dropout=0.1):
+ super().__init__()
+
+ h_position_encoder = self._get_sinusoid_encoding_table(n_height, d_hid)
+ h_position_encoder = h_position_encoder.transpose([1, 0])
+ h_position_encoder = h_position_encoder.reshape([1, d_hid, n_height, 1])
+
+ w_position_encoder = self._get_sinusoid_encoding_table(n_width, d_hid)
+ w_position_encoder = w_position_encoder.transpose([1, 0])
+ w_position_encoder = w_position_encoder.reshape([1, d_hid, 1, n_width])
+
+ self.register_buffer('h_position_encoder', h_position_encoder)
+ self.register_buffer('w_position_encoder', w_position_encoder)
+
+ self.h_scale = self.scale_factor_generate(d_hid)
+ self.w_scale = self.scale_factor_generate(d_hid)
+ self.pool = nn.AdaptiveAvgPool2D(1)
+ self.dropout = nn.Dropout(p=dropout)
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = paddle.to_tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.reshape([1, -1])
+ pos_tensor = paddle.cast(
+ paddle.arange(n_position).unsqueeze(-1), 'float32')
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = paddle.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = paddle.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table
+
+ def scale_factor_generate(self, d_hid):
+ scale_factor = nn.Sequential(
+ nn.Conv2D(d_hid, d_hid, 1),
+ nn.ReLU(), nn.Conv2D(d_hid, d_hid, 1), nn.Sigmoid())
+
+ return scale_factor
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+
+ avg_pool = self.pool(x)
+
+ h_pos_encoding = \
+ self.h_scale(avg_pool) * self.h_position_encoder[:, :, :h, :]
+ w_pos_encoding = \
+ self.w_scale(avg_pool) * self.w_position_encoder[:, :, :, :w]
+
+ out = x + h_pos_encoding + w_pos_encoding
+
+ out = self.dropout(out)
+
+ return out
+
+
+class ScaledDotProductAttention(nn.Layer):
+ def __init__(self, temperature, attn_dropout=0.1):
+ super().__init__()
+ self.temperature = temperature
+ self.dropout = nn.Dropout(attn_dropout)
+
+ def forward(self, q, k, v, mask=None):
+ def masked_fill(x, mask, value):
+ y = paddle.full(x.shape, value, x.dtype)
+ return paddle.where(mask, y, x)
+
+ attn = paddle.matmul(q / self.temperature, k.transpose([0, 1, 3, 2]))
+ if mask is not None:
+ attn = masked_fill(attn, mask == 0, -1e9)
+ # attn = attn.masked_fill(mask == 0, float('-inf'))
+ # attn += mask
+
+ attn = self.dropout(F.softmax(attn, axis=-1))
+ output = paddle.matmul(attn, v)
+
+ return output, attn
+
+
+class MultiHeadAttention(nn.Layer):
+ def __init__(self,
+ n_head=8,
+ d_model=512,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.n_head = n_head
+ self.d_k = d_k
+ self.d_v = d_v
+
+ self.dim_k = n_head * d_k
+ self.dim_v = n_head * d_v
+
+ self.linear_q = nn.Linear(self.dim_k, self.dim_k, bias_attr=qkv_bias)
+ self.linear_k = nn.Linear(self.dim_k, self.dim_k, bias_attr=qkv_bias)
+ self.linear_v = nn.Linear(self.dim_v, self.dim_v, bias_attr=qkv_bias)
+
+ self.attention = ScaledDotProductAttention(d_k**0.5, dropout)
+
+ self.fc = nn.Linear(self.dim_v, d_model, bias_attr=qkv_bias)
+ self.proj_drop = nn.Dropout(dropout)
+
+ def forward(self, q, k, v, mask=None):
+ batch_size, len_q, _ = q.shape
+ _, len_k, _ = k.shape
+
+ q = self.linear_q(q).reshape([batch_size, len_q, self.n_head, self.d_k])
+ k = self.linear_k(k).reshape([batch_size, len_k, self.n_head, self.d_k])
+ v = self.linear_v(v).reshape([batch_size, len_k, self.n_head, self.d_v])
+
+ q, k, v = q.transpose([0, 2, 1, 3]), k.transpose(
+ [0, 2, 1, 3]), v.transpose([0, 2, 1, 3])
+
+ if mask is not None:
+ if mask.dim() == 3:
+ mask = mask.unsqueeze(1)
+ elif mask.dim() == 2:
+ mask = mask.unsqueeze(1).unsqueeze(1)
+
+ attn_out, _ = self.attention(q, k, v, mask=mask)
+
+ attn_out = attn_out.transpose([0, 2, 1, 3]).reshape(
+ [batch_size, len_q, self.dim_v])
+
+ attn_out = self.fc(attn_out)
+ attn_out = self.proj_drop(attn_out)
+
+ return attn_out
+
+
+class SATRNEncoder(nn.Layer):
+ def __init__(self,
+ n_layers=12,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ n_position=100,
+ d_inner=256,
+ dropout=0.1):
+ super().__init__()
+ self.d_model = d_model
+ self.position_enc = Adaptive2DPositionalEncoding(
+ d_hid=d_model,
+ n_height=n_position,
+ n_width=n_position,
+ dropout=dropout)
+ self.layer_stack = nn.LayerList([
+ SATRNEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def forward(self, feat, valid_ratios=None):
+ """
+ Args:
+ feat (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, T, D_m)`.
+ """
+ if valid_ratios is None:
+ valid_ratios = [1.0 for _ in range(feat.shape[0])]
+ feat = self.position_enc(feat)
+ n, c, h, w = feat.shape
+
+ mask = paddle.zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, :valid_width] = 1
+
+ mask = mask.reshape([n, h * w])
+ feat = feat.reshape([n, c, h * w])
+
+ output = feat.transpose([0, 2, 1])
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, h, w, mask)
+ output = self.layer_norm(output)
+
+ return output
+
+
+class PositionwiseFeedForward(nn.Layer):
+ def __init__(self, d_in, d_hid, dropout=0.1):
+ super().__init__()
+ self.w_1 = nn.Linear(d_in, d_hid)
+ self.w_2 = nn.Linear(d_hid, d_in)
+ self.act = nn.GELU()
+ self.dropout = nn.Dropout(dropout)
+
+ def forward(self, x):
+ x = self.w_1(x)
+ x = self.act(x)
+ x = self.w_2(x)
+ x = self.dropout(x)
+
+ return x
+
+
+class PositionalEncoding(nn.Layer):
+ def __init__(self, d_hid=512, n_position=200, dropout=0):
+ super().__init__()
+ self.dropout = nn.Dropout(p=dropout)
+
+ # Not a parameter
+ # Position table of shape (1, n_position, d_hid)
+ self.register_buffer(
+ 'position_table',
+ self._get_sinusoid_encoding_table(n_position, d_hid))
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = paddle.to_tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.reshape([1, -1])
+ pos_tensor = paddle.cast(
+ paddle.arange(n_position).unsqueeze(-1), 'float32')
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = paddle.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = paddle.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table.unsqueeze(0)
+
+ def forward(self, x):
+
+ x = x + self.position_table[:, :x.shape[1]].clone().detach()
+ return self.dropout(x)
+
+
+class TFDecoderLayer(nn.Layer):
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ operation_order=None):
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.norm3 = nn.LayerNorm(d_model)
+
+ self.self_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.enc_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.mlp = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn')
+ assert self.operation_order in [
+ ('norm', 'self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn', 'norm')
+ ]
+
+ def forward(self,
+ dec_input,
+ enc_output,
+ self_attn_mask=None,
+ dec_enc_attn_mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'enc_dec_attn', 'norm',
+ 'ffn', 'norm'):
+ dec_attn_out = self.self_attn(dec_input, dec_input, dec_input,
+ self_attn_mask)
+ dec_attn_out += dec_input
+ dec_attn_out = self.norm1(dec_attn_out)
+
+ enc_dec_attn_out = self.enc_attn(dec_attn_out, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+ enc_dec_attn_out = self.norm2(enc_dec_attn_out)
+
+ mlp_out = self.mlp(enc_dec_attn_out)
+ mlp_out += enc_dec_attn_out
+ mlp_out = self.norm3(mlp_out)
+ elif self.operation_order == ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn'):
+ dec_input_norm = self.norm1(dec_input)
+ dec_attn_out = self.self_attn(dec_input_norm, dec_input_norm,
+ dec_input_norm, self_attn_mask)
+ dec_attn_out += dec_input
+
+ enc_dec_attn_in = self.norm2(dec_attn_out)
+ enc_dec_attn_out = self.enc_attn(enc_dec_attn_in, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+
+ mlp_out = self.mlp(self.norm3(enc_dec_attn_out))
+ mlp_out += enc_dec_attn_out
+
+ return mlp_out
+
+
+class SATRNDecoder(nn.Layer):
+ def __init__(self,
+ n_layers=6,
+ d_embedding=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ d_inner=256,
+ n_position=200,
+ dropout=0.1,
+ num_classes=93,
+ max_seq_len=40,
+ start_idx=1,
+ padding_idx=92):
+ super().__init__()
+
+ self.padding_idx = padding_idx
+ self.start_idx = start_idx
+ self.max_seq_len = max_seq_len
+
+ self.trg_word_emb = nn.Embedding(
+ num_classes, d_embedding, padding_idx=padding_idx)
+
+ self.position_enc = PositionalEncoding(
+ d_embedding, n_position=n_position)
+ self.dropout = nn.Dropout(p=dropout)
+
+ self.layer_stack = nn.LayerList([
+ TFDecoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-6)
+
+ pred_num_class = num_classes - 1 # ignore padding_idx
+ self.classifier = nn.Linear(d_model, pred_num_class)
+
+ @staticmethod
+ def get_pad_mask(seq, pad_idx):
+
+ return (seq != pad_idx).unsqueeze(-2)
+
+ @staticmethod
+ def get_subsequent_mask(seq):
+ """For masking out the subsequent info."""
+ len_s = seq.shape[1]
+ subsequent_mask = 1 - paddle.triu(
+ paddle.ones((len_s, len_s)), diagonal=1)
+ subsequent_mask = paddle.cast(subsequent_mask.unsqueeze(0), 'bool')
+
+ return subsequent_mask
+
+ def _attention(self, trg_seq, src, src_mask=None):
+ trg_embedding = self.trg_word_emb(trg_seq)
+ trg_pos_encoded = self.position_enc(trg_embedding)
+ tgt = self.dropout(trg_pos_encoded)
+
+ trg_mask = self.get_pad_mask(
+ trg_seq,
+ pad_idx=self.padding_idx) & self.get_subsequent_mask(trg_seq)
+ output = tgt
+ for dec_layer in self.layer_stack:
+ output = dec_layer(
+ output,
+ src,
+ self_attn_mask=trg_mask,
+ dec_enc_attn_mask=src_mask)
+ output = self.layer_norm(output)
+
+ return output
+
+ def _get_mask(self, logit, valid_ratios):
+ N, T, _ = logit.shape
+ mask = None
+ if valid_ratios is not None:
+ mask = paddle.zeros((N, T))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def forward_train(self, feat, out_enc, targets, valid_ratio):
+ src_mask = self._get_mask(out_enc, valid_ratio)
+ attn_output = self._attention(targets, out_enc, src_mask=src_mask)
+ outputs = self.classifier(attn_output)
+
+ return outputs
+
+ def forward_test(self, feat, out_enc, valid_ratio):
+
+ src_mask = self._get_mask(out_enc, valid_ratio)
+ N = out_enc.shape[0]
+ init_target_seq = paddle.full(
+ (N, self.max_seq_len + 1), self.padding_idx, dtype='int64')
+ # bsz * seq_len
+ init_target_seq[:, 0] = self.start_idx
+
+ outputs = []
+ for step in range(0, paddle.to_tensor(self.max_seq_len)):
+ decoder_output = self._attention(
+ init_target_seq, out_enc, src_mask=src_mask)
+ # bsz * seq_len * C
+ step_result = F.softmax(
+ self.classifier(decoder_output[:, step, :]), axis=-1)
+ # bsz * num_classes
+ outputs.append(step_result)
+ step_max_index = paddle.argmax(step_result, axis=-1)
+ init_target_seq[:, step + 1] = step_max_index
+
+ outputs = paddle.stack(outputs, axis=1)
+
+ return outputs
+
+ def forward(self, feat, out_enc, targets=None, valid_ratio=None):
+ if self.training:
+ return self.forward_train(feat, out_enc, targets, valid_ratio)
+ else:
+ return self.forward_test(feat, out_enc, valid_ratio)
+
+
+class SATRNHead(nn.Layer):
+ def __init__(self, enc_cfg, dec_cfg, **kwargs):
+ super(SATRNHead, self).__init__()
+
+ # encoder module
+ self.encoder = SATRNEncoder(**enc_cfg)
+
+ # decoder module
+ self.decoder = SATRNDecoder(**dec_cfg)
+
+ def forward(self, feat, targets=None):
+
+ if targets is not None:
+ targets, valid_ratio = targets
+ else:
+ targets, valid_ratio = None, None
+ holistic_feat = self.encoder(feat, valid_ratio) # bsz c
+
+ final_out = self.decoder(feat, holistic_feat, targets, valid_ratio)
+
+ return final_out
diff --git a/ppocr/modeling/heads/sr_rensnet_transformer.py b/ppocr/modeling/heads/sr_rensnet_transformer.py
index 654f3fca5486229c176246237708c4cf6a8da9ec..df0d0c9299170993fb881714c1f07b618cee9612 100644
--- a/ppocr/modeling/heads/sr_rensnet_transformer.py
+++ b/ppocr/modeling/heads/sr_rensnet_transformer.py
@@ -78,7 +78,7 @@ class MultiHeadedAttention(nn.Layer):
def forward(self, query, key, value, mask=None, attention_map=None):
if mask is not None:
mask = mask.unsqueeze(1)
- nbatches = query.shape[0]
+ nbatches = paddle.shape(query)[0]
query, key, value = \
[paddle.transpose(l(x).reshape([nbatches, -1, self.h, self.d_k]), [0,2,1,3])
diff --git a/ppocr/modeling/necks/db_fpn.py b/ppocr/modeling/necks/db_fpn.py
index 8c3f52a331db5daafab2a38c0a441edd44eb141d..0f5b826bfb023895d6216605e2b2faf82023fa80 100644
--- a/ppocr/modeling/necks/db_fpn.py
+++ b/ppocr/modeling/necks/db_fpn.py
@@ -22,6 +22,7 @@ import paddle.nn.functional as F
from paddle import ParamAttr
import os
import sys
+from ppocr.modeling.necks.intracl import IntraCLBlock
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
@@ -228,6 +229,13 @@ class RSEFPN(nn.Layer):
self.out_channels = out_channels
self.ins_conv = nn.LayerList()
self.inp_conv = nn.LayerList()
+ self.intracl = False
+ if 'intracl' in kwargs.keys() and kwargs['intracl'] is True:
+ self.intracl = kwargs['intracl']
+ self.incl1 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl2 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl3 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl4 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
for i in range(len(in_channels)):
self.ins_conv.append(
@@ -263,6 +271,12 @@ class RSEFPN(nn.Layer):
p3 = self.inp_conv[1](out3)
p2 = self.inp_conv[0](out2)
+ if self.intracl is True:
+ p5 = self.incl4(p5)
+ p4 = self.incl3(p4)
+ p3 = self.incl2(p3)
+ p2 = self.incl1(p2)
+
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
@@ -329,6 +343,14 @@ class LKPAN(nn.Layer):
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False))
+ self.intracl = False
+ if 'intracl' in kwargs.keys() and kwargs['intracl'] is True:
+ self.intracl = kwargs['intracl']
+ self.incl1 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl2 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl3 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl4 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+
def forward(self, x):
c2, c3, c4, c5 = x
@@ -358,6 +380,12 @@ class LKPAN(nn.Layer):
p4 = self.pan_lat_conv[2](pan4)
p5 = self.pan_lat_conv[3](pan5)
+ if self.intracl is True:
+ p5 = self.incl4(p5)
+ p4 = self.incl3(p4)
+ p3 = self.incl2(p3)
+ p2 = self.incl1(p2)
+
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
@@ -424,4 +452,4 @@ class ASFBlock(nn.Layer):
out_list = []
for i in range(self.out_features_num):
out_list.append(attention_scores[:, i:i + 1] * features_list[i])
- return paddle.concat(out_list, axis=1)
+ return paddle.concat(out_list, axis=1)
\ No newline at end of file
diff --git a/ppocr/modeling/necks/intracl.py b/ppocr/modeling/necks/intracl.py
new file mode 100644
index 0000000000000000000000000000000000000000..205b52e35f04e59d35ae6a89bfe1b920a3890d5f
--- /dev/null
+++ b/ppocr/modeling/necks/intracl.py
@@ -0,0 +1,118 @@
+import paddle
+from paddle import nn
+
+# refer from: https://github.com/ViTAE-Transformer/I3CL/blob/736c80237f66d352d488e83b05f3e33c55201317/mmdet/models/detectors/intra_cl_module.py
+
+
+class IntraCLBlock(nn.Layer):
+ def __init__(self, in_channels=96, reduce_factor=4):
+ super(IntraCLBlock, self).__init__()
+ self.channels = in_channels
+ self.rf = reduce_factor
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+ self.conv1x1_reduce_channel = nn.Conv2D(
+ self.channels,
+ self.channels // self.rf,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ self.conv1x1_return_channel = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ self.v_layer_7x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(7, 1),
+ stride=(1, 1),
+ padding=(3, 0))
+ self.v_layer_5x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(5, 1),
+ stride=(1, 1),
+ padding=(2, 0))
+ self.v_layer_3x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(3, 1),
+ stride=(1, 1),
+ padding=(1, 0))
+
+ self.q_layer_1x7 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 7),
+ stride=(1, 1),
+ padding=(0, 3))
+ self.q_layer_1x5 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 5),
+ stride=(1, 1),
+ padding=(0, 2))
+ self.q_layer_1x3 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 3),
+ stride=(1, 1),
+ padding=(0, 1))
+
+ # base
+ self.c_layer_7x7 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(7, 7),
+ stride=(1, 1),
+ padding=(3, 3))
+ self.c_layer_5x5 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(5, 5),
+ stride=(1, 1),
+ padding=(2, 2))
+ self.c_layer_3x3 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=(1, 1))
+
+ self.bn = nn.BatchNorm2D(self.channels)
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ x_new = self.conv1x1_reduce_channel(x)
+
+ x_7_c = self.c_layer_7x7(x_new)
+ x_7_v = self.v_layer_7x1(x_new)
+ x_7_q = self.q_layer_1x7(x_new)
+ x_7 = x_7_c + x_7_v + x_7_q
+
+ x_5_c = self.c_layer_5x5(x_7)
+ x_5_v = self.v_layer_5x1(x_7)
+ x_5_q = self.q_layer_1x5(x_7)
+ x_5 = x_5_c + x_5_v + x_5_q
+
+ x_3_c = self.c_layer_3x3(x_5)
+ x_3_v = self.v_layer_3x1(x_5)
+ x_3_q = self.q_layer_1x3(x_5)
+ x_3 = x_3_c + x_3_v + x_3_q
+
+ x_relation = self.conv1x1_return_channel(x_3)
+
+ x_relation = self.bn(x_relation)
+ x_relation = self.relu(x_relation)
+
+ return x + x_relation
+
+
+def build_intraclblock_list(num_block):
+ IntraCLBlock_list = nn.LayerList()
+ for i in range(num_block):
+ IntraCLBlock_list.append(IntraCLBlock())
+
+ return IntraCLBlock_list
\ No newline at end of file
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index 33be9400b34cb535d260881748e179c3df106caa..a195a6217ae1246316ef441d7f4772ca296914c9 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -47,8 +47,10 @@ class EncoderWithRNN(nn.Layer):
x, _ = self.lstm(x)
return x
+
class BidirectionalLSTM(nn.Layer):
- def __init__(self, input_size,
+ def __init__(self,
+ input_size,
hidden_size,
output_size=None,
num_layers=1,
@@ -58,39 +60,46 @@ class BidirectionalLSTM(nn.Layer):
with_linear=False):
super(BidirectionalLSTM, self).__init__()
self.with_linear = with_linear
- self.rnn = nn.LSTM(input_size,
- hidden_size,
- num_layers=num_layers,
- dropout=dropout,
- direction=direction,
- time_major=time_major)
+ self.rnn = nn.LSTM(
+ input_size,
+ hidden_size,
+ num_layers=num_layers,
+ dropout=dropout,
+ direction=direction,
+ time_major=time_major)
# text recognition the specified structure LSTM with linear
if self.with_linear:
self.linear = nn.Linear(hidden_size * 2, output_size)
def forward(self, input_feature):
- recurrent, _ = self.rnn(input_feature) # batch_size x T x input_size -> batch_size x T x (2*hidden_size)
+ recurrent, _ = self.rnn(
+ input_feature
+ ) # batch_size x T x input_size -> batch_size x T x (2*hidden_size)
if self.with_linear:
- output = self.linear(recurrent) # batch_size x T x output_size
+ output = self.linear(recurrent) # batch_size x T x output_size
return output
return recurrent
+
class EncoderWithCascadeRNN(nn.Layer):
- def __init__(self, in_channels, hidden_size, out_channels, num_layers=2, with_linear=False):
+ def __init__(self,
+ in_channels,
+ hidden_size,
+ out_channels,
+ num_layers=2,
+ with_linear=False):
super(EncoderWithCascadeRNN, self).__init__()
self.out_channels = out_channels[-1]
- self.encoder = nn.LayerList(
- [BidirectionalLSTM(
- in_channels if i == 0 else out_channels[i - 1],
- hidden_size,
- output_size=out_channels[i],
- num_layers=1,
- direction='bidirectional',
- with_linear=with_linear)
- for i in range(num_layers)]
- )
-
+ self.encoder = nn.LayerList([
+ BidirectionalLSTM(
+ in_channels if i == 0 else out_channels[i - 1],
+ hidden_size,
+ output_size=out_channels[i],
+ num_layers=1,
+ direction='bidirectional',
+ with_linear=with_linear) for i in range(num_layers)
+ ])
def forward(self, x):
for i, l in enumerate(self.encoder):
@@ -130,12 +139,17 @@ class EncoderWithSVTR(nn.Layer):
drop_rate=0.1,
attn_drop_rate=0.1,
drop_path=0.,
+ kernel_size=[3, 3],
qk_scale=None):
super(EncoderWithSVTR, self).__init__()
self.depth = depth
self.use_guide = use_guide
self.conv1 = ConvBNLayer(
- in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ in_channels,
+ in_channels // 8,
+ kernel_size=kernel_size,
+ padding=[kernel_size[0] // 2, kernel_size[1] // 2],
+ act=nn.Swish)
self.conv2 = ConvBNLayer(
in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
@@ -161,7 +175,11 @@ class EncoderWithSVTR(nn.Layer):
hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
# last conv-nxn, the input is concat of input tensor and conv3 output tensor
self.conv4 = ConvBNLayer(
- 2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ 2 * in_channels,
+ in_channels // 8,
+ kernel_size=kernel_size,
+ padding=[kernel_size[0] // 2, kernel_size[1] // 2],
+ act=nn.Swish)
self.conv1x1 = ConvBNLayer(
in_channels // 8, dims, kernel_size=1, act=nn.Swish)
diff --git a/ppocr/modeling/transforms/gaspin_transformer.py b/ppocr/modeling/transforms/gaspin_transformer.py
index f4719eb2162a02141620586bcb6a849ae16f3b62..7afa21609336c6914c92b2d7b2b291f7e0fbffdd 100644
--- a/ppocr/modeling/transforms/gaspin_transformer.py
+++ b/ppocr/modeling/transforms/gaspin_transformer.py
@@ -280,5 +280,13 @@ class GA_SPIN_Transformer(nn.Layer):
x = self.sp_net(x, sp_weight, offsets, lambda_color)
if self.stn:
+ is_fp16 = False
+ if build_P_prime_reshape.dtype != paddle.float32:
+ data_type = build_P_prime_reshape.dtype
+ x = x.cast(paddle.float32)
+ build_P_prime_reshape = build_P_prime_reshape.cast(paddle.float32)
+ is_fp16 = True
x = F.grid_sample(x=x, grid=build_P_prime_reshape, padding_mode='border')
+ if is_fp16:
+ x = x.cast(data_type)
return x
diff --git a/ppocr/modeling/transforms/tbsrn.py b/ppocr/modeling/transforms/tbsrn.py
index ee119003600b0515feb6fd1049e2c91565528b7d..e3e77bd36aa1047812a0e41de30a1541c984b2a6 100644
--- a/ppocr/modeling/transforms/tbsrn.py
+++ b/ppocr/modeling/transforms/tbsrn.py
@@ -45,21 +45,24 @@ def positionalencoding2d(d_model, height, width):
pe = paddle.zeros([d_model, height, width])
# Each dimension use half of d_model
d_model = int(d_model / 2)
- div_term = paddle.exp(paddle.arange(0., d_model, 2) *
- -(math.log(10000.0) / d_model))
+ div_term = paddle.exp(
+ paddle.arange(0., d_model, 2, dtype='int64') * -(math.log(10000.0) / d_model))
pos_w = paddle.arange(0., width, dtype='float32').unsqueeze(1)
pos_h = paddle.arange(0., height, dtype='float32').unsqueeze(1)
- pe[0:d_model:2, :, :] = paddle.sin(pos_w * div_term).transpose([1, 0]).unsqueeze(1).tile([1, height, 1])
- pe[1:d_model:2, :, :] = paddle.cos(pos_w * div_term).transpose([1, 0]).unsqueeze(1).tile([1, height, 1])
- pe[d_model::2, :, :] = paddle.sin(pos_h * div_term).transpose([1, 0]).unsqueeze(2).tile([1, 1, width])
- pe[d_model + 1::2, :, :] = paddle.cos(pos_h * div_term).transpose([1, 0]).unsqueeze(2).tile([1, 1, width])
+ pe[0:d_model:2, :, :] = paddle.sin(pos_w * div_term).transpose(
+ [1, 0]).unsqueeze(1).tile([1, height, 1])
+ pe[1:d_model:2, :, :] = paddle.cos(pos_w * div_term).transpose(
+ [1, 0]).unsqueeze(1).tile([1, height, 1])
+ pe[d_model::2, :, :] = paddle.sin(pos_h * div_term).transpose(
+ [1, 0]).unsqueeze(2).tile([1, 1, width])
+ pe[d_model + 1::2, :, :] = paddle.cos(pos_h * div_term).transpose(
+ [1, 0]).unsqueeze(2).tile([1, 1, width])
return pe
class FeatureEnhancer(nn.Layer):
-
def __init__(self):
super(FeatureEnhancer, self).__init__()
@@ -77,13 +80,16 @@ class FeatureEnhancer(nn.Layer):
global_info: (batch, embedding_size, 1, 1)
conv_feature: (batch, channel, H, W)
'''
- batch = conv_feature.shape[0]
- position2d = positionalencoding2d(64, 16, 64).cast('float32').unsqueeze(0).reshape([1, 64, 1024])
+ batch = paddle.shape(conv_feature)[0]
+ position2d = positionalencoding2d(
+ 64, 16, 64).cast('float32').unsqueeze(0).reshape([1, 64, 1024])
position2d = position2d.tile([batch, 1, 1])
- conv_feature = paddle.concat([conv_feature, position2d], 1) # batch, 128(64+64), 32, 128
+ conv_feature = paddle.concat([conv_feature, position2d],
+ 1) # batch, 128(64+64), 32, 128
result = conv_feature.transpose([0, 2, 1])
origin_result = result
- result = self.mul_layernorm1(origin_result + self.multihead(result, result, result, mask=None)[0])
+ result = self.mul_layernorm1(origin_result + self.multihead(
+ result, result, result, mask=None)[0])
origin_result = result
result = self.mul_layernorm3(origin_result + self.pff(result))
result = self.linear(result)
@@ -124,23 +130,35 @@ class TBSRN(nn.Layer):
assert math.log(scale_factor, 2) % 1 == 0
upsample_block_num = int(math.log(scale_factor, 2))
self.block1 = nn.Sequential(
- nn.Conv2D(in_planes, 2 * hidden_units, kernel_size=9, padding=4),
+ nn.Conv2D(
+ in_planes, 2 * hidden_units, kernel_size=9, padding=4),
nn.PReLU()
# nn.ReLU()
)
self.srb_nums = srb_nums
for i in range(srb_nums):
- setattr(self, 'block%d' % (i + 2), RecurrentResidualBlock(2 * hidden_units))
-
- setattr(self, 'block%d' % (srb_nums + 2),
- nn.Sequential(
- nn.Conv2D(2 * hidden_units, 2 * hidden_units, kernel_size=3, padding=1),
- nn.BatchNorm2D(2 * hidden_units)
- ))
+ setattr(self, 'block%d' % (i + 2),
+ RecurrentResidualBlock(2 * hidden_units))
+
+ setattr(
+ self,
+ 'block%d' % (srb_nums + 2),
+ nn.Sequential(
+ nn.Conv2D(
+ 2 * hidden_units,
+ 2 * hidden_units,
+ kernel_size=3,
+ padding=1),
+ nn.BatchNorm2D(2 * hidden_units)))
# self.non_local = NonLocalBlock2D(64, 64)
- block_ = [UpsampleBLock(2 * hidden_units, 2) for _ in range(upsample_block_num)]
- block_.append(nn.Conv2D(2 * hidden_units, in_planes, kernel_size=9, padding=4))
+ block_ = [
+ UpsampleBLock(2 * hidden_units, 2)
+ for _ in range(upsample_block_num)
+ ]
+ block_.append(
+ nn.Conv2D(
+ 2 * hidden_units, in_planes, kernel_size=9, padding=4))
setattr(self, 'block%d' % (srb_nums + 3), nn.Sequential(*block_))
self.tps_inputsize = [height // scale_factor, width // scale_factor]
tps_outputsize = [height // scale_factor, width // scale_factor]
@@ -164,7 +182,8 @@ class TBSRN(nn.Layer):
self.english_dict = {}
for index in range(len(self.english_alphabet)):
self.english_dict[self.english_alphabet[index]] = index
- transformer = Transformer(alphabet='-0123456789abcdefghijklmnopqrstuvwxyz')
+ transformer = Transformer(
+ alphabet='-0123456789abcdefghijklmnopqrstuvwxyz')
self.transformer = transformer
for param in self.transformer.parameters():
param.trainable = False
@@ -219,10 +238,10 @@ class TBSRN(nn.Layer):
# add transformer
label = [str_filt(i, 'lower') + '-' for i in x[2]]
length_tensor, input_tensor, text_gt = self.label_encoder(label)
- hr_pred, word_attention_map_gt, hr_correct_list = self.transformer(hr_img, length_tensor,
- input_tensor)
- sr_pred, word_attention_map_pred, sr_correct_list = self.transformer(sr_img, length_tensor,
- input_tensor)
+ hr_pred, word_attention_map_gt, hr_correct_list = self.transformer(
+ hr_img, length_tensor, input_tensor)
+ sr_pred, word_attention_map_pred, sr_correct_list = self.transformer(
+ sr_img, length_tensor, input_tensor)
output["hr_img"] = hr_img
output["hr_pred"] = hr_pred
output["text_gt"] = text_gt
@@ -257,8 +276,8 @@ class RecurrentResidualBlock(nn.Layer):
residual = self.conv2(residual)
residual = self.bn2(residual)
- size = residual.shape
+ size = paddle.shape(residual)
residual = residual.reshape([size[0], size[1], -1])
residual = self.feature_enhancer(residual)
residual = residual.reshape([size[0], size[1], size[2], size[3]])
- return x + residual
\ No newline at end of file
+ return x + residual
diff --git a/ppocr/modeling/transforms/tps.py b/ppocr/modeling/transforms/tps.py
index 9bdab0f85112b90d8da959dce4e258188a812052..ac5ce998b00c92042517f48b3bed81756c230b51 100644
--- a/ppocr/modeling/transforms/tps.py
+++ b/ppocr/modeling/transforms/tps.py
@@ -304,5 +304,14 @@ class TPS(nn.Layer):
batch_P_prime = self.grid_generator(batch_C_prime, image.shape[2:])
batch_P_prime = batch_P_prime.reshape(
[-1, image.shape[2], image.shape[3], 2])
+ is_fp16 = False
+ if batch_P_prime.dtype != paddle.float32:
+ data_type = batch_P_prime.dtype
+ image = image.cast(paddle.float32)
+ batch_P_prime = batch_P_prime.cast(paddle.float32)
+ is_fp16 = True
batch_I_r = F.grid_sample(x=image, grid=batch_P_prime)
+ if is_fp16:
+ batch_I_r = batch_I_r.cast(data_type)
+
return batch_I_r
diff --git a/ppocr/modeling/transforms/tps_spatial_transformer.py b/ppocr/modeling/transforms/tps_spatial_transformer.py
index e7ec2c848f192d766722f824962a7f8d0fed41f9..35b1d8bf7164a1a0dd6e5905dc0c91112008c3e0 100644
--- a/ppocr/modeling/transforms/tps_spatial_transformer.py
+++ b/ppocr/modeling/transforms/tps_spatial_transformer.py
@@ -29,12 +29,28 @@ import itertools
def grid_sample(input, grid, canvas=None):
input.stop_gradient = False
+
+ is_fp16 = False
+ if grid.dtype != paddle.float32:
+ data_type = grid.dtype
+ input = input.cast(paddle.float32)
+ grid = grid.cast(paddle.float32)
+ is_fp16 = True
output = F.grid_sample(input, grid)
+ if is_fp16:
+ output = output.cast(data_type)
+ grid = grid.cast(data_type)
+
if canvas is None:
return output
else:
input_mask = paddle.ones(shape=input.shape)
+ if is_fp16:
+ input_mask = input_mask.cast(paddle.float32)
+ grid = grid.cast(paddle.float32)
output_mask = F.grid_sample(input_mask, grid)
+ if is_fp16:
+ output_mask = output_mask.cast(data_type)
padded_output = output * output_mask + canvas * (1 - output_mask)
return padded_output
@@ -140,7 +156,9 @@ class TPSSpatialTransformer(nn.Layer):
padding_matrix = paddle.expand(
self.padding_matrix, shape=[batch_size, 3, 2])
- Y = paddle.concat([source_control_points, padding_matrix], 1)
+ Y = paddle.concat([
+ source_control_points.astype(padding_matrix.dtype), padding_matrix
+ ], 1)
mapping_matrix = paddle.matmul(self.inverse_kernel, Y)
source_coordinate = paddle.matmul(self.target_coordinate_repr,
mapping_matrix)
@@ -153,4 +171,4 @@ class TPSSpatialTransformer(nn.Layer):
# the input to grid_sample is normalized [-1, 1], but what we get is [0, 1]
grid = 2.0 * grid - 1.0
output_maps = grid_sample(input, grid, canvas=None)
- return output_maps, source_coordinate
\ No newline at end of file
+ return output_maps, source_coordinate
diff --git a/ppocr/optimizer/optimizer.py b/ppocr/optimizer/optimizer.py
index 144f011c79ec2303b7fbc73ac078afe3ce92c255..ffe72d7db309ab832a258dcc73916f9fa4485c2b 100644
--- a/ppocr/optimizer/optimizer.py
+++ b/ppocr/optimizer/optimizer.py
@@ -84,8 +84,7 @@ class Adam(object):
if self.group_lr:
if self.training_step == 'LF_2':
import paddle
- if isinstance(model, paddle.fluid.dygraph.parallel.
- DataParallel): # multi gpu
+ if isinstance(model, paddle.DataParallel): # multi gpu
mlm = model._layers.head.MLM_VRM.MLM.parameters()
pre_mlm_pp = model._layers.head.MLM_VRM.Prediction.pp_share.parameters(
)
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index 36a3152f2f2d68ed0884bd415844d209d850f5ca..c89345e70b3dcf22b292ebf1250bf3f258a3355c 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -28,7 +28,7 @@ from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, NRTRLabelDecode, SARLabelDecode, \
SEEDLabelDecode, PRENLabelDecode, ViTSTRLabelDecode, ABINetLabelDecode, \
- SPINLabelDecode, VLLabelDecode, RFLLabelDecode
+ SPINLabelDecode, VLLabelDecode, RFLLabelDecode, SATRNLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess, DistillationSerPostProcess
@@ -52,7 +52,8 @@ def build_post_process(config, global_config=None):
'TableMasterLabelDecode', 'SPINLabelDecode',
'DistillationSerPostProcess', 'DistillationRePostProcess',
'VLLabelDecode', 'PicoDetPostProcess', 'CTPostProcess',
- 'RFLLabelDecode', 'DRRGPostprocess', 'CANLabelDecode'
+ 'RFLLabelDecode', 'DRRGPostprocess', 'CANLabelDecode',
+ 'SATRNLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/db_postprocess.py b/ppocr/postprocess/db_postprocess.py
index dfe107816c195b36bf06568843b008bf66ff24c7..244825b76a47162419b4ae68103b182331be1791 100755
--- a/ppocr/postprocess/db_postprocess.py
+++ b/ppocr/postprocess/db_postprocess.py
@@ -144,9 +144,9 @@ class DBPostProcess(object):
np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(
np.round(box[:, 1] / height * dest_height), 0, dest_height)
- boxes.append(box.astype(np.int16))
+ boxes.append(box.astype("int32"))
scores.append(score)
- return np.array(boxes, dtype=np.int16), scores
+ return np.array(boxes, dtype="int32"), scores
def unclip(self, box, unclip_ratio):
poly = Polygon(box)
@@ -185,15 +185,15 @@ class DBPostProcess(object):
'''
h, w = bitmap.shape[:2]
box = _box.copy()
- xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
- xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
- ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
- ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
+ xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
- cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
def box_score_slow(self, bitmap, contour):
@@ -214,7 +214,7 @@ class DBPostProcess(object):
contour[:, 0] = contour[:, 0] - xmin
contour[:, 1] = contour[:, 1] - ymin
- cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
+ cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
def __call__(self, outs_dict, shape_list):
diff --git a/ppocr/postprocess/drrg_postprocess.py b/ppocr/postprocess/drrg_postprocess.py
index 353081c9d4d0fa1d04d995c84445445767276cc8..56fd034f7c18ee31e8af6c5c72461bcd98021809 100644
--- a/ppocr/postprocess/drrg_postprocess.py
+++ b/ppocr/postprocess/drrg_postprocess.py
@@ -68,7 +68,7 @@ def graph_propagation(edges, scores, text_comps, edge_len_thr=50.):
score_dict[edge[0], edge[1]] = scores[i]
nodes = np.sort(np.unique(edges.flatten()))
- mapping = -1 * np.ones((np.max(nodes) + 1), dtype=np.int)
+ mapping = -1 * np.ones((np.max(nodes) + 1), dtype=np.int32)
mapping[nodes] = np.arange(nodes.shape[0])
order_inds = mapping[edges]
vertices = [Node(node) for node in nodes]
@@ -93,9 +93,8 @@ def connected_components(nodes, score_dict, link_thr):
while node_queue:
node = node_queue.pop(0)
neighbors = set([
- neighbor for neighbor in node.links
- if score_dict[tuple(sorted([node.ind, neighbor.ind]))] >=
- link_thr
+ neighbor for neighbor in node.links if
+ score_dict[tuple(sorted([node.ind, neighbor.ind]))] >= link_thr
])
neighbors.difference_update(cluster)
nodes.difference_update(neighbors)
diff --git a/ppocr/postprocess/east_postprocess.py b/ppocr/postprocess/east_postprocess.py
index c194c81c6911aac0f9210109c37b76b44532e9c4..c1af3eccef84d0044c7962094b85ad5f4399e09e 100755
--- a/ppocr/postprocess/east_postprocess.py
+++ b/ppocr/postprocess/east_postprocess.py
@@ -22,6 +22,7 @@ import cv2
import paddle
import os
+from ppocr.utils.utility import check_install
import sys
@@ -78,11 +79,12 @@ class EASTPostProcess(object):
boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
try:
+ check_install('lanms', 'lanms-nova')
import lanms
boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)
except:
print(
- 'you should install lanms by pip3 install lanms-nova to speed up nms_locality'
+ 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'
)
boxes = nms_locality(boxes.astype(np.float64), nms_thresh)
if boxes.shape[0] == 0:
diff --git a/ppocr/postprocess/fce_postprocess.py b/ppocr/postprocess/fce_postprocess.py
index 8e0716f9f2f3a7cb585fa40a2e2a27aecb606a9b..959f86efa4c3180a1fe4e6e2115bbf32966a7f09 100755
--- a/ppocr/postprocess/fce_postprocess.py
+++ b/ppocr/postprocess/fce_postprocess.py
@@ -31,7 +31,7 @@ def fill_hole(input_mask):
mask = np.zeros((h + 4, w + 4), np.uint8)
cv2.floodFill(canvas, mask, (0, 0), 1)
- canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool_)
return ~canvas | input_mask
@@ -234,7 +234,7 @@ class FCEPostProcess(object):
poly = np.array(boundary[:-1]).reshape(-1, 2).astype(np.float32)
score = boundary[-1]
points = cv2.boxPoints(cv2.minAreaRect(poly))
- points = np.int0(points)
+ points = np.int64(points)
new_boundaries.append(points.reshape(-1).tolist() + [score])
boundaries = new_boundaries
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index fbf8b93e3d11121c99ce5b2dcbf2149e15453d4a..ce2e9f8b579f2e2fb6d25390db71eb4e45ddeef3 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -67,7 +67,66 @@ class BaseRecLabelDecode(object):
def add_special_char(self, dict_character):
return dict_character
- def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
+ def get_word_info(self, text, selection):
+ """
+ Group the decoded characters and record the corresponding decoded positions.
+
+ Args:
+ text: the decoded text
+ selection: the bool array that identifies which columns of features are decoded as non-separated characters
+ Returns:
+ word_list: list of the grouped words
+ word_col_list: list of decoding positions corresponding to each character in the grouped word
+ state_list: list of marker to identify the type of grouping words, including two types of grouping words:
+ - 'cn': continous chinese characters (e.g., 你好啊)
+ - 'en&num': continous english characters (e.g., hello), number (e.g., 123, 1.123), or mixed of them connected by '-' (e.g., VGG-16)
+ The remaining characters in text are treated as separators between groups (e.g., space, '(', ')', etc.).
+ """
+ state = None
+ word_content = []
+ word_col_content = []
+ word_list = []
+ word_col_list = []
+ state_list = []
+ valid_col = np.where(selection==True)[0]
+
+ for c_i, char in enumerate(text):
+ if '\u4e00' <= char <= '\u9fff':
+ c_state = 'cn'
+ elif bool(re.search('[a-zA-Z0-9]', char)):
+ c_state = 'en&num'
+ else:
+ c_state = 'splitter'
+
+ if char == '.' and state == 'en&num' and c_i + 1 < len(text) and bool(re.search('[0-9]', text[c_i+1])): # grouping floting number
+ c_state = 'en&num'
+ if char == '-' and state == "en&num": # grouping word with '-', such as 'state-of-the-art'
+ c_state = 'en&num'
+
+ if state == None:
+ state = c_state
+
+ if state != c_state:
+ if len(word_content) != 0:
+ word_list.append(word_content)
+ word_col_list.append(word_col_content)
+ state_list.append(state)
+ word_content = []
+ word_col_content = []
+ state = c_state
+
+ if state != "splitter":
+ word_content.append(char)
+ word_col_content.append(valid_col[c_i])
+
+ if len(word_content) != 0:
+ word_list.append(word_content)
+ word_col_list.append(word_col_content)
+ state_list.append(state)
+
+ return word_list, word_col_list, state_list
+
+ def decode(self, text_index, text_prob=None, is_remove_duplicate=False, return_word_box=False):
""" convert text-index into text-label. """
result_list = []
ignored_tokens = self.get_ignored_tokens()
@@ -95,8 +154,12 @@ class BaseRecLabelDecode(object):
if self.reverse: # for arabic rec
text = self.pred_reverse(text)
-
- result_list.append((text, np.mean(conf_list).tolist()))
+
+ if return_word_box:
+ word_list, word_col_list, state_list = self.get_word_info(text, selection)
+ result_list.append((text, np.mean(conf_list).tolist(), [len(text_index[batch_idx]), word_list, word_col_list, state_list]))
+ else:
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def get_ignored_tokens(self):
@@ -111,14 +174,19 @@ class CTCLabelDecode(BaseRecLabelDecode):
super(CTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
- def __call__(self, preds, label=None, *args, **kwargs):
+ def __call__(self, preds, label=None, return_word_box=False, *args, **kwargs):
if isinstance(preds, tuple) or isinstance(preds, list):
preds = preds[-1]
if isinstance(preds, paddle.Tensor):
preds = preds.numpy()
preds_idx = preds.argmax(axis=2)
preds_prob = preds.max(axis=2)
- text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True, return_word_box=return_word_box)
+ if return_word_box:
+ for rec_idx, rec in enumerate(text):
+ wh_ratio = kwargs['wh_ratio_list'][rec_idx]
+ max_wh_ratio = kwargs['max_wh_ratio']
+ rec[2][0] = rec[2][0]*(wh_ratio/max_wh_ratio)
if label is None:
return text
label = self.decode(label)
@@ -568,6 +636,82 @@ class SARLabelDecode(BaseRecLabelDecode):
return [self.padding_idx]
+class SATRNLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(SATRNLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ self.rm_symbol = kwargs.get('rm_symbol', False)
+
+ def add_special_char(self, dict_character):
+ beg_end_str = ""
+ unknown_str = ""
+ padding_str = ""
+ dict_character = dict_character + [unknown_str]
+ self.unknown_idx = len(dict_character) - 1
+ dict_character = dict_character + [beg_end_str]
+ self.start_idx = len(dict_character) - 1
+ self.end_idx = len(dict_character) - 1
+ dict_character = dict_character + [padding_str]
+ self.padding_idx = len(dict_character) - 1
+ return dict_character
+
+ def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
+ """ convert text-index into text-label. """
+ result_list = []
+ ignored_tokens = self.get_ignored_tokens()
+
+ batch_size = len(text_index)
+ for batch_idx in range(batch_size):
+ char_list = []
+ conf_list = []
+ for idx in range(len(text_index[batch_idx])):
+ if text_index[batch_idx][idx] in ignored_tokens:
+ continue
+ if int(text_index[batch_idx][idx]) == int(self.end_idx):
+ if text_prob is None and idx == 0:
+ continue
+ else:
+ break
+ if is_remove_duplicate:
+ # only for predict
+ if idx > 0 and text_index[batch_idx][idx - 1] == text_index[
+ batch_idx][idx]:
+ continue
+ char_list.append(self.character[int(text_index[batch_idx][
+ idx])])
+ if text_prob is not None:
+ conf_list.append(text_prob[batch_idx][idx])
+ else:
+ conf_list.append(1)
+ text = ''.join(char_list)
+ if self.rm_symbol:
+ comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
+ text = text.lower()
+ text = comp.sub('', text)
+ result_list.append((text, np.mean(conf_list).tolist()))
+ return result_list
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=2)
+ preds_prob = preds.max(axis=2)
+
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+
+ if label is None:
+ return text
+ label = self.decode(label, is_remove_duplicate=False)
+ return text, label
+
+ def get_ignored_tokens(self):
+ return [self.padding_idx]
+
+
class DistillationSARLabelDecode(SARLabelDecode):
"""
Convert
@@ -723,7 +867,7 @@ class NRTRLabelDecode(BaseRecLabelDecode):
else:
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text.lower(), np.mean(conf_list).tolist()))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
@@ -891,7 +1035,7 @@ class VLLabelDecode(BaseRecLabelDecode):
) + length[i])].topk(1)[0][:, 0]
preds_prob = paddle.exp(
paddle.log(preds_prob).sum() / (preds_prob.shape[0] + 1e-6))
- text.append((preds_text, preds_prob.numpy()[0]))
+ text.append((preds_text, float(preds_prob)))
if label is None:
return text
label = self.decode(label)
diff --git a/ppocr/postprocess/sast_postprocess.py b/ppocr/postprocess/sast_postprocess.py
index bee75c05b1a3ea59193d566f91378c96797f533b..594bf17d6a0db2ebee17e7476834ce7b6b4289e6 100755
--- a/ppocr/postprocess/sast_postprocess.py
+++ b/ppocr/postprocess/sast_postprocess.py
@@ -141,6 +141,8 @@ class SASTPostProcess(object):
def nms(self, dets):
if self.is_python35:
+ from ppocr.utils.utility import check_install
+ check_install('lanms', 'lanms-nova')
import lanms
dets = lanms.merge_quadrangle_n9(dets, self.nms_thresh)
else:
diff --git a/ppocr/utils/e2e_metric/Deteval.py b/ppocr/utils/e2e_metric/Deteval.py
index 6ce56eda2aa9f38fdc712d49ae64945c558b418d..c2a4383eed38acc4e4c7effea2aa688007a0c24a 100755
--- a/ppocr/utils/e2e_metric/Deteval.py
+++ b/ppocr/utils/e2e_metric/Deteval.py
@@ -15,7 +15,9 @@
import json
import numpy as np
import scipy.io as io
-import Polygon as plg
+
+from ppocr.utils.utility import check_install
+
from ppocr.utils.e2e_metric.polygon_fast import iod, area_of_intersection, area
@@ -275,6 +277,8 @@ def get_score_C(gt_label, text, pred_bboxes):
"""
get score for CentripetalText (CT) prediction.
"""
+ check_install("Polygon", "Polygon3")
+ import Polygon as plg
def gt_reading_mod(gt_label, text):
"""This helper reads groundtruths from mat files"""
diff --git a/ppocr/utils/gen_label.py b/ppocr/utils/gen_label.py
index fb78bd38bcfc1a59cac48a28bbb655ecb83bcb3f..56d75544dbee596a87343c90320b0ea3178e6b28 100644
--- a/ppocr/utils/gen_label.py
+++ b/ppocr/utils/gen_label.py
@@ -29,7 +29,7 @@ def gen_rec_label(input_path, out_label):
def gen_det_label(root_path, input_dir, out_label):
with open(out_label, 'w') as out_file:
for label_file in os.listdir(input_dir):
- img_path = root_path + label_file[3:-4] + ".jpg"
+ img_path = os.path.join(root_path, label_file[3:-4] + ".jpg")
label = []
with open(
os.path.join(input_dir, label_file), 'r',
diff --git a/ppocr/utils/network.py b/ppocr/utils/network.py
index 080a5d160116cfdd3b255a883525281d97ee9cc9..f2cd690e12fd06f2749320f1319fde9de8ebe18d 100644
--- a/ppocr/utils/network.py
+++ b/ppocr/utils/network.py
@@ -20,6 +20,8 @@ from tqdm import tqdm
from ppocr.utils.logging import get_logger
+MODELS_DIR = os.path.expanduser("~/.paddleocr/models/")
+
def download_with_progressbar(url, save_path):
logger = get_logger()
@@ -67,6 +69,18 @@ def maybe_download(model_storage_directory, url):
os.remove(tmp_path)
+def maybe_download_params(model_path):
+ if os.path.exists(model_path) or not is_link(model_path):
+ return model_path
+ else:
+ url = model_path
+ tmp_path = os.path.join(MODELS_DIR, url.split('/')[-1])
+ print('download {} to {}'.format(url, tmp_path))
+ os.makedirs(MODELS_DIR, exist_ok=True)
+ download_with_progressbar(url, tmp_path)
+ return tmp_path
+
+
def is_link(s):
return s is not None and s.startswith('http')
diff --git a/ppocr/utils/profiler.py b/ppocr/utils/profiler.py
index c4e28bc6bea9ca912a0786d879a48ec0349e7698..629ef4ef054a050afd1bc0ce819cb664b9503e9f 100644
--- a/ppocr/utils/profiler.py
+++ b/ppocr/utils/profiler.py
@@ -13,7 +13,7 @@
# limitations under the License.
import sys
-import paddle
+import paddle.profiler as profiler
# A global variable to record the number of calling times for profiler
# functions. It is used to specify the tracing range of training steps.
@@ -21,7 +21,7 @@ _profiler_step_id = 0
# A global variable to avoid parsing from string every time.
_profiler_options = None
-
+_prof = None
class ProfilerOptions(object):
'''
@@ -31,6 +31,7 @@ class ProfilerOptions(object):
"profile_path=model.profile"
"batch_range=[50, 60]; profile_path=model.profile"
"batch_range=[50, 60]; tracer_option=OpDetail; profile_path=model.profile"
+
ProfilerOptions supports following key-value pair:
batch_range - a integer list, e.g. [100, 110].
state - a string, the optional values are 'CPU', 'GPU' or 'All'.
@@ -52,7 +53,8 @@ class ProfilerOptions(object):
'sorted_key': 'total',
'tracer_option': 'Default',
'profile_path': '/tmp/profile',
- 'exit_on_finished': True
+ 'exit_on_finished': True,
+ 'timer_only': True
}
self._parse_from_string(options_str)
@@ -71,6 +73,8 @@ class ProfilerOptions(object):
'state', 'sorted_key', 'tracer_option', 'profile_path'
]:
self._options[key] = value
+ elif key == 'timer_only':
+ self._options[key] = value
def __getitem__(self, name):
if self._options.get(name, None) is None:
@@ -84,7 +88,6 @@ def add_profiler_step(options_str=None):
Enable the operator-level timing using PaddlePaddle's profiler.
The profiler uses a independent variable to count the profiler steps.
One call of this function is treated as a profiler step.
-
Args:
profiler_options - a string to initialize the ProfilerOptions.
Default is None, and the profiler is disabled.
@@ -92,18 +95,33 @@ def add_profiler_step(options_str=None):
if options_str is None:
return
+ global _prof
global _profiler_step_id
global _profiler_options
if _profiler_options is None:
_profiler_options = ProfilerOptions(options_str)
-
- if _profiler_step_id == _profiler_options['batch_range'][0]:
- paddle.utils.profiler.start_profiler(
- _profiler_options['state'], _profiler_options['tracer_option'])
- elif _profiler_step_id == _profiler_options['batch_range'][1]:
- paddle.utils.profiler.stop_profiler(_profiler_options['sorted_key'],
- _profiler_options['profile_path'])
+ # profile : https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/performance_improving/profiling_model.html#chakanxingnengshujudetongjibiaodan
+ # timer_only = True only the model's throughput and time overhead are displayed
+ # timer_only = False calling summary can print a statistical form that presents performance data from different perspectives.
+ # timer_only = False the output Timeline information can be found in the profiler_log directory
+ if _prof is None:
+ _timer_only = str(_profiler_options['timer_only']) == str(True)
+ _prof = profiler.Profiler(
+ scheduler = (_profiler_options['batch_range'][0], _profiler_options['batch_range'][1]),
+ on_trace_ready = profiler.export_chrome_tracing('./profiler_log'),
+ timer_only = _timer_only)
+ _prof.start()
+ else:
+ _prof.step()
+
+ if _profiler_step_id == _profiler_options['batch_range'][1]:
+ _prof.stop()
+ _prof.summary(
+ op_detail=True,
+ thread_sep=False,
+ time_unit='ms')
+ _prof = None
if _profiler_options['exit_on_finished']:
sys.exit(0)
diff --git a/ppocr/utils/save_load.py b/ppocr/utils/save_load.py
index aa65f290c0a5f4f13b3103fb4404815e2ae74a88..e6a81c48dfd43245f13f69e1a5679d08838ca603 100644
--- a/ppocr/utils/save_load.py
+++ b/ppocr/utils/save_load.py
@@ -24,6 +24,7 @@ import six
import paddle
from ppocr.utils.logging import get_logger
+from ppocr.utils.network import maybe_download_params
__all__ = ['load_model']
@@ -145,6 +146,7 @@ def load_model(config, model, optimizer=None, model_type='det'):
def load_pretrained_params(model, path):
logger = get_logger()
+ path = maybe_download_params(path)
if path.endswith('.pdparams'):
path = path.replace('.pdparams', '')
assert os.path.exists(path + ".pdparams"), \
@@ -195,13 +197,26 @@ def save_model(model,
"""
_mkdir_if_not_exist(model_path, logger)
model_prefix = os.path.join(model_path, prefix)
+
+ if prefix == 'best_accuracy':
+ best_model_path = os.path.join(model_path, 'best_model')
+ _mkdir_if_not_exist(best_model_path, logger)
+
paddle.save(optimizer.state_dict(), model_prefix + '.pdopt')
+ if prefix == 'best_accuracy':
+ paddle.save(optimizer.state_dict(),
+ os.path.join(best_model_path, 'model.pdopt'))
is_nlp_model = config['Architecture']["model_type"] == 'kie' and config[
"Architecture"]["algorithm"] not in ["SDMGR"]
if is_nlp_model is not True:
paddle.save(model.state_dict(), model_prefix + '.pdparams')
metric_prefix = model_prefix
+
+ if prefix == 'best_accuracy':
+ paddle.save(model.state_dict(),
+ os.path.join(best_model_path, 'model.pdparams'))
+
else: # for kie system, we follow the save/load rules in NLP
if config['Global']['distributed']:
arch = model._layers
@@ -211,6 +226,10 @@ def save_model(model,
arch = arch.Student
arch.backbone.model.save_pretrained(model_prefix)
metric_prefix = os.path.join(model_prefix, 'metric')
+
+ if prefix == 'best_accuracy':
+ arch.backbone.model.save_pretrained(best_model_path)
+
# save metric and config
with open(metric_prefix + '.states', 'wb') as f:
pickle.dump(kwargs, f, protocol=2)
diff --git a/ppocr/utils/utility.py b/ppocr/utils/utility.py
index 18357c8e97bcea8ee321856a87146a4a7b901469..f788e79cd53a24d4d7f979f359cacd0532a1ff05 100755
--- a/ppocr/utils/utility.py
+++ b/ppocr/utils/utility.py
@@ -19,6 +19,9 @@ import cv2
import random
import numpy as np
import paddle
+import importlib.util
+import sys
+import subprocess
def print_dict(d, logger, delimiter=0):
@@ -72,6 +75,25 @@ def get_image_file_list(img_file):
imgs_lists = sorted(imgs_lists)
return imgs_lists
+def binarize_img(img):
+ if len(img.shape) == 3 and img.shape[2] == 3:
+ gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # conversion to grayscale image
+ # use cv2 threshold binarization
+ _, gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
+ img = cv2.cvtColor(gray, cv2.COLOR_GRAY2BGR)
+ return img
+
+def alpha_to_color(img, alpha_color=(255, 255, 255)):
+ if len(img.shape) == 3 and img.shape[2] == 4:
+ B, G, R, A = cv2.split(img)
+ alpha = A / 255
+
+ R = (alpha_color[0] * (1 - alpha) + R * alpha).astype(np.uint8)
+ G = (alpha_color[1] * (1 - alpha) + G * alpha).astype(np.uint8)
+ B = (alpha_color[2] * (1 - alpha) + B * alpha).astype(np.uint8)
+
+ img = cv2.merge((B, G, R))
+ return img
def check_and_read(img_path):
if os.path.basename(img_path)[-3:] in ['gif', 'GIF']:
@@ -131,6 +153,26 @@ def set_seed(seed=1024):
paddle.seed(seed)
+def check_install(module_name, install_name):
+ spec = importlib.util.find_spec(module_name)
+ if spec is None:
+ print(f'Warnning! The {module_name} module is NOT installed')
+ print(
+ f'Try install {module_name} module automatically. You can also try to install manually by pip install {install_name}.'
+ )
+ python = sys.executable
+ try:
+ subprocess.check_call(
+ [python, '-m', 'pip', 'install', install_name],
+ stdout=subprocess.DEVNULL)
+ print(f'The {module_name} module is now installed')
+ except subprocess.CalledProcessError as exc:
+ raise Exception(
+ f"Install {module_name} failed, please install manually")
+ else:
+ print(f"{module_name} has been installed.")
+
+
class AverageMeter:
def __init__(self):
self.reset()
diff --git a/ppocr/utils/visual.py b/ppocr/utils/visual.py
index b6de446593984788bea5c03026f4a5b8c0187909..9108a3728143e0ef0a0d6705e4cc701ab9588394 100644
--- a/ppocr/utils/visual.py
+++ b/ppocr/utils/visual.py
@@ -14,6 +14,7 @@
import cv2
import os
import numpy as np
+import PIL
from PIL import Image, ImageDraw, ImageFont
@@ -62,8 +63,13 @@ def draw_box_txt(bbox, text, draw, font, font_size, color):
draw.rectangle(bbox, fill=color)
# draw ocr results
- tw = font.getsize(text)[0]
- th = font.getsize(text)[1]
+ if int(PIL.__version__.split('.')[0]) < 10:
+ tw = font.getsize(text)[0]
+ th = font.getsize(text)[1]
+ else:
+ left, top, right, bottom = font.getbbox(text)
+ tw, th = right - left, bottom - top
+
start_y = max(0, bbox[0][1] - th)
draw.rectangle(
[(bbox[0][0] + 1, start_y), (bbox[0][0] + tw + 1, start_y + th)],
diff --git a/ppstructure/docs/quickstart_en.md b/ppstructure/docs/quickstart_en.md
index 9229a79de1f14ea738a4ca2b93cf44d48508ff40..bbaac342fdfdb797c9f0f6b8b343713c5afb970f 100644
--- a/ppstructure/docs/quickstart_en.md
+++ b/ppstructure/docs/quickstart_en.md
@@ -311,7 +311,7 @@ Please refer to: [Key Information Extraction](../kie/README.md) .
| save_pdf | Whether to convert docx to pdf when recovery| False |
| structure_version | Structure version, optional PP-structure and PP-structurev2 | PP-structure |
-Most of the parameters are consistent with the PaddleOCR whl package, see [whl package documentation](../../doc/doc_en/whl.md)
+Most of the parameters are consistent with the PaddleOCR whl package, see [whl package documentation](../../doc/doc_en/whl_en.md)
## 3. Summary
diff --git a/ppstructure/kie/README.md b/ppstructure/kie/README.md
index 872edb959276e22b22e4b733df44bdb6a6819c98..6717aa0c8c349da717b3fd01d9ae209b15eae026 100644
--- a/ppstructure/kie/README.md
+++ b/ppstructure/kie/README.md
@@ -89,7 +89,7 @@ Boxes of different colors in the image represent different categories.
The invoice and application form images have three categories: `request`, `answer` and `header`. The `question` and 'answer' can be used to extract the relationship.
-For the ID card image, the mdoel can be directly identify the key information such as `name`, `gender`, `nationality`, so that the subsequent relationship extraction process is not required, and the key information extraction task can be completed using only on model.
+For the ID card image, the model can directly identify the key information such as `name`, `gender`, `nationality`, so that the subsequent relationship extraction process is not required, and the key information extraction task can be completed using only on model.
### 3.2 RE
@@ -186,6 +186,10 @@ python3 ./tools/infer_kie_token_ser_re.py \
The visual result images and the predicted text file will be saved in the `Global.save_res_path` directory.
+If you want to use a custom ocr model, you can set it through the following fields
+- `Global.kie_det_model_dir`: the detection inference model path
+- `Global.kie_rec_model_dir`: the recognition inference model path
+
If you want to load the text detection and recognition results collected before, you can use the following command to predict.
@@ -257,6 +261,9 @@ python3 kie/predict_kie_token_ser_re.py \
The visual results and text file will be saved in directory `output`.
+If you want to use a custom ocr model, you can set it through the following fields
+- `--det_model_dir`: the detection inference model path
+- `--rec_model_dir`: the recognition inference model path
### 4.3 More
diff --git a/ppstructure/kie/README_ch.md b/ppstructure/kie/README_ch.md
index 7a8b1942b1849834f8843c8f272ce08e95f4b993..2efb49fd9622e767bbb8696e946bb05dcf72781f 100644
--- a/ppstructure/kie/README_ch.md
+++ b/ppstructure/kie/README_ch.md
@@ -170,6 +170,10 @@ python3 ./tools/infer_kie_token_ser_re.py \
`Global.save_res_path`目录中会保存可视化的结果图像以及预测的文本文件。
+如果想使用自定义OCR模型,可通过如下字段进行设置
+- `Global.kie_det_model_dir`: 设置检测inference模型地址
+- `Global.kie_rec_model_dir`: 设置识别inference模型地址
+
如果希望加载标注好的文本检测与识别结果,仅预测可以使用下面的命令进行预测。
@@ -239,6 +243,9 @@ python3 kie/predict_kie_token_ser_re.py \
可视化结果保存在`output`目录下。
+如果想使用自定义OCR模型,可通过如下字段进行设置
+- `--det_model_dir`: 设置检测inference模型地址
+- `--rec_model_dir`: 设置识别inference模型地址
### 4.3 更多
diff --git a/ppstructure/kie/requirements.txt b/ppstructure/kie/requirements.txt
index 6cfcba764190fd46f98b76c27e93db6f4fa36c45..61c230d3ed5bedc093c40af8228d3ea685382f54 100644
--- a/ppstructure/kie/requirements.txt
+++ b/ppstructure/kie/requirements.txt
@@ -2,6 +2,6 @@ sentencepiece
yacs
seqeval
pypandoc
-attrdict
+attrdict3
python_docx
paddlenlp>=2.4.1
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index bb061c998f6f8b16c06f9ee94299af0f59c53eb2..b8b871689c919097e480f726a402da1c54873df0 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -34,7 +34,7 @@ from ppocr.utils.visual import draw_ser_results, draw_re_results
from tools.infer.predict_system import TextSystem
from ppstructure.layout.predict_layout import LayoutPredictor
from ppstructure.table.predict_table import TableSystem, to_excel
-from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.utility import parse_args, draw_structure_result, cal_ocr_word_box
logger = get_logger()
@@ -79,6 +79,8 @@ class StructureSystem(object):
from ppstructure.kie.predict_kie_token_ser_re import SerRePredictor
self.kie_predictor = SerRePredictor(args)
+ self.return_word_box = args.return_word_box
+
def __call__(self, img, return_ocr_result_in_table=False, img_idx=0):
time_dict = {
'image_orientation': 0,
@@ -156,17 +158,27 @@ class StructureSystem(object):
]
res = []
for box, rec_res in zip(filter_boxes, filter_rec_res):
- rec_str, rec_conf = rec_res
+ rec_str, rec_conf = rec_res[0], rec_res[1]
for token in style_token:
if token in rec_str:
rec_str = rec_str.replace(token, '')
if not self.recovery:
box += [x1, y1]
- res.append({
- 'text': rec_str,
- 'confidence': float(rec_conf),
- 'text_region': box.tolist()
- })
+ if self.return_word_box:
+ word_box_content_list, word_box_list = cal_ocr_word_box(rec_str, box, rec_res[2])
+ res.append({
+ 'text': rec_str,
+ 'confidence': float(rec_conf),
+ 'text_region': box.tolist(),
+ 'text_word': word_box_content_list,
+ 'text_word_region': word_box_list
+ })
+ else:
+ res.append({
+ 'text': rec_str,
+ 'confidence': float(rec_conf),
+ 'text_region': box.tolist()
+ })
res_list.append({
'type': region['label'].lower(),
'bbox': [x1, y1, x2, y2],
@@ -229,7 +241,9 @@ def main(args):
if args.recovery and args.use_pdf2docx_api and flag_pdf:
from pdf2docx.converter import Converter
- docx_file = os.path.join(args.output, '{}.docx'.format(img_name))
+ os.makedirs(args.output, exist_ok=True)
+ docx_file = os.path.join(args.output,
+ '{}_api.docx'.format(img_name))
cv = Converter(image_file)
cv.convert(docx_file)
cv.close()
diff --git a/ppstructure/recovery/recovery_to_doc.py b/ppstructure/recovery/recovery_to_doc.py
index 1d8f8d9d4babca7410d6625dbeac4c41668f58a7..cd1728b6668577266c10ab71667e630c21a5703b 100644
--- a/ppstructure/recovery/recovery_to_doc.py
+++ b/ppstructure/recovery/recovery_to_doc.py
@@ -36,6 +36,8 @@ def convert_info_docx(img, res, save_folder, img_name):
flag = 1
for i, region in enumerate(res):
+ if len(region['res']) == 0:
+ continue
img_idx = region['img_idx']
if flag == 2 and region['layout'] == 'single':
section = doc.add_section(WD_SECTION.CONTINUOUS)
@@ -73,7 +75,7 @@ def convert_info_docx(img, res, save_folder, img_name):
text_run.font.size = shared.Pt(10)
# save to docx
- docx_path = os.path.join(save_folder, '{}.docx'.format(img_name))
+ docx_path = os.path.join(save_folder, '{}_ocr.docx'.format(img_name))
doc.save(docx_path)
logger.info('docx save to {}'.format(docx_path))
diff --git a/ppstructure/recovery/requirements.txt b/ppstructure/recovery/requirements.txt
index ec08f9d0a28b54e3e082db4d32799f8384250c1d..761b9d7c3e34cedb335e2c93707619593ebede63 100644
--- a/ppstructure/recovery/requirements.txt
+++ b/ppstructure/recovery/requirements.txt
@@ -1,5 +1,4 @@
python-docx
-PyMuPDF==1.19.0
beautifulsoup4
fonttools>=4.24.0
fire>=0.3.0
diff --git a/ppstructure/recovery/table_process.py b/ppstructure/recovery/table_process.py
index 982e6b760f9291628d0514728dc8f684f183aa2c..77a6ef7659666ebcbe54dd0c107cb2d62e4c7273 100644
--- a/ppstructure/recovery/table_process.py
+++ b/ppstructure/recovery/table_process.py
@@ -278,8 +278,6 @@ class HtmlToDocx(HTMLParser):
cell_col += colspan
cell_row += 1
- doc.save('1.docx')
-
def handle_data(self, data):
if self.skip:
return
diff --git a/ppstructure/table/predict_table.py b/ppstructure/table/predict_table.py
index 354baf6ddf5e73b2e933a9b9e8a568bda80340e5..76bd42dc003cdbd1037cdfe4d50b480f777b41c0 100644
--- a/ppstructure/table/predict_table.py
+++ b/ppstructure/table/predict_table.py
@@ -93,7 +93,7 @@ class TableSystem(object):
time_dict['rec'] = rec_elapse
if return_ocr_result_in_table:
- result['boxes'] = dt_boxes #[x.tolist() for x in dt_boxes]
+ result['boxes'] = [x.tolist() for x in dt_boxes]
result['rec_res'] = rec_res
tic = time.time()
diff --git a/ppstructure/utility.py b/ppstructure/utility.py
index d909f1a8a165745a5c0df78cc3d89960ec4469e7..4ab4b88b9bc073287ec33b29eea9fca471da8470 100644
--- a/ppstructure/utility.py
+++ b/ppstructure/utility.py
@@ -13,9 +13,11 @@
# limitations under the License.
import random
import ast
+import PIL
from PIL import Image, ImageDraw, ImageFont
import numpy as np
-from tools.infer.utility import draw_ocr_box_txt, str2bool, init_args as infer_args
+from tools.infer.utility import draw_ocr_box_txt, str2bool, str2int_tuple, init_args as infer_args
+import math
def init_args():
@@ -98,6 +100,21 @@ def init_args():
type=str2bool,
default=False,
help='Whether to use pdf2docx api')
+ parser.add_argument(
+ "--invert",
+ type=str2bool,
+ default=False,
+ help='Whether to invert image before processing')
+ parser.add_argument(
+ "--binarize",
+ type=str2bool,
+ default=False,
+ help='Whether to threshold binarize image before processing')
+ parser.add_argument(
+ "--alphacolor",
+ type=str2int_tuple,
+ default=(255, 255, 255),
+ help='Replacement color for the alpha channel, if the latter is present; R,G,B integers')
return parser
@@ -132,7 +149,13 @@ def draw_structure_result(image, result, font_path):
[(box_layout[0], box_layout[1]), (box_layout[2], box_layout[3])],
outline=box_color,
width=3)
- text_w, text_h = font.getsize(region['type'])
+
+ if int(PIL.__version__.split('.')[0]) < 10:
+ text_w, text_h = font.getsize(region['type'])
+ else:
+ left, top, right, bottom = font.getbbox(region['type'])
+ text_w, text_h = right - left, bottom - top
+
draw_layout.rectangle(
[(box_layout[0], box_layout[1]),
(box_layout[0] + text_w, box_layout[1] + text_h)],
@@ -151,6 +174,71 @@ def draw_structure_result(image, result, font_path):
txts.append(text_result['text'])
scores.append(text_result['confidence'])
+ if 'text_word_region' in text_result:
+ for word_region in text_result['text_word_region']:
+ char_box = word_region
+ box_height = int(
+ math.sqrt((char_box[0][0] - char_box[3][0])**2 + (
+ char_box[0][1] - char_box[3][1])**2))
+ box_width = int(
+ math.sqrt((char_box[0][0] - char_box[1][0])**2 + (
+ char_box[0][1] - char_box[1][1])**2))
+ if box_height == 0 or box_width == 0:
+ continue
+ boxes.append(word_region)
+ txts.append("")
+ scores.append(1.0)
+
im_show = draw_ocr_box_txt(
img_layout, boxes, txts, scores, font_path=font_path, drop_score=0)
return im_show
+
+
+def cal_ocr_word_box(rec_str, box, rec_word_info):
+ ''' Calculate the detection frame for each word based on the results of recognition and detection of ocr'''
+
+ col_num, word_list, word_col_list, state_list = rec_word_info
+ box = box.tolist()
+ bbox_x_start = box[0][0]
+ bbox_x_end = box[1][0]
+ bbox_y_start = box[0][1]
+ bbox_y_end = box[2][1]
+
+ cell_width = (bbox_x_end - bbox_x_start) / col_num
+
+ word_box_list = []
+ word_box_content_list = []
+ cn_width_list = []
+ cn_col_list = []
+ for word, word_col, state in zip(word_list, word_col_list, state_list):
+ if state == 'cn':
+ if len(word_col) != 1:
+ char_seq_length = (word_col[-1] - word_col[0] + 1) * cell_width
+ char_width = char_seq_length / (len(word_col) - 1)
+ cn_width_list.append(char_width)
+ cn_col_list += word_col
+ word_box_content_list += word
+ else:
+ cell_x_start = bbox_x_start + int(word_col[0] * cell_width)
+ cell_x_end = bbox_x_start + int((word_col[-1] + 1) * cell_width)
+ cell = ((cell_x_start, bbox_y_start), (cell_x_end, bbox_y_start),
+ (cell_x_end, bbox_y_end), (cell_x_start, bbox_y_end))
+ word_box_list.append(cell)
+ word_box_content_list.append("".join(word))
+ if len(cn_col_list) != 0:
+ if len(cn_width_list) != 0:
+ avg_char_width = np.mean(cn_width_list)
+ else:
+ avg_char_width = (bbox_x_end - bbox_x_start) / len(rec_str)
+ for center_idx in cn_col_list:
+ center_x = (center_idx + 0.5) * cell_width
+ cell_x_start = max(int(center_x - avg_char_width / 2),
+ 0) + bbox_x_start
+ cell_x_end = min(
+ int(center_x + avg_char_width / 2), bbox_x_end -
+ bbox_x_start) + bbox_x_start
+ cell = ((cell_x_start, bbox_y_start), (cell_x_end, bbox_y_start),
+ (cell_x_end, bbox_y_end), (cell_x_start, bbox_y_end))
+ word_box_list.append(cell)
+
+ return word_box_content_list, word_box_list
diff --git a/requirements.txt b/requirements.txt
index 8c5b12f831dfcb2a8854ec46b82ff1fa5b84029e..a5a022738c5fe4c7430099a7a1e41c1671b4ed15 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -7,13 +7,12 @@ tqdm
numpy
visualdl
rapidfuzz
-opencv-python
-opencv-contrib-python
+opencv-python<=4.6.0.66
+opencv-contrib-python<=4.6.0.66
cython
lxml
premailer
openpyxl
attrdict
-Polygon3
-lanms-neo==1.0.2
-PyMuPDF==1.19.0
\ No newline at end of file
+PyMuPDF<1.21.0
+Pillow
diff --git a/test_tipc/benchmark_train.sh b/test_tipc/benchmark_train.sh
index 25fda8f97f0bfdefbd6922b13a0ffef3f40c3de9..1668e41a9a95272e38f9f4b5960400718772ec34 100644
--- a/test_tipc/benchmark_train.sh
+++ b/test_tipc/benchmark_train.sh
@@ -72,6 +72,19 @@ FILENAME=$new_filename
# MODE must be one of ['benchmark_train']
MODE=$2
PARAMS=$3
+
+to_static=""
+# parse "to_static" options and modify trainer into "to_static_trainer"
+if [[ $PARAMS =~ "dynamicTostatic" ]] ;then
+ to_static="d2sT_"
+ sed -i 's/trainer:norm_train/trainer:to_static_train/g' $FILENAME
+ # clear PARAM contents
+ if [ $PARAMS = "to_static" ] ;then
+ PARAMS=""
+ fi
+fi
+# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamic_bs8_fp32_DP_N1C8
+# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamicTostatic_bs8_fp32_DP_N1C8
# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamic_bs8_null_DP_N1C1
IFS=$'\n'
# parser params from train_benchmark.txt
@@ -83,13 +96,13 @@ model_name=$(func_parser_value "${lines[1]}")
python_name=$(func_parser_value "${lines[2]}")
# set env
-python=${python_name}
+python=python
export str_tmp=$(echo `pip list|grep paddlepaddle-gpu|awk -F ' ' '{print $2}'`)
export frame_version=${str_tmp%%.post*}
export frame_commit=$(echo `${python} -c "import paddle;print(paddle.version.commit)"`)
# 获取benchmark_params所在的行数
-line_num=`grep -n "train_benchmark_params" $FILENAME | cut -d ":" -f 1`
+line_num=`grep -n -w "train_benchmark_params" $FILENAME | cut -d ":" -f 1`
# for train log parser
batch_size=$(func_parser_value "${lines[line_num]}")
line_num=`expr $line_num + 1`
@@ -117,7 +130,8 @@ repo_name=$(get_repo_name )
SAVE_LOG=${BENCHMARK_LOG_DIR:-$(pwd)} # */benchmark_log
mkdir -p "${SAVE_LOG}/benchmark_log/"
status_log="${SAVE_LOG}/benchmark_log/results.log"
-
+# get benchmark profiling params : PROFILING_TIMER_ONLY=no|True|False
+PROFILING_TIMER_ONLY=${PROFILING_TIMER_ONLY:-"True"}
# The number of lines in which train params can be replaced.
line_python=3
line_gpuid=4
@@ -140,6 +154,13 @@ if [ ! -n "$PARAMS" ] ;then
fp_items_list=(${fp_items})
device_num_list=(N1C4)
run_mode="DP"
+elif [[ ${PARAMS} = "dynamicTostatic" ]];then
+ IFS="|"
+ model_type=$PARAMS
+ batch_size_list=(${batch_size})
+ fp_items_list=(${fp_items})
+ device_num_list=(N1C4)
+ run_mode="DP"
else
# parser params from input: modeltype_bs${bs_item}_${fp_item}_${run_mode}_${device_num}
IFS="_"
@@ -179,26 +200,32 @@ for batch_size in ${batch_size_list[*]}; do
gpu_id=$(set_gpu_id $device_num)
if [ ${#gpu_id} -le 1 ];then
- log_path="$SAVE_LOG/profiling_log"
- mkdir -p $log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_profiling"
func_sed_params "$FILENAME" "${line_gpuid}" "0" # sed used gpu_id
- # set profile_option params
- tmp=`sed -i "${line_profile}s/.*/${profile_option}/" "${FILENAME}"`
-
- # run test_train_inference_python.sh
- cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
- echo $cmd
- eval $cmd
- eval "cat ${log_path}/${log_name}"
-
+ if [[ ${PROFILING_TIMER_ONLY} != "no" ]];then
+ echo "run profile"
+ # The default value of profile_option's timer_only parameter is True
+ if [[ ${PROFILING_TIMER_ONLY} = "False" ]];then
+ profile_option="${profile_option};timer_only=False"
+ fi
+ log_path="$SAVE_LOG/profiling_log"
+ mkdir -p $log_path
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}profiling"
+ # set profile_option params
+ tmp=`sed -i "${line_profile}s/.*/\"${profile_option}\"/" "${FILENAME}"`
+ # run test_train_inference_python.sh
+ cmd="timeout 5m bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
+ echo $cmd
+ eval ${cmd}
+ eval "cat ${log_path}/${log_name}"
+ fi
+ echo "run without profile"
# without profile
log_path="$SAVE_LOG/train_log"
speed_log_path="$SAVE_LOG/index"
mkdir -p $log_path
mkdir -p $speed_log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_log"
- speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_speed"
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
func_sed_params "$FILENAME" "${line_profile}" "null" # sed profile_id as null
cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
echo $cmd
@@ -232,8 +259,8 @@ for batch_size in ${batch_size_list[*]}; do
speed_log_path="$SAVE_LOG/index"
mkdir -p $log_path
mkdir -p $speed_log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_log"
- speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_speed"
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
func_sed_params "$FILENAME" "${line_gpuid}" "$gpu_id" # sed used gpu_id
func_sed_params "$FILENAME" "${line_profile}" "null" # sed --profile_option as null
cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml b/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
index 3eb82d42bc3f2b3ca7420d999865977bbad09e31..43e14b84d77a216ef949e2af14a01b65bb350b54 100644
--- a/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
+++ b/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
@@ -27,7 +27,7 @@ Optimizer:
beta2: 0.999
lr:
name: Piecewise
- decay_epochs : [700, 800]
+ decay_epochs : [700]
values : [0.001, 0.0001]
warmup_epoch: 5
regularizer:
diff --git a/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
index bf10aebe3e9aa67e30ce7a20cb07f376825e39ae..8daab48a4dc08aae888d7b784605b3986e220821 100644
--- a/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
@@ -17,7 +17,7 @@ norm_train:tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -57,3 +57,5 @@ fp_items:fp32|fp16
epoch:2
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
index 4c8ba0a6fa4a355e9bad1665a8de82399f919740..63362135737f1665fecb16d5b7d6a19c8cd1b8da 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
@@ -19,6 +19,7 @@ Global:
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_distillation.txt
+ d2s_train_image_shape: [3, 48, -1]
Optimizer:
@@ -27,7 +28,7 @@ Optimizer:
beta2: 0.999
lr:
name: Piecewise
- decay_epochs : [700, 800]
+ decay_epochs : [700]
values : [0.0005, 0.00005]
warmup_epoch: 5
regularizer:
@@ -45,7 +46,7 @@ Architecture:
freeze_params: false
return_all_feats: true
model_type: *model_type
- algorithm: SVTR
+ algorithm: SVTR_LCNet
Transform:
Backbone:
name: MobileNetV1Enhance
@@ -72,7 +73,7 @@ Architecture:
freeze_params: false
return_all_feats: true
model_type: *model_type
- algorithm: SVTR
+ algorithm: SVTR_LCNet
Transform:
Backbone:
name: MobileNetV1Enhance
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
index fee08b08ede0f61ae4f57fd42dba303301798a3e..13480ec49acc3896920219bee369bb4bfc97b6ff 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
@@ -17,7 +17,7 @@ norm_train:tools/train.py -c test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_d
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -57,4 +57,5 @@ fp_items:fp32|fp16
epoch:1
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
-
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3635c0c6f06c73909527874f54a8fc0402e4c61d
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_det
+python:python
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:pretrain_models/PPLCNetV3_x0_75_ocr_det.pdparams
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Global.eval_batch_step=[4000,400]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv3_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
+===========================train_benchmark_params==========================
+batch_size:8
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5796deb010d4d58162d1d93b56dca4568c14b849
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt] Train.loader.num_workers=16 Eval.loader.num_workers=16
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:128
+fp_items:fp32|fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fc2884be97f1d483a9d33a0674c8b4bdbfd5ef87
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_ampO2_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:384
+fp_items:fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0465cfc5d78f477ce2b3a7f7b87ceebcef45b5b5
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_fp32_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:192
+fp_items:fp32
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..315fac9829be3a6443958bdaa2d69a5f84b26c26
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_det
+python:python
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:pretrain_models/PPHGNet_small_ocr_det.pdparams
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_teacher.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Global.eval_batch_step=[4000,400]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_teacher.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv3_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
+===========================train_benchmark_params==========================
+batch_size:4
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c7fa48f196b92939687d34c7c310e15a57a6d9b4
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt] Train.loader.num_workers=16 Eval.loader.num_workers=16
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:128
+fp_items:fp32|fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..679d2aa37179ba85cad2d0b65c3d06a6c2eb5af9
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt
@@ -0,0 +1,60 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet_ampO2_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:256
+fp_items:fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..368bc7c64c1d05ee8d6670638fff4d62f4d08796
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet_fp32_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:256
+fp_items:fp32
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/en_table_structure/table_mv3.yml b/test_tipc/configs/en_table_structure/table_mv3.yml
deleted file mode 100755
index edcbe2c3b00e8d8a56ad8dd9f208e283b511b86e..0000000000000000000000000000000000000000
--- a/test_tipc/configs/en_table_structure/table_mv3.yml
+++ /dev/null
@@ -1,129 +0,0 @@
-Global:
- use_gpu: true
- epoch_num: 10
- log_smooth_window: 20
- print_batch_step: 5
- save_model_dir: ./output/table_mv3/
- save_epoch_step: 400
- # evaluation is run every 400 iterations after the 0th iteration
- eval_batch_step: [0, 40000]
- cal_metric_during_train: True
- pretrained_model:
- checkpoints:
- save_inference_dir:
- use_visualdl: False
- infer_img: ppstructure/docs/table/table.jpg
- save_res_path: output/table_mv3
- # for data or label process
- character_dict_path: ppocr/utils/dict/table_structure_dict.txt
- character_type: en
- max_text_length: &max_text_length 500
- box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
- infer_mode: False
-
-Optimizer:
- name: Adam
- beta1: 0.9
- beta2: 0.999
- clip_norm: 5.0
- lr:
- learning_rate: 0.001
- regularizer:
- name: 'L2'
- factor: 0.00000
-
-Architecture:
- model_type: table
- algorithm: TableAttn
- Backbone:
- name: MobileNetV3
- scale: 1.0
- model_name: small
- disable_se: true
- Head:
- name: TableAttentionHead
- hidden_size: 256
- loc_type: 2
- max_text_length: *max_text_length
- loc_reg_num: &loc_reg_num 4
-
-Loss:
- name: TableAttentionLoss
- structure_weight: 100.0
- loc_weight: 10000.0
-
-PostProcess:
- name: TableLabelDecode
-
-Metric:
- name: TableMetric
- main_indicator: acc
- compute_bbox_metric: false # cost many time, set False for training
-
-Train:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train
- label_file_list: [./train_data/pubtabnet/train.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: False
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: True
- batch_size_per_card: 32
- drop_last: True
- num_workers: 1
-
-Eval:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: False
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 16
- num_workers: 1
diff --git a/test_tipc/configs/en_table_structure/train_infer_python.txt b/test_tipc/configs/en_table_structure/train_infer_python.txt
index 3fd5dc9f60a9621026d488e5654cd7e1421e8b65..8861ea8cc134a94dfa7b9b233ea66bc341a5a666 100644
--- a/test_tipc/configs/en_table_structure/train_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o Global.print_batch_step=1 Train.loader.shuffle=false
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
index 41d236c3765fbf6a711c6739d8dee4f41a147039..8e25b9d4ef7abbde7986545ec7245cc92ae25710 100644
--- a/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index 31ac1ed53f2adc9810bc4fd2cf4f874d89d49606..a399e35d453745f323ec4c4e18fe428fe8150d85 100644
--- a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_pact_infer_python.txt b/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
index 9890b906a1d3b1127352af567dca0d7186f94694..0bb04c4c929a53ebb44db0ce5c3e98b28c179ff9 100644
--- a/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
@@ -14,7 +14,7 @@ null:null
##
trainer:pact_train
norm_train:null
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+pact_train:deploy/slim/quantization/quant.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
fpgm_train:null
distill_train:null
null:null
@@ -28,7 +28,7 @@ null:null
Global.save_inference_dir:./output/
Global.checkpoints:
norm_export:null
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+quant_export:deploy/slim/quantization/export_model.py -c configs/table/table_mv3.yml -o
fpgm_export:
distill_export:null
export1:null
diff --git a/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt b/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
index e8f7bbaa50417b97f79596634677fff0a95cb47f..aae0895e6469e6913673e5e5dad2f75702f6c921 100644
--- a/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
@@ -4,7 +4,7 @@ python:python3.7
Global.pretrained_model:
Global.save_inference_dir:null
infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer/
-infer_export:deploy/slim/quantization/quant_kl.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+infer_export:deploy/slim/quantization/quant_kl.py -c configs/table/table_mv3.yml -o
infer_quant:True
inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
--use_gpu:True|False
diff --git a/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml b/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
index d2be152f0bae7d87129904d87c56c6d777a1f338..31e0ed4918e25c9408b0a6f77ae94d3d8f734cc1 100644
--- a/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
+++ b/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
@@ -84,7 +84,7 @@ Train:
shuffle: True
drop_last: False
batch_size_per_card: 8
- num_workers: 4
+ num_workers: 16
Eval:
dataset:
diff --git a/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
index 140b17e0e79f9895167e9c51d86ced173e44a541..6e22bc7832c292b59e060f0564d77c1e93d785af 100644
--- a/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
+++ b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
@@ -20,6 +20,7 @@ Global:
infer_mode: False
use_space_char: False
save_res_path: ./output/rec/predicts_svtr_tiny.txt
+ d2s_train_image_shape: [3, 64, 256]
Optimizer:
diff --git a/test_tipc/configs/rec_svtrnet/train_infer_python.txt b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
index 5508c0411cfdc7102ccec7a00c59c2a5e1a54998..63e6b908a35c061f0979d0548f73e73b4265505d 100644
--- a/test_tipc/configs/rec_svtrnet/train_infer_python.txt
+++ b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
@@ -51,3 +51,11 @@ inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dic
null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,64,256]}]
+===========================train_benchmark_params==========================
+batch_size:512
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/slanet/SLANet.yml b/test_tipc/configs/slanet/SLANet.yml
deleted file mode 100644
index 0d55d70d64e29716e942517e9c0d4909e6f70f9b..0000000000000000000000000000000000000000
--- a/test_tipc/configs/slanet/SLANet.yml
+++ /dev/null
@@ -1,143 +0,0 @@
-Global:
- use_gpu: true
- epoch_num: 100
- log_smooth_window: 20
- print_batch_step: 20
- save_model_dir: ./output/SLANet
- save_epoch_step: 400
- # evaluation is run every 1000 iterations after the 0th iteration
- eval_batch_step: [0, 1000]
- cal_metric_during_train: True
- pretrained_model:
- checkpoints:
- save_inference_dir: ./output/SLANet/infer
- use_visualdl: False
- infer_img: ppstructure/docs/table/table.jpg
- # for data or label process
- character_dict_path: ppocr/utils/dict/table_structure_dict.txt
- character_type: en
- max_text_length: &max_text_length 500
- box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
- infer_mode: False
- use_sync_bn: True
- save_res_path: 'output/infer'
-
-Optimizer:
- name: Adam
- beta1: 0.9
- beta2: 0.999
- clip_norm: 5.0
- lr:
- name: Piecewise
- learning_rate: 0.001
- decay_epochs : [40, 50]
- values : [0.001, 0.0001, 0.00005]
- regularizer:
- name: 'L2'
- factor: 0.00000
-
-Architecture:
- model_type: table
- algorithm: SLANet
- Backbone:
- name: PPLCNet
- scale: 1.0
- pretrained: true
- use_ssld: true
- Neck:
- name: CSPPAN
- out_channels: 96
- Head:
- name: SLAHead
- hidden_size: 256
- max_text_length: *max_text_length
- loc_reg_num: &loc_reg_num 4
-
-Loss:
- name: SLALoss
- structure_weight: 1.0
- loc_weight: 2.0
- loc_loss: smooth_l1
-
-PostProcess:
- name: TableLabelDecode
- merge_no_span_structure: &merge_no_span_structure True
-
-Metric:
- name: TableMetric
- main_indicator: acc
- compute_bbox_metric: False
- loc_reg_num: *loc_reg_num
- box_format: *box_format
-
-Train:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train/
- label_file_list: [./train_data/pubtabnet/train.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: *merge_no_span_structure
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- in_box_format: *box_format
- out_box_format: *box_format
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: True
- batch_size_per_card: 48
- drop_last: True
- num_workers: 1
-
-Eval:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: *merge_no_span_structure
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- in_box_format: *box_format
- out_box_format: *box_format
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 48
- num_workers: 1
diff --git a/test_tipc/configs/slanet/train_infer_python.txt b/test_tipc/configs/slanet/train_infer_python.txt
index 05264360ac95d08ba11157372a9badef23afdc70..0beebc04d63f74d6d099f19b516a4702b43bd39f 100644
--- a/test_tipc/configs/slanet/train_infer_python.txt
+++ b/test_tipc/configs/slanet/train_infer_python.txt
@@ -1,6 +1,6 @@
===========================train_params===========================
model_name:slanet
-python:python3.7
+python:python
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:fp32
@@ -13,11 +13,11 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/slanet/SLANet.yml -o Global.print_batch_step=1 Train.loader.shuffle=false
+norm_train:tools/train.py -c configs/table/SLANet.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/slanet/SLANet.yml -o
+norm_export:tools/export_model.py -c configs/table/SLANet.yml -o
quant_export:
fpgm_export:
distill_export:null
@@ -52,8 +52,10 @@ null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,488,488]}]
===========================train_benchmark_params==========================
-batch_size:32
+batch_size:64
fp_items:fp32|fp16
epoch:2
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/table_master/table_master.yml b/test_tipc/configs/table_master/table_master.yml
index 27f81683b9b7e9475bdfa4ad4862166f4cf9c14d..b27bdae542bf85d8f2932372d9002c2de8d6c652 100644
--- a/test_tipc/configs/table_master/table_master.yml
+++ b/test_tipc/configs/table_master/table_master.yml
@@ -6,7 +6,7 @@ Global:
save_model_dir: ./output/table_master/
save_epoch_step: 17
eval_batch_step: [0, 6259]
- cal_metric_during_train: true
+ cal_metric_during_train: false
pretrained_model: null
checkpoints:
save_inference_dir: output/table_master/infer
@@ -16,6 +16,7 @@ Global:
character_dict_path: ppocr/utils/dict/table_master_structure_dict.txt
infer_mode: false
max_text_length: 500
+ d2s_train_image_shape: [3, 480, 480]
Optimizer:
@@ -67,16 +68,15 @@ Metric:
Train:
dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train
- label_file_list: [./train_data/pubtabnet/train.jsonl]
+ name: LMDBDataSetTableMaster
+ data_dir: train_data/StructureLabel_val_500/
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: False
replace_empty_cell_token: True
- ResizeTableImage:
max_len: 480
@@ -101,16 +101,15 @@ Train:
Eval:
dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
+ name: LMDBDataSetTableMaster
+ data_dir: train_data/StructureLabel_val_500/
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: False
replace_empty_cell_token: True
- ResizeTableImage:
max_len: 480
diff --git a/test_tipc/configs/table_master/train_infer_python.txt b/test_tipc/configs/table_master/train_infer_python.txt
index c3a871731a36fb5434db111cfd68b6eab7ba3f99..a248cd8227a22babb29f2fad1b4eb8b30051711f 100644
--- a/test_tipc/configs/table_master/train_infer_python.txt
+++ b/test_tipc/configs/table_master/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/table_master/table_master.yml -o Global.print_batch_step=10
+norm_train:tools/train.py -c test_tipc/configs/table_master/table_master.yml -o Global.print_batch_step=1
pact_train:null
fpgm_train:null
distill_train:null
@@ -51,3 +51,11 @@ null:null
null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,480,480]}]
+===========================train_benchmark_params==========================
+batch_size:10
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt b/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
index adad78bb76e34635a632ef7c1b55e212bc4b636a..e304519c719f21deed52c5f33aa9ce3a8fd8251d 100644
--- a/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
+++ b/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
@@ -1,6 +1,6 @@
===========================train_params===========================
model_name:vi_layoutxlm_ser
-python:python3.7
+python:python
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:fp32
@@ -13,11 +13,11 @@ train_infer_img_dir:ppstructure/docs/kie/input/zh_val_42.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c ./configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Global.print_batch_step=1 Global.eval_batch_step=[1000,1000] Train.loader.shuffle=false
+norm_train:tools/train.py -c ./configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Global.print_batch_step=1 Global.eval_batch_step=[1000,1000] Train.loader.shuffle=false Train.loader.num_workers=32 Eval.loader.num_workers=32
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -52,8 +52,10 @@ null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,224,224]}]
===========================train_benchmark_params==========================
-batch_size:4
+batch_size:8
fp_items:fp32|fp16
epoch:3
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
diff --git a/test_tipc/prepare.sh b/test_tipc/prepare.sh
index 02ee8a24d241195d1330ea42fc05ed35dd7a87b7..a2e5332745a704ca8bf0770823be36ae8c475802 100644
--- a/test_tipc/prepare.sh
+++ b/test_tipc/prepare.sh
@@ -23,7 +23,7 @@ trainer_list=$(func_parser_value "${lines[14]}")
if [ ${MODE} = "benchmark_train" ];then
python_name_list=$(func_parser_value "${lines[2]}")
array=(${python_name_list})
- python_name=${array[0]}
+ python_name=python
${python_name} -m pip install -r requirements.txt
if [[ ${model_name} =~ "ch_ppocr_mobile_v2_0_det" || ${model_name} =~ "det_mv3_db_v2_0" ]];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
@@ -40,6 +40,42 @@ if [ ${MODE} = "benchmark_train" ];then
cd ../../../
fi
fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPLCNetV3_x0_75_ocr_det.pdparams --no-check-certificate
+ rm -rf ./train_data/icdar2015
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015_benckmark.tar
+ ln -s ./icdar2015_benckmark ./icdar2015
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPHGNet_small_ocr_det.pdparams --no-check-certificate
+ rm -rf ./train_data/icdar2015
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015_benckmark.tar
+ ln -s ./icdar2015_benckmark ./icdar2015
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_rec" ]];then
+ rm -rf ./train_data/ic15_data
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+ cd ../
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_rec" ]];then
+ rm -rf ./train_data/ic15_data
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+ cd ../
+ cd ../
+ fi
if [[ ${model_name} =~ "ch_ppocr_server_v2_0_det" || ${model_name} =~ "ch_PP-OCRv3_det" ]];then
rm -rf ./train_data/icdar2015
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
@@ -88,7 +124,7 @@ if [ ${MODE} = "benchmark_train" ];then
ln -s ./ic15_data_benckmark ./ic15_data
cd ../
fi
- if [[ ${model_name} =~ "ch_PP-OCRv2_rec" || ${model_name} =~ "ch_PP-OCRv3_rec" ]];then
+ if [[ ${model_name} =~ "ch_PP-OCRv2_rec" || ${model_name} =~ "ch_PP-OCRv3_rec" || ${model_name} =~ "ch_PP-OCRv4_mobile_rec" || ${model_name} =~ "ch_PP-OCRv4_server_rec" ]];then
rm -rf ./train_data/ic15_data
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
cd ./train_data/ && tar xf ic15_data_benckmark.tar
@@ -138,6 +174,26 @@ if [ ${MODE} = "benchmark_train" ];then
cd ../
fi
+ if [ ${model_name} == "table_master" ];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar --no-check-certificate
+ cd ./pretrain_models/ && tar xf table_structure_tablemaster_train.tar && cd ../
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/StructureLabel_val_500.tar --no-check-certificate
+ cd ./train_data/ && tar xf StructureLabel_val_500.tar
+ cd ../
+ fi
+ if [ ${model_name} == "rec_svtrnet" ]; then
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+
+ for i in `seq 10`;do cp rec_gt_train.txt dup$i.txt;done
+ cat dup* > rec_gt_train.txt && rm -rf dup*
+
+ cd ../
+ cd ../
+ fi
fi
if [ ${MODE} = "lite_train_lite_infer" ];then
@@ -150,7 +206,9 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
# pretrain lite train data
wget -nc -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar --no-check-certificate
- cd ./pretrain_models/ && tar xf det_mv3_db_v2.0_train.tar && cd ../
+ cd ./pretrain_models/
+ tar xf det_mv3_db_v2.0_train.tar
+ cd ../
if [[ ${model_name} =~ "ch_PP-OCRv2_det" ]];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv2_det_distill_train.tar && cd ../
@@ -159,6 +217,12 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv3_det_distill_train.tar && cd ../
fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPLCNetV3_x0_75_ocr_det.pdparams --no-check-certificate
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPHGNet_small_ocr_det.pdparams --no-check-certificate
+ fi
if [ ${model_name} == "en_table_structure" ] || [ ${model_name} == "en_table_structure_PACT" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf en_ppocr_mobile_v2.0_table_structure_train.tar && cd ../
@@ -179,6 +243,8 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
if [ ${model_name} == "table_master" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf table_structure_tablemaster_train.tar && cd ../
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/StructureLabel_val_500.tar --no-check-certificate
+ cd ./train_data/ && tar xf StructureLabel_val_500.tar && cd ../
fi
rm -rf ./train_data/icdar2015
rm -rf ./train_data/ic15_data
@@ -366,7 +432,7 @@ elif [ ${MODE} = "whole_infer" ];then
python_name_list=$(func_parser_value "${lines[2]}")
array=(${python_name_list})
python_name=${array[0]}
- ${python_name} -m pip install paddleslim --force-reinstall
+ ${python_name} -m pip install paddleslim
${python_name} -m pip install -r requirements.txt
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ch_det_data_50.tar --no-check-certificate
wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/rec_inference.tar --no-check-certificate
diff --git a/test_tipc/supplementary/data_loader.py b/test_tipc/supplementary/data_loader.py
index 049e7b2d36306d4bb7264d1c45a072ed84bbba60..f0245dd27cc5bb5d7272d6950f27b4ae0ba899f2 100644
--- a/test_tipc/supplementary/data_loader.py
+++ b/test_tipc/supplementary/data_loader.py
@@ -1,7 +1,6 @@
import numpy as np
from paddle.vision.datasets import Cifar100
from paddle.vision.transforms import Normalize
-from paddle.fluid.dataloader.collate import default_collate_fn
import signal
import os
from paddle.io import Dataset, DataLoader, DistributedBatchSampler
diff --git a/test_tipc/supplementary/train.py b/test_tipc/supplementary/train.py
index e632d1d1803a85144bc750c3ff6ff51b1eb65973..f582123407956b335aac8a0845cae50769dae829 100644
--- a/test_tipc/supplementary/train.py
+++ b/test_tipc/supplementary/train.py
@@ -71,7 +71,7 @@ def amp_scaler(config):
'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
'FLAGS_max_inplace_grad_add': 8,
}
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["AMP"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["AMP"].get("use_dynamic_loss_scaling",
False)
@@ -168,22 +168,22 @@ def train(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
model,
@@ -276,22 +276,22 @@ def train_distill(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model._layers.student)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
@@ -401,22 +401,22 @@ def train_distill_multiopt(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}, loss1: {avg_loss1.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}, loss1: {float(avg_loss1)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model._layers.student)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
model, [optimizer, optimizer1],
@@ -450,7 +450,7 @@ def eval(config, model):
labels = paddle.concat(labels, axis=0)
acc = metric_func(outs, labels)
- strs = f"The metric are as follows: acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs = f"The metric are as follows: acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
logger.info(strs)
return acc
diff --git a/test_tipc/test_serving_infer_cpp.sh b/test_tipc/test_serving_infer_cpp.sh
index 10ddecf3fa26805fef7bc6ae10d78ee5e741cd27..6de685682a20acda0f97e64abfa20e61284f9b1b 100644
--- a/test_tipc/test_serving_infer_cpp.sh
+++ b/test_tipc/test_serving_infer_cpp.sh
@@ -103,7 +103,9 @@ function func_serving(){
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
status_check $last_status "${cpp_client_cmd}" "${status_log}" "${model_name}" "${_save_log_path}"
- ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ #ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ ${python_list[0]} ${web_service_py} stop
+ sleep 5s
else
server_log_path="${LOG_PATH}/cpp_server_gpu.log"
web_service_cpp_cmd="nohup ${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} ${gpu_key} ${gpu_id} > ${server_log_path} 2>&1 &"
@@ -115,7 +117,8 @@ function func_serving(){
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
status_check $last_status "${cpp_client_cmd}" "${status_log}" "${model_name}" "${_save_log_path}"
- ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ #ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ ${python_list[0]} ${web_service_py} stop
fi
done
}
diff --git a/test_tipc/test_train_inference_python.sh b/test_tipc/test_train_inference_python.sh
index e182fa57f060c81af012a5da89b892bde02b4a2b..9a94db858cb44355745ebb0399a227fe24e2dc73 100644
--- a/test_tipc/test_train_inference_python.sh
+++ b/test_tipc/test_train_inference_python.sh
@@ -5,7 +5,7 @@ FILENAME=$1
# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer', 'whole_infer']
MODE=$2
-dataline=$(awk 'NR==1, NR==51{print}' $FILENAME)
+dataline=$(awk 'NR>=1{print}' $FILENAME)
# parser params
IFS=$'\n'
@@ -88,11 +88,14 @@ benchmark_value=$(func_parser_value "${lines[49]}")
infer_key1=$(func_parser_key "${lines[50]}")
infer_value1=$(func_parser_value "${lines[50]}")
+line_num=`grep -n -w "to_static_train_benchmark_params" $FILENAME | cut -d ":" -f 1`
+to_static_key=$(func_parser_key "${lines[line_num]}")
+to_static_trainer=$(func_parser_value "${lines[line_num]}")
+
LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
mkdir -p ${LOG_PATH}
status_log="${LOG_PATH}/results_python.log"
-
function func_inference(){
IFS='|'
_python=$1
@@ -253,9 +256,9 @@ else
elif [ ${trainer} = "${distill_key}" ]; then
run_train=${distill_trainer}
run_export=${distill_export}
- elif [ ${trainer} = ${trainer_key1} ]; then
- run_train=${trainer_value1}
- run_export=${export_value1}
+ elif [ ${trainer} = "${to_static_key}" ]; then
+ run_train="${norm_trainer} ${to_static_trainer}"
+ run_export=${norm_export}
elif [[ ${trainer} = ${trainer_key2} ]]; then
run_train=${trainer_value2}
run_export=${export_value2}
@@ -289,11 +292,11 @@ else
set_save_model=$(func_set_params "${save_model_key}" "${save_log}")
if [ ${#gpu} -le 2 ];then # train with cpu or single gpu
- cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_train_params1} ${set_amp_config} "
+ cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
elif [ ${#ips} -le 15 ];then # train with multi-gpu
- cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_train_params1} ${set_amp_config}"
+ cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
else # train with multi-machine
- cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_train_params1} ${set_amp_config}"
+ cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
fi
# run train
eval $cmd
@@ -337,5 +340,4 @@ else
done # done with: for trainer in ${trainer_list[*]}; do
done # done with: for autocast in ${autocast_list[*]}; do
done # done with: for gpu in ${gpu_list[*]}; do
-fi # end if [ ${MODE} = "infer" ]; then
-
+fi # end if [ ${MODE} = "infer" ]; then
\ No newline at end of file
diff --git a/test_tipc/test_train_inference_python_npu.sh b/test_tipc/test_train_inference_python_npu.sh
index bab70fc78ee902515c0fccb57d9215d86f2a6589..4341ceeaebfdbef2b29e40e9b2361e6ab6ab7a61 100644
--- a/test_tipc/test_train_inference_python_npu.sh
+++ b/test_tipc/test_train_inference_python_npu.sh
@@ -29,18 +29,28 @@ fi
sed -i 's/use_gpu/use_npu/g' $FILENAME
# disable benchmark as AutoLog required nvidia-smi command
sed -i 's/--benchmark:True/--benchmark:False/g' $FILENAME
+# python has been updated to version 3.9 for npu backend
+sed -i "s/python3.7/python3.9/g" $FILENAME
dataline=`cat $FILENAME`
# parser params
IFS=$'\n'
lines=(${dataline})
+modelname=$(echo ${lines[1]} | cut -d ":" -f2)
+if [ $modelname == "rec_r31_sar" ] || [ $modelname == "rec_mtb_nrtr" ]; then
+ sed -i "s/Global.epoch_num:lite_train_lite_infer=2/Global.epoch_num:lite_train_lite_infer=1/g" $FILENAME
+ sed -i "s/gpu_list:0|0,1/gpu_list:0,1/g" $FILENAME
+ sed -i "s/Global.use_npu:True|True/Global.use_npu:True/g" $FILENAME
+fi
+
# replace training config file
grep -n 'tools/.*yml' $FILENAME | cut -d ":" -f 1 \
| while read line_num ; do
train_cmd=$(func_parser_value "${lines[line_num-1]}")
trainer_config=$(func_parser_config ${train_cmd})
sed -i 's/use_gpu/use_npu/g' "$REPO_ROOT_PATH/$trainer_config"
+ sed -i 's/use_sync_bn: True/use_sync_bn: False/g' "$REPO_ROOT_PATH/$trainer_config"
done
# change gpu to npu in execution script
diff --git a/tools/eval.py b/tools/eval.py
index 21f4d94d5e4ed560b8775c8827ffdbbd00355218..b4c69b6d37532103f1316eb3b7a14b472d741ed3 100755
--- a/tools/eval.py
+++ b/tools/eval.py
@@ -24,7 +24,7 @@ sys.path.insert(0, __dir__)
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
import paddle
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
from ppocr.metrics import build_metric
@@ -35,6 +35,7 @@ import tools.program as program
def main():
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
@@ -54,8 +55,12 @@ def main():
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -66,8 +71,11 @@ def main():
out_channels_list = {}
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
@@ -75,7 +83,8 @@ def main():
model = build_model(config['Architecture'])
extra_input_models = [
- "SRN", "NRTR", "SAR", "SEED", "SVTR", "VisionLAN", "RobustScanner"
+ "SRN", "NRTR", "SAR", "SEED", "SVTR", "SVTR_LCNet", "VisionLAN",
+ "RobustScanner", "SVTR_HGNet"
]
extra_input = False
if config['Architecture']['algorithm'] == 'Distillation':
@@ -103,7 +112,7 @@ def main():
'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
'FLAGS_max_inplace_grad_add': 8,
}
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["Global"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["Global"].get(
"use_dynamic_loss_scaling", False)
diff --git a/tools/export_center.py b/tools/export_center.py
index 30b9c33499b8d0c8044682c6a078e00f683c1d7c..3f7a883528525bebe037de7f78847fd77a059142 100644
--- a/tools/export_center.py
+++ b/tools/export_center.py
@@ -24,7 +24,7 @@ __dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
from ppocr.utils.save_load import load_model
@@ -40,6 +40,7 @@ def main():
'data_dir']
config['Eval']['dataset']['label_file_list'] = config['Train']['dataset'][
'label_file_list']
+ set_signal_handlers()
eval_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
diff --git a/tools/export_model.py b/tools/export_model.py
index 4b90fcae435619a53a3def8cc4dc46b4e2963bff..cc515164bf64f0038856a3b97975562335eb1dc2 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -62,17 +62,17 @@ def export_single_model(model,
shape=[None], dtype="float32")]
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] in ["SVTR_LCNet", "SVTR_HGNet"]:
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 48, -1], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "SVTR":
- if arch_config["Head"]["name"] == 'MultiHead':
- other_shape = [
- paddle.static.InputSpec(
- shape=[None, 3, 48, -1], dtype="float32"),
- ]
- else:
- other_shape = [
- paddle.static.InputSpec(
- shape=[None] + input_shape, dtype="float32"),
- ]
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None] + input_shape, dtype="float32"),
+ ]
model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
other_shape = [
@@ -105,6 +105,12 @@ def export_single_model(model,
shape=[None, 1, 32, 100], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == 'SATRN':
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 32, 100], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "VisionLAN":
other_shape = [
paddle.static.InputSpec(
@@ -181,6 +187,13 @@ def export_single_model(model,
shape=[None] + infer_shape, dtype="float32")
])
+ if arch_config["model_type"] != "sr" and arch_config["Backbone"][
+ "name"] == "PPLCNetV3":
+ # for rep lcnetv3
+ for layer in model.sublayers():
+ if hasattr(layer, "rep") and not getattr(layer, "is_repped"):
+ layer.rep()
+
if quanter is None:
paddle.jit.save(model, save_path)
else:
@@ -212,8 +225,12 @@ def main():
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -228,8 +245,11 @@ def main():
char_num = len(getattr(post_process_class, 'character'))
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
diff --git a/tools/infer/predict_det.py b/tools/infer/predict_det.py
index 1b4446a6717bccdc5b3de4ba70e058885479be84..6c5c36cf86febef406609bf5022cfd2ee776756f 100755
--- a/tools/infer/predict_det.py
+++ b/tools/infer/predict_det.py
@@ -143,7 +143,9 @@ class TextDetector(object):
if self.use_onnx:
img_h, img_w = self.input_tensor.shape[2:]
- if img_h is not None and img_w is not None and img_h > 0 and img_w > 0:
+ if isinstance(img_h, str) or isinstance(img_w, str):
+ pass
+ elif img_h is not None and img_w is not None and img_h > 0 and img_w > 0:
pre_process_list[0] = {
'DetResizeForTest': {
'image_shape': [img_h, img_w]
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index b3ef557c09fb74990b65c266afa5d5c77960b7ed..9dd33dc7b68e05cc218a9a0746cb58ccb5a8ebb2 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -106,6 +106,13 @@ class TextRecognizer(object):
"character_dict_path": None,
"use_space_char": args.use_space_char
}
+ elif self.rec_algorithm == "SATRN":
+ postprocess_params = {
+ 'name': 'SATRNLabelDecode',
+ "character_dict_path": args.rec_char_dict_path,
+ "use_space_char": args.use_space_char,
+ "rm_symbol": True
+ }
elif self.rec_algorithm == "PREN":
postprocess_params = {'name': 'PRENLabelDecode'}
elif self.rec_algorithm == "CAN":
@@ -116,6 +123,7 @@ class TextRecognizer(object):
"use_space_char": args.use_space_char
}
self.postprocess_op = build_post_process(postprocess_params)
+ self.postprocess_params = postprocess_params
self.predictor, self.input_tensor, self.output_tensors, self.config = \
utility.create_predictor(args, 'rec', logger)
self.benchmark = args.benchmark
@@ -139,6 +147,7 @@ class TextRecognizer(object):
],
warmup=0,
logger=logger)
+ self.return_word_box = args.return_word_box
def resize_norm_img(self, img, max_wh_ratio):
imgC, imgH, imgW = self.rec_image_shape
@@ -149,7 +158,7 @@ class TextRecognizer(object):
if self.rec_algorithm == 'ViTSTR':
img = image_pil.resize([imgW, imgH], Image.BICUBIC)
else:
- img = image_pil.resize([imgW, imgH], Image.ANTIALIAS)
+ img = image_pil.resize([imgW, imgH], Image.Resampling.LANCZOS)
img = np.array(img)
norm_img = np.expand_dims(img, -1)
norm_img = norm_img.transpose((2, 0, 1))
@@ -173,9 +182,10 @@ class TextRecognizer(object):
imgW = int((imgH * max_wh_ratio))
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
- if w is not None and w > 0:
+ if isinstance(w, str):
+ pass
+ elif w is not None and w > 0:
imgW = w
-
h, w = img.shape[:2]
ratio = w / float(h)
if math.ceil(imgH * ratio) > imgW:
@@ -407,11 +417,12 @@ class TextRecognizer(object):
valid_ratios = []
imgC, imgH, imgW = self.rec_image_shape[:3]
max_wh_ratio = imgW / imgH
- # max_wh_ratio = 0
+ wh_ratio_list = []
for ino in range(beg_img_no, end_img_no):
h, w = img_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
+ wh_ratio_list.append(wh_ratio)
for ino in range(beg_img_no, end_img_no):
if self.rec_algorithm == "SAR":
norm_img, _, _, valid_ratio = self.resize_norm_img_sar(
@@ -428,7 +439,7 @@ class TextRecognizer(object):
gsrm_slf_attn_bias1_list.append(norm_img[3])
gsrm_slf_attn_bias2_list.append(norm_img[4])
norm_img_batch.append(norm_img[0])
- elif self.rec_algorithm == "SVTR":
+ elif self.rec_algorithm in ["SVTR", "SATRN"]:
norm_img = self.resize_norm_img_svtr(img_list[indices[ino]],
self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
@@ -616,7 +627,10 @@ class TextRecognizer(object):
preds = outputs
else:
preds = outputs[0]
- rec_result = self.postprocess_op(preds)
+ if self.postprocess_params['name'] == 'CTCLabelDecode':
+ rec_result = self.postprocess_op(preds, return_word_box=self.return_word_box, wh_ratio_list=wh_ratio_list, max_wh_ratio=max_wh_ratio)
+ else:
+ rec_result = self.postprocess_op(preds)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
if self.benchmark:
diff --git a/tools/infer/predict_system.py b/tools/infer/predict_system.py
index affd0d1bcd1283be02ead3cd61c01c375b49bdf9..8af45b4cf52eb6355c9d4e08bc609e6ea91dfb43 100755
--- a/tools/infer/predict_system.py
+++ b/tools/infer/predict_system.py
@@ -34,7 +34,7 @@ import tools.infer.predict_det as predict_det
import tools.infer.predict_cls as predict_cls
from ppocr.utils.utility import get_image_file_list, check_and_read
from ppocr.utils.logging import get_logger
-from tools.infer.utility import draw_ocr_box_txt, get_rotate_crop_image
+from tools.infer.utility import draw_ocr_box_txt, get_rotate_crop_image, get_minarea_rect_crop
logger = get_logger()
@@ -65,40 +65,53 @@ class TextSystem(object):
self.crop_image_res_index += bbox_num
def __call__(self, img, cls=True):
- time_dict = {'det': 0, 'rec': 0, 'csl': 0, 'all': 0}
+ time_dict = {'det': 0, 'rec': 0, 'cls': 0, 'all': 0}
+
+ if img is None:
+ logger.debug("no valid image provided")
+ return None, None, time_dict
+
start = time.time()
ori_im = img.copy()
dt_boxes, elapse = self.text_detector(img)
time_dict['det'] = elapse
- logger.debug("dt_boxes num : {}, elapse : {}".format(
- len(dt_boxes), elapse))
+
if dt_boxes is None:
- return None, None
+ logger.debug("no dt_boxes found, elapsed : {}".format(elapse))
+ end = time.time()
+ time_dict['all'] = end - start
+ return None, None, time_dict
+ else:
+ logger.debug("dt_boxes num : {}, elapsed : {}".format(
+ len(dt_boxes), elapse))
img_crop_list = []
dt_boxes = sorted_boxes(dt_boxes)
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
- img_crop = get_rotate_crop_image(ori_im, tmp_box)
+ if self.args.det_box_type == "quad":
+ img_crop = get_rotate_crop_image(ori_im, tmp_box)
+ else:
+ img_crop = get_minarea_rect_crop(ori_im, tmp_box)
img_crop_list.append(img_crop)
if self.use_angle_cls and cls:
img_crop_list, angle_list, elapse = self.text_classifier(
img_crop_list)
time_dict['cls'] = elapse
- logger.debug("cls num : {}, elapse : {}".format(
+ logger.debug("cls num : {}, elapsed : {}".format(
len(img_crop_list), elapse))
rec_res, elapse = self.text_recognizer(img_crop_list)
time_dict['rec'] = elapse
- logger.debug("rec_res num : {}, elapse : {}".format(
+ logger.debug("rec_res num : {}, elapsed : {}".format(
len(rec_res), elapse))
if self.args.save_crop_res:
self.draw_crop_rec_res(self.args.crop_res_save_dir, img_crop_list,
rec_res)
filter_boxes, filter_rec_res = [], []
for box, rec_result in zip(dt_boxes, rec_res):
- text, score = rec_result
+ text, score = rec_result[0], rec_result[1]
if score >= self.drop_score:
filter_boxes.append(box)
filter_rec_res.append(rec_result)
@@ -120,7 +133,7 @@ def sorted_boxes(dt_boxes):
_boxes = list(sorted_boxes)
for i in range(num_boxes - 1):
- for j in range(i, 0, -1):
+ for j in range(i, -1, -1):
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and \
(_boxes[j + 1][0][0] < _boxes[j][0][0]):
tmp = _boxes[j]
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index 34cad2590f2904f79709530acf841033c89088e0..b064cbf18941a40bdca57e4d7e4ec68dc42e6fc6 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -19,6 +19,7 @@ import platform
import cv2
import numpy as np
import paddle
+import PIL
from PIL import Image, ImageDraw, ImageFont
import math
from paddle import inference
@@ -28,8 +29,10 @@ from ppocr.utils.logging import get_logger
def str2bool(v):
- return v.lower() in ("true", "t", "1")
+ return v.lower() in ("true", "yes", "t", "y", "1")
+def str2int_tuple(v):
+ return tuple([int(i.strip()) for i in v.split(",")])
def init_args():
parser = argparse.ArgumentParser()
@@ -42,6 +45,7 @@ def init_args():
parser.add_argument("--min_subgraph_size", type=int, default=15)
parser.add_argument("--precision", type=str, default="fp32")
parser.add_argument("--gpu_mem", type=int, default=500)
+ parser.add_argument("--gpu_id", type=int, default=0)
# params for text detector
parser.add_argument("--image_dir", type=str)
@@ -144,6 +148,10 @@ def init_args():
parser.add_argument("--show_log", type=str2bool, default=True)
parser.add_argument("--use_onnx", type=str2bool, default=False)
+
+ # extended function
+ parser.add_argument("--return_word_box", type=str2bool, default=False, help='Whether return the bbox of each word (split by space) or chinese character. Only used in ppstructure for layout recovery')
+
return parser
@@ -181,7 +189,10 @@ def create_predictor(args, mode, logger):
if not os.path.exists(model_file_path):
raise ValueError("not find model file path {}".format(
model_file_path))
- sess = ort.InferenceSession(model_file_path)
+ if args.use_gpu:
+ sess = ort.InferenceSession(model_file_path, providers=['CUDAExecutionProvider'])
+ else:
+ sess = ort.InferenceSession(model_file_path)
return sess, sess.get_inputs()[0], None, None
else:
@@ -219,7 +230,7 @@ def create_predictor(args, mode, logger):
logger.warning(
"GPU is not found in current device by nvidia-smi. Please check your device or ignore it if run on jetson."
)
- config.enable_use_gpu(args.gpu_mem, 0)
+ config.enable_use_gpu(args.gpu_mem, args.gpu_id)
if args.use_tensorrt:
config.enable_tensorrt_engine(
workspace_size=1 << 30,
@@ -245,7 +256,7 @@ def create_predictor(args, mode, logger):
logger.info("Please keep your paddlepaddle-gpu >= 2.3.0!")
elif args.use_npu:
- config.enable_npu()
+ config.enable_custom_device("npu")
elif args.use_xpu:
config.enable_xpu(10 * 1024 * 1024)
else:
@@ -290,7 +301,9 @@ def create_predictor(args, mode, logger):
def get_output_tensors(args, mode, predictor):
output_names = predictor.get_output_names()
output_tensors = []
- if mode == "rec" and args.rec_algorithm in ["CRNN", "SVTR_LCNet"]:
+ if mode == "rec" and args.rec_algorithm in [
+ "CRNN", "SVTR_LCNet", "SVTR_HGNet"
+ ]:
output_name = 'softmax_0.tmp_0'
if output_name in output_names:
return [predictor.get_output_handle(output_name)]
@@ -310,7 +323,7 @@ def get_infer_gpuid():
if sysstr == "Windows":
return 0
- if not paddle.fluid.core.is_compiled_with_rocm():
+ if not paddle.device.is_compiled_with_rocm:
cmd = "env | grep CUDA_VISIBLE_DEVICES"
else:
cmd = "env | grep HIP_VISIBLE_DEVICES"
@@ -468,7 +481,11 @@ def draw_box_txt_fine(img_size, box, txt, font_path="./doc/fonts/simfang.ttf"):
def create_font(txt, sz, font_path="./doc/fonts/simfang.ttf"):
font_size = int(sz[1] * 0.99)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
- length = font.getsize(txt)[0]
+ if int(PIL.__version__.split('.')[0]) < 10:
+ length = font.getsize(txt)[0]
+ else:
+ length = font.getlength(txt)
+
if length > sz[0]:
font_size = int(font_size * sz[0] / length)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
@@ -629,6 +646,29 @@ def get_rotate_crop_image(img, points):
return dst_img
+def get_minarea_rect_crop(img, points):
+ bounding_box = cv2.minAreaRect(np.array(points).astype(np.int32))
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_a, index_b, index_c, index_d = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_a = 0
+ index_d = 1
+ else:
+ index_a = 1
+ index_d = 0
+ if points[3][1] > points[2][1]:
+ index_b = 2
+ index_c = 3
+ else:
+ index_b = 3
+ index_c = 2
+
+ box = [points[index_a], points[index_b], points[index_c], points[index_d]]
+ crop_img = get_rotate_crop_image(img, np.array(box))
+ return crop_img
+
+
def check_gpu(use_gpu):
if use_gpu and not paddle.is_compiled_with_cuda():
use_gpu = False
diff --git a/tools/infer_det.py b/tools/infer_det.py
index f253e8f2876a5942538f18e93dfdada4391875b2..097d032b99c7d25a3e9e3b1d781bbdbe4dde62fa 100755
--- a/tools/infer_det.py
+++ b/tools/infer_det.py
@@ -40,17 +40,16 @@ import tools.program as program
def draw_det_res(dt_boxes, config, img, img_name, save_path):
- if len(dt_boxes) > 0:
- import cv2
- src_im = img
- for box in dt_boxes:
- box = np.array(box).astype(np.int32).reshape((-1, 1, 2))
- cv2.polylines(src_im, [box], True, color=(255, 255, 0), thickness=2)
- if not os.path.exists(save_path):
- os.makedirs(save_path)
- save_path = os.path.join(save_path, os.path.basename(img_name))
- cv2.imwrite(save_path, src_im)
- logger.info("The detected Image saved in {}".format(save_path))
+ import cv2
+ src_im = img
+ for box in dt_boxes:
+ box = np.array(box).astype(np.int32).reshape((-1, 1, 2))
+ cv2.polylines(src_im, [box], True, color=(255, 255, 0), thickness=2)
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+ save_path = os.path.join(save_path, os.path.basename(img_name))
+ cv2.imwrite(save_path, src_im)
+ logger.info("The detected Image saved in {}".format(save_path))
@paddle.no_grad()
diff --git a/tools/infer_kie_token_ser_re.py b/tools/infer_kie_token_ser_re.py
index c4fa2c927ab93cfa9082e51f08f8d6e1c35fe29e..76120a913f36c815cbd3b9314523ea91e3290065 100755
--- a/tools/infer_kie_token_ser_re.py
+++ b/tools/infer_kie_token_ser_re.py
@@ -81,7 +81,7 @@ def make_input(ser_inputs, ser_results):
end.append(entity['end'])
label.append(entities_labels[res['pred']])
- entities = np.full([max_seq_len + 1, 3], fill_value=-1)
+ entities = np.full([max_seq_len + 1, 3], fill_value=-1, dtype=np.int64)
entities[0, 0] = len(start)
entities[1:len(start) + 1, 0] = start
entities[0, 1] = len(end)
@@ -98,7 +98,7 @@ def make_input(ser_inputs, ser_results):
head.append(i)
tail.append(j)
- relations = np.full([len(head) + 1, 2], fill_value=-1)
+ relations = np.full([len(head) + 1, 2], fill_value=-1, dtype=np.int64)
relations[0, 0] = len(head)
relations[1:len(head) + 1, 0] = head
relations[0, 1] = len(tail)
diff --git a/tools/infer_rec.py b/tools/infer_rec.py
index 29aab9b57853b16bf615c893c30351a403270b57..80986ccdebb5b0e91cb843933c1a0ee6914ca671 100755
--- a/tools/infer_rec.py
+++ b/tools/infer_rec.py
@@ -48,34 +48,41 @@ def main():
# build model
if hasattr(post_process_class, 'character'):
char_num = len(getattr(post_process_class, 'character'))
- if config['Architecture']["algorithm"] in ["Distillation",
+ if config["Architecture"]["algorithm"] in ["Distillation",
]: # distillation model
- for key in config['Architecture']["Models"]:
- if config['Architecture']['Models'][key]['Head'][
- 'name'] == 'MultiHead': # for multi head
+ for key in config["Architecture"]["Models"]:
+ if config["Architecture"]["Models"][key]["Head"][
+ "name"] == 'MultiHead': # multi head
out_channels_list = {}
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ config["Architecture"]["Models"][key]["Head"][
+ "out_channels"] = char_num
elif config['Architecture']['Head'][
- 'name'] == 'MultiHead': # for multi head loss
+ 'name'] == 'MultiHead': # multi head
out_channels_list = {}
+ char_num = len(getattr(post_process_class, 'character'))
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
- config['Architecture']["Head"]['out_channels'] = char_num
-
+ config["Architecture"]["Head"]["out_channels"] = char_num
model = build_model(config['Architecture'])
load_model(config, model)
diff --git a/tools/program.py b/tools/program.py
index afb8a47254b9847e4a4d432b7f17902c3ee78725..511ee9dd1f12273eb773b6f2e29a3955940721ee 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -134,9 +134,18 @@ def check_device(use_gpu, use_xpu=False, use_npu=False, use_mlu=False):
if use_xpu and not paddle.device.is_compiled_with_xpu():
print(err.format("use_xpu", "xpu", "xpu", "use_xpu"))
sys.exit(1)
- if use_npu and not paddle.device.is_compiled_with_npu():
- print(err.format("use_npu", "npu", "npu", "use_npu"))
- sys.exit(1)
+ if use_npu:
+ if int(paddle.version.major) != 0 and int(
+ paddle.version.major) <= 2 and int(
+ paddle.version.minor) <= 4:
+ if not paddle.device.is_compiled_with_npu():
+ print(err.format("use_npu", "npu", "npu", "use_npu"))
+ sys.exit(1)
+ # is_compiled_with_npu() has been updated after paddle-2.4
+ else:
+ if not paddle.device.is_compiled_with_custom_device("npu"):
+ print(err.format("use_npu", "npu", "npu", "use_npu"))
+ sys.exit(1)
if use_mlu and not paddle.device.is_compiled_with_mlu():
print(err.format("use_mlu", "mlu", "mlu", "use_mlu"))
sys.exit(1)
@@ -179,7 +188,9 @@ def train(config,
log_writer=None,
scaler=None,
amp_level='O2',
- amp_custom_black_list=[]):
+ amp_custom_black_list=[],
+ amp_custom_white_list=[],
+ amp_dtype='float16'):
cal_metric_during_train = config['Global'].get('cal_metric_during_train',
False)
calc_epoch_interval = config['Global'].get('calc_epoch_interval', 1)
@@ -219,8 +230,8 @@ def train(config,
use_srn = config['Architecture']['algorithm'] == "SRN"
extra_input_models = [
- "SRN", "NRTR", "SAR", "SEED", "SVTR", "SPIN", "VisionLAN",
- "RobustScanner", "RFL", 'DRRG'
+ "SRN", "NRTR", "SAR", "SEED", "SVTR", "SVTR_LCNet", "SPIN", "VisionLAN",
+ "RobustScanner", "RFL", 'DRRG', 'SATRN', 'SVTR_HGNet'
]
extra_input = False
if config['Architecture']['algorithm'] == 'Distillation':
@@ -268,7 +279,9 @@ def train(config,
if scaler:
with paddle.amp.auto_cast(
level=amp_level,
- custom_black_list=amp_custom_black_list):
+ custom_black_list=amp_custom_black_list,
+ custom_white_list=amp_custom_white_list,
+ dtype=amp_dtype):
if model_type == 'table' or extra_input:
preds = model(images, data=batch[1:])
elif model_type in ["kie"]:
@@ -333,7 +346,10 @@ def train(config,
lr_scheduler.step()
# logger and visualdl
- stats = {k: v.numpy().mean() for k, v in loss.items()}
+ stats = {
+ k: float(v) if v.shape == [] else v.numpy().mean()
+ for k, v in loss.items()
+ }
stats['lr'] = lr
train_stats.update(stats)
@@ -382,7 +398,9 @@ def train(config,
extra_input=extra_input,
scaler=scaler,
amp_level=amp_level,
- amp_custom_black_list=amp_custom_black_list)
+ amp_custom_black_list=amp_custom_black_list,
+ amp_custom_white_list=amp_custom_white_list,
+ amp_dtype=amp_dtype)
cur_metric_str = 'cur metric, {}'.format(', '.join(
['{}: {}'.format(k, v) for k, v in cur_metric.items()]))
logger.info(cur_metric_str)
@@ -475,7 +493,9 @@ def eval(model,
extra_input=False,
scaler=None,
amp_level='O2',
- amp_custom_black_list=[]):
+ amp_custom_black_list=[],
+ amp_custom_white_list=[],
+ amp_dtype='float16'):
model.eval()
with paddle.no_grad():
total_frame = 0.0
@@ -498,7 +518,8 @@ def eval(model,
if scaler:
with paddle.amp.auto_cast(
level=amp_level,
- custom_black_list=amp_custom_black_list):
+ custom_black_list=amp_custom_black_list,
+ dtype=amp_dtype):
if model_type == 'table' or extra_input:
preds = model(images, data=batch[1:])
elif model_type in ["kie"]:
@@ -641,9 +662,9 @@ def preprocess(is_train=False):
'EAST', 'DB', 'SAST', 'Rosetta', 'CRNN', 'STARNet', 'RARE', 'SRN',
'CLS', 'PGNet', 'Distillation', 'NRTR', 'TableAttn', 'SAR', 'PSE',
'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'LayoutLMv2', 'PREN', 'FCE',
- 'SVTR', 'ViTSTR', 'ABINet', 'DB++', 'TableMaster', 'SPIN', 'VisionLAN',
- 'Gestalt', 'SLANet', 'RobustScanner', 'CT', 'RFL', 'DRRG', 'CAN',
- 'Telescope'
+ 'SVTR', 'SVTR_LCNet', 'ViTSTR', 'ABINet', 'DB++', 'TableMaster', 'SPIN',
+ 'VisionLAN', 'Gestalt', 'SLANet', 'RobustScanner', 'CT', 'RFL', 'DRRG',
+ 'CAN', 'Telescope', 'SATRN', 'SVTR_HGNet'
]
if use_xpu:
@@ -665,7 +686,7 @@ def preprocess(is_train=False):
if 'use_visualdl' in config['Global'] and config['Global']['use_visualdl']:
save_model_dir = config['Global']['save_model_dir']
- vdl_writer_path = '{}/vdl/'.format(save_model_dir)
+ vdl_writer_path = save_model_dir
log_writer = VDLLogger(vdl_writer_path)
loggers.append(log_writer)
if ('use_wandb' in config['Global'] and
diff --git a/tools/train.py b/tools/train.py
index ff261e85fec10ec974ff763d6c3747faaa47c8d9..85c98eaddfe69c08e0e29921edcb1d26539b871f 100755
--- a/tools/train.py
+++ b/tools/train.py
@@ -27,7 +27,7 @@ import yaml
import paddle
import paddle.distributed as dist
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -41,7 +41,7 @@ import tools.program as program
dist.get_world_size()
-def main(config, device, logger, vdl_writer):
+def main(config, device, logger, vdl_writer, seed):
# init dist environment
if config['Global']['distributed']:
dist.init_parallel_env()
@@ -49,7 +49,8 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
- train_dataloader = build_dataloader(config, 'Train', device, logger)
+ set_signal_handlers()
+ train_dataloader = build_dataloader(config, 'Train', device, logger, seed)
if len(train_dataloader) == 0:
logger.error(
"No Images in train dataset, please ensure\n" +
@@ -60,7 +61,7 @@ def main(config, device, logger, vdl_writer):
return
if config['Eval']:
- valid_dataloader = build_dataloader(config, 'Eval', device, logger)
+ valid_dataloader = build_dataloader(config, 'Eval', device, logger, seed)
else:
valid_dataloader = None
@@ -80,14 +81,22 @@ def main(config, device, logger, vdl_writer):
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
- # update SARLoss params
- assert list(config['Loss']['loss_config_list'][-1].keys())[
- 0] == 'DistillationSARLoss'
- config['Loss']['loss_config_list'][-1][
- 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list = {}
out_channels_list['CTCLabelDecode'] = char_num
- out_channels_list['SARLabelDecode'] = char_num + 2
+ # update SARLoss params
+ if list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss':
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ elif list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationNRTRLoss':
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
+
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -97,19 +106,24 @@ def main(config, device, logger, vdl_writer):
'name'] == 'MultiHead': # for multi head
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
- # update SARLoss params
- assert list(config['Loss']['loss_config_list'][1].keys())[
- 0] == 'SARLoss'
- if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
- config['Loss']['loss_config_list'][1]['SARLoss'] = {
- 'ignore_index': char_num + 1
- }
- else:
- config['Loss']['loss_config_list'][1]['SARLoss'][
- 'ignore_index'] = char_num + 1
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list = {}
out_channels_list['CTCLabelDecode'] = char_num
- out_channels_list['SARLabelDecode'] = char_num + 2
+ # update SARLoss params
+ if list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss':
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ elif list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'NRTRLoss':
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
@@ -147,14 +161,17 @@ def main(config, device, logger, vdl_writer):
use_amp = config["Global"].get("use_amp", False)
amp_level = config["Global"].get("amp_level", 'O2')
+ amp_dtype = config["Global"].get("amp_dtype", 'float16')
amp_custom_black_list = config['Global'].get('amp_custom_black_list', [])
+ amp_custom_white_list = config['Global'].get('amp_custom_white_list', [])
if use_amp:
AMP_RELATED_FLAGS_SETTING = {'FLAGS_max_inplace_grad_add': 8, }
if paddle.is_compiled_with_cuda():
AMP_RELATED_FLAGS_SETTING.update({
- 'FLAGS_cudnn_batchnorm_spatial_persistent': 1
+ 'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
+ 'FLAGS_gemm_use_half_precision_compute_type': 0,
})
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["Global"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["Global"].get(
"use_dynamic_loss_scaling", False)
@@ -166,7 +183,8 @@ def main(config, device, logger, vdl_writer):
models=model,
optimizers=optimizer,
level=amp_level,
- master_weight=True)
+ master_weight=True,
+ dtype=amp_dtype)
else:
scaler = None
@@ -180,7 +198,8 @@ def main(config, device, logger, vdl_writer):
program.train(config, train_dataloader, valid_dataloader, device, model,
loss_class, optimizer, lr_scheduler, post_process_class,
eval_class, pre_best_model_dict, logger, vdl_writer, scaler,
- amp_level, amp_custom_black_list)
+ amp_level, amp_custom_black_list, amp_custom_white_list,
+ amp_dtype)
def test_reader(config, device, logger):
@@ -205,5 +224,5 @@ if __name__ == '__main__':
config, device, logger, vdl_writer = program.preprocess(is_train=True)
seed = config['Global']['seed'] if 'seed' in config['Global'] else 1024
set_seed(seed)
- main(config, device, logger, vdl_writer)
+ main(config, device, logger, vdl_writer, seed)
# test_reader(config, device, logger)
+
+
diff --git a/doc/doc_en/quickstart_en.md b/doc/doc_en/quickstart_en.md
index ea38845f503192705a4d87f3faacdaf25bb27ba9..430f1a7a29ebeeb5401115a439c3a274e456e1d9 100644
--- a/doc/doc_en/quickstart_en.md
+++ b/doc/doc_en/quickstart_en.md
@@ -28,13 +28,13 @@
- If you have CUDA 9 or CUDA 10 installed on your machine, please run the following command to install
```bash
- python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
+ python -m pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
```
- If you have no available GPU on your machine, please run the following command to install the CPU version
```bash
- python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
```
For more software version requirements, please refer to the instructions in [Installation Document](https://www.paddlepaddle.org.cn/install/quick) for operation.
@@ -120,9 +120,10 @@ If you do not use the provided test image, you can replace the following `--imag
```
**Version**
-paddleocr uses the PP-OCRv3 model by default(`--ocr_version PP-OCRv3`). If you want to use other versions, you can set the parameter `--ocr_version`, the specific version description is as follows:
+paddleocr uses the PP-OCRv4 model by default(`--ocr_version PP-OCRv4`). If you want to use other versions, you can set the parameter `--ocr_version`, the specific version description is as follows:
| version name | description |
| --- | --- |
+| PP-OCRv4 | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
| PP-OCRv3 | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
| PP-OCRv2 | only supports Chinese and English detection and recognition, direction classifier, multilingual model is not updated |
| PP-OCR | support Chinese and English detection and recognition, direction classifier, support multilingual recognition |
@@ -223,7 +224,7 @@ from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan`
# to switch the language model in order.
-ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
+ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
img_path = './xxx.pdf'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
@@ -266,4 +267,4 @@ for idx in range(len(result)):
In this section, you have mastered the use of PaddleOCR whl package.
-PaddleOCR is a rich and practical OCR tool library that get through the whole process of data production, model training, compression, inference and deployment, please refer to the [tutorials](../../README.md#tutorials) to start the journey of PaddleOCR.
+PaddleX provides a high-quality ecological model of the paddle. It is a one-stop full-process high-efficiency development platform for training, pressing and pushing. Its mission is to help AI technology to be implemented quickly. The vision is to make everyone an AI Developer! Currently PP-OCRv4 has been launched on PaddleX, you can enter [General OCR](https://aistudio.baidu.com/aistudio/modelsdetail?modelId=286) to experience the whole process of model training, compression and inference deployment.
diff --git a/doc/doc_en/recognition_en.md b/doc/doc_en/recognition_en.md
index 7d31b0ffe28c59ad3397d06fa178bcf8cbb822e9..78917aea90c2082a5fcff8be1342b21bfb8e88d8 100644
--- a/doc/doc_en/recognition_en.md
+++ b/doc/doc_en/recognition_en.md
@@ -15,6 +15,7 @@
* [2.6 Training with knowledge distillation](#kd)
* [2.7 Multi-language Training](#Multi_language)
* [2.8 Training on other platform(Windows/macOS/Linux DCU)](#28)
+ * [2.9 Fine-tuning](#29)
- [3. Evaluation and Test](#3-evaluation-and-test)
* [3.1 Evaluation](#31-evaluation)
* [3.2 Test](#32-test)
@@ -384,6 +385,11 @@ GPU mode is not supported, you need to set `use_gpu` to False in the configurati
- Linux DCU
Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
+
+## 2.9 Fine-tuning
+
+In actual use, it is recommended to load the official pre-trained model and fine-tune it in your own data set. For the fine-tuning method of the recognition model, please refer to: [Model Fine-tuning Tutorial](./finetune_en.md).
+
## 3. Evaluation and Test
diff --git a/doc/doc_en/table_recognition_en.md b/doc/doc_en/table_recognition_en.md
index cff2933df22249353b47f5a0a74098be7dd6a2ae..c0a1aa9d61ebb00e4f7e013ee5feb59b1835c78c 100644
--- a/doc/doc_en/table_recognition_en.md
+++ b/doc/doc_en/table_recognition_en.md
@@ -6,6 +6,7 @@ This article provides a full-process guide for the PaddleOCR table recognition m
- [1.1. DataSet Format](#11-dataset-format)
- [1.2. Data Download](#12-data-download)
- [1.3. Dataset Generation](#13-dataset-generation)
+ - [1.4 Data annotation](#14-data-annotation)
- [2. Training](#2-training)
- [2.1. Start Training](#21-start-training)
- [2.2. Resume Training](#22-resume-training)
@@ -14,6 +15,9 @@ This article provides a full-process guide for the PaddleOCR table recognition m
- [2.5. Distributed Training](#25-distributed-training)
- [2.6. Training on other platform(Windows/macOS/Linux DCU)](#26-training-on-other-platformwindowsmacoslinux-dcu)
- [2.7. Fine-tuning](#27-fine-tuning)
+ - [2.7.1 Dataset](#271-dataset)
+ - [2.7.2 model selection](#272-model-selection)
+ - [2.7.3 Training hyperparameter selection](#273-training-hyperparameter-selection)
- [3. Evaluation and Test](#3-evaluation-and-test)
- [3.1. Evaluation](#31-evaluation)
- [3.2. Test table structure recognition effect](#32-test-table-structure-recognition-effect)
@@ -77,6 +81,10 @@ Some samples are as follows:
|Simple Table||
|Simple Color Table||
+## 1.4 Data annotation
+
+Data annotation can refer to[PPOCRLabel](../../PPOCRLabel/README.md)
+
# 2. Training
PaddleOCR provides training scripts, evaluation scripts, and prediction scripts. In this section, the [SLANet](../../configs/table/SLANet.yml) model will be used as an example:
@@ -226,8 +234,40 @@ Running on a DCU device requires setting the environment variable `export HIP_VI
## 2.7. Fine-tuning
-In the actual use process, it is recommended to load the officially provided pre-training model and fine-tune it in your own data set. For the fine-tuning method of the table recognition model, please refer to: [Model fine-tuning tutorial](./finetune.md).
+### 2.7.1 Dataset
+
+Data number: It is recommended to prepare at least 2000 table recognition datasets for model fine-tuning.
+
+### 2.7.2 model selection
+
+It is recommended to choose the SLANet model (configuration file: [SLANet_ch.yml](../../configs/table/SLANet_ch.yml), pre-training model: [ch_ppstructure_mobile_v2.0_SLANet_train.tar](https://paddleocr.bj.bcebos .com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_train.tar)) for fine-tuning, its accuracy and generalization performance is the best Chinese table pre-training model currently available.
+
+For more table recognition models, please refer to [PP-Structure Series Model Library](../../ppstructure/docs/models_list.md).
+
+### 2.7.3 Training hyperparameter selection
+
+When fine-tuning the model, the most important hyperparameters are the pretrained model path `pretrained_model`, the learning rate `learning_rate`, and some configuration files are shown below.
+
+```yaml
+Global:
+ pretrained_model: ./ch_ppstructure_mobile_v2.0_SLANet_train/best_accuracy.pdparams # Pre-trained model path
+Optimizer:
+ lr:
+ name: Cosine
+ learning_rate: 0.001 #
+ warmup_epoch: 0
+ regularizer:
+ name: 'L2'
+ factor: 0
+```
+
+In the above configuration file, you first need to specify the `pretrained_model` field as the `best_accuracy.pdparams` file path.
+
+The configuration file provided by PaddleOCR is for 4-card training (equivalent to a total batch size of `4*48=192`) and no pre-trained model is loaded. Therefore, in your scenario, the learning rate is the same as the total The batch size needs to be adjusted linearly, for example
+
+* If your scenario is single card training, single card batch_size=48, then the total batch_size=48, it is recommended to adjust the learning rate to about `0.00025`.
+* If your scenario is for single-card training, due to memory limitations, you can only set batch_size=32 for a single card, then the total batch_size=32, it is recommended to adjust the learning rate to about `0.00017`.
# 3. Evaluation and Test
diff --git a/doc/doc_en/whl_en.md b/doc/doc_en/whl_en.md
index 77e80faa688392db5b2959f4fd1705275cb37d6b..5283391e5ef8b35eb56f0355fd70049f40a4ae04 100644
--- a/doc/doc_en/whl_en.md
+++ b/doc/doc_en/whl_en.md
@@ -261,7 +261,7 @@ Output will be a list, each item contains classification result and confidence
## 3 Use custom model
When the built-in model cannot meet the needs, you need to use your own trained model.
-First, refer to the first section of [inference_en.md](./inference_en.md) to convert your det and rec model to inference model, and then use it as follows
+First, refer to [export](./detection_en.md#4-inference) doc to convert your det and rec model to inference model, and then use it as follows
### 3.1 Use by code
@@ -335,7 +335,7 @@ ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to downlo
img_path = 'PaddleOCR/doc/imgs/11.jpg'
img = cv2.imread(img_path)
# img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY), If your own training model supports grayscale images, you can uncomment this line
-result = ocr.ocr(img_path, cls=True)
+result = ocr.ocr(img, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
diff --git a/doc/joinus.PNG b/doc/joinus.PNG
index 6489247e05d70896e2ca8a5929948437c6c82b5f..aef92ec8d1f61f6fa8766e8e7a9e56993a3e6f13 100644
Binary files a/doc/joinus.PNG and b/doc/joinus.PNG differ
diff --git a/doc/joinus_paddlex.jpg b/doc/joinus_paddlex.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6b70dda865534210d35caa16497d49328d6dd25b
Binary files /dev/null and b/doc/joinus_paddlex.jpg differ
diff --git a/doc/ppocr_v4/DF.png b/doc/ppocr_v4/DF.png
new file mode 100644
index 0000000000000000000000000000000000000000..f14953d4811adb4d77fe020eaaa325c89dffc4ce
Binary files /dev/null and b/doc/ppocr_v4/DF.png differ
diff --git a/doc/ppocr_v4/PFHead.png b/doc/ppocr_v4/PFHead.png
new file mode 100644
index 0000000000000000000000000000000000000000..3728dc44e5c86c0ba80705ad83ada65da390928d
Binary files /dev/null and b/doc/ppocr_v4/PFHead.png differ
diff --git a/doc/ppocr_v4/multi_scale.png b/doc/ppocr_v4/multi_scale.png
new file mode 100644
index 0000000000000000000000000000000000000000..673d306399db004cbb66474368ac5055e48dbe8f
Binary files /dev/null and b/doc/ppocr_v4/multi_scale.png differ
diff --git a/doc/ppocr_v4/ppocrv4_det_cml.png b/doc/ppocr_v4/ppocrv4_det_cml.png
new file mode 100644
index 0000000000000000000000000000000000000000..9132c0a67c4215cfe19af27628ee37cfbab44720
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_det_cml.png differ
diff --git a/doc/ppocr_v4/ppocrv4_framework.png b/doc/ppocr_v4/ppocrv4_framework.png
new file mode 100644
index 0000000000000000000000000000000000000000..4aac40bae8e67b0b4964ddd4e84445845049bbad
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_framework.png differ
diff --git a/doc/ppocr_v4/ppocrv4_gtc.png b/doc/ppocr_v4/ppocrv4_gtc.png
new file mode 100644
index 0000000000000000000000000000000000000000..7e6a3f5c13ca4c3012d0dd98ba857153c75e607a
Binary files /dev/null and b/doc/ppocr_v4/ppocrv4_gtc.png differ
diff --git a/doc/ppocr_v4/v4_rec_pipeline.png b/doc/ppocr_v4/v4_rec_pipeline.png
new file mode 100644
index 0000000000000000000000000000000000000000..b1ec7a96892c6fa992c79531da4979164027b99c
Binary files /dev/null and b/doc/ppocr_v4/v4_rec_pipeline.png differ
diff --git a/paddleocr.py b/paddleocr.py
index af0145b48b7d8a8e6860cfb69e36b7a973a1149c..dc92cbf6b7c1789af629ba764ad1c0c12b936e4c 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -26,37 +26,133 @@ import cv2
import logging
import numpy as np
from pathlib import Path
+import base64
+from io import BytesIO
+from PIL import Image
-tools = importlib.import_module('.', 'tools')
-ppocr = importlib.import_module('.', 'ppocr')
-ppstructure = importlib.import_module('.', 'ppstructure')
-from tools.infer import predict_system
-from ppocr.utils.logging import get_logger
+def _import_file(module_name, file_path, make_importable=False):
+ spec = importlib.util.spec_from_file_location(module_name, file_path)
+ module = importlib.util.module_from_spec(spec)
+ spec.loader.exec_module(module)
+ if make_importable:
+ sys.modules[module_name] = module
+ return module
-logger = get_logger()
-from ppocr.utils.utility import check_and_read, get_image_file_list
+
+tools = _import_file(
+ 'tools', os.path.join(__dir__, 'tools/__init__.py'), make_importable=True)
+ppocr = importlib.import_module('ppocr', 'paddleocr')
+ppstructure = importlib.import_module('ppstructure', 'paddleocr')
+from ppocr.utils.logging import get_logger
+from tools.infer import predict_system
+from ppocr.utils.utility import check_and_read, get_image_file_list, alpha_to_color, binarize_img
from ppocr.utils.network import maybe_download, download_with_progressbar, is_link, confirm_model_dir_url
from tools.infer.utility import draw_ocr, str2bool, check_gpu
from ppstructure.utility import init_args, draw_structure_result
from ppstructure.predict_system import StructureSystem, save_structure_res, to_excel
+logger = get_logger()
__all__ = [
'PaddleOCR', 'PPStructure', 'draw_ocr', 'draw_structure_result',
'save_structure_res', 'download_with_progressbar', 'to_excel'
]
SUPPORT_DET_MODEL = ['DB']
-VERSION = '2.6.1.0'
+VERSION = '2.7.0.2'
SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
-DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
-SUPPORT_OCR_MODEL_VERSION = ['PP-OCR', 'PP-OCRv2', 'PP-OCRv3']
+DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv4'
+SUPPORT_OCR_MODEL_VERSION = ['PP-OCR', 'PP-OCRv2', 'PP-OCRv3', 'PP-OCRv4']
DEFAULT_STRUCTURE_MODEL_VERSION = 'PP-StructureV2'
SUPPORT_STRUCTURE_MODEL_VERSION = ['PP-Structure', 'PP-StructureV2']
MODEL_URLS = {
'OCR': {
+ 'PP-OCRv4': {
+ 'det': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar',
+ },
+ 'en': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar',
+ },
+ 'ml': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar'
+ }
+ },
+ 'rec': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/ppocr_keys_v1.txt'
+ },
+ 'en': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/english/en_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/en_dict.txt'
+ },
+ 'korean': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/korean_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/korean_dict.txt'
+ },
+ 'japan': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/japan_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/japan_dict.txt'
+ },
+ 'chinese_cht': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/chinese_cht_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/chinese_cht_dict.txt'
+ },
+ 'ta': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/ta_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/ta_dict.txt'
+ },
+ 'te': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/te_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/te_dict.txt'
+ },
+ 'ka': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/ka_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/ka_dict.txt'
+ },
+ 'latin': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/latin_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/latin_dict.txt'
+ },
+ 'arabic': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/arabic_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/arabic_dict.txt'
+ },
+ 'cyrillic': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/cyrillic_dict.txt'
+ },
+ 'devanagari': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/PP-OCRv4/multilingual/devanagari_PP-OCRv4_rec_infer.tar',
+ 'dict_path': './ppocr/utils/dict/devanagari_dict.txt'
+ },
+ },
+ 'cls': {
+ 'ch': {
+ 'url':
+ 'https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar',
+ }
+ },
+ },
'PP-OCRv3': {
'det': {
'ch': {
@@ -312,13 +408,14 @@ def parse_args(mMain=True):
parser.add_argument("--det", type=str2bool, default=True)
parser.add_argument("--rec", type=str2bool, default=True)
parser.add_argument("--type", type=str, default='ocr')
+ parser.add_argument("--savefile", type=str2bool, default=False)
parser.add_argument(
"--ocr_version",
type=str,
choices=SUPPORT_OCR_MODEL_VERSION,
- default='PP-OCRv3',
+ default='PP-OCRv4',
help='OCR Model version, the current model support list is as follows: '
- '1. PP-OCRv3 Support Chinese and English detection and recognition model, and direction classifier model'
+ '1. PP-OCRv4/v3 Support Chinese and English detection and recognition model, and direction classifier model'
'2. PP-OCRv2 Support Chinese detection and recognition model. '
'3. PP-OCR support Chinese detection, recognition and direction classifier and multilingual recognition model.'
)
@@ -416,7 +513,7 @@ def get_model_config(type, version, model_type, lang):
def img_decode(content: bytes):
np_arr = np.frombuffer(content, dtype=np.uint8)
- return cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
+ return cv2.imdecode(np_arr, cv2.IMREAD_UNCHANGED)
def check_img(img):
@@ -431,7 +528,25 @@ def check_img(img):
img, flag_gif, flag_pdf = check_and_read(image_file)
if not flag_gif and not flag_pdf:
with open(image_file, 'rb') as f:
- img = img_decode(f.read())
+ img_str = f.read()
+ img = img_decode(img_str)
+ if img is None:
+ try:
+ buf = BytesIO()
+ image = BytesIO(img_str)
+ im = Image.open(image)
+ rgb = im.convert('RGB')
+ rgb.save(buf, 'jpeg')
+ buf.seek(0)
+ image_bytes = buf.read()
+ data_base64 = str(base64.b64encode(image_bytes),
+ encoding="utf-8")
+ image_decode = base64.b64decode(data_base64)
+ img_array = np.frombuffer(image_decode, np.uint8)
+ img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
+ except:
+ logger.error("error in loading image:{}".format(image_file))
+ return None
if img is None:
logger.error("error in loading image:{}".format(image_file))
return None
@@ -476,7 +591,7 @@ class PaddleOCR(predict_system.TextSystem):
params.cls_model_dir, cls_url = confirm_model_dir_url(
params.cls_model_dir,
os.path.join(BASE_DIR, 'whl', 'cls'), cls_model_config['url'])
- if params.ocr_version == 'PP-OCRv3':
+ if params.ocr_version in ['PP-OCRv3', 'PP-OCRv4']:
params.rec_image_shape = "3, 48, 320"
else:
params.rec_image_shape = "3, 32, 320"
@@ -502,14 +617,17 @@ class PaddleOCR(predict_system.TextSystem):
super().__init__(params)
self.page_num = params.page_num
- def ocr(self, img, det=True, rec=True, cls=True):
+ def ocr(self, img, det=True, rec=True, cls=True, bin=False, inv=False, alpha_color=(255, 255, 255)):
"""
- ocr with paddleocr
- args:
- img: img for ocr, support ndarray, img_path and list or ndarray
- det: use text detection or not. If false, only rec will be exec. Default is True
- rec: use text recognition or not. If false, only det will be exec. Default is True
- cls: use angle classifier or not. Default is True. If true, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
+ OCR with PaddleOCR
+ args:
+ img: img for OCR, support ndarray, img_path and list or ndarray
+ det: use text detection or not. If False, only rec will be exec. Default is True
+ rec: use text recognition or not. If False, only det will be exec. Default is True
+ cls: use angle classifier or not. Default is True. If True, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
+ bin: binarize image to black and white. Default is False.
+ inv: invert image colors. Default is False.
+ alpha_color: set RGB color Tuple for transparent parts replacement. Default is pure white.
"""
assert isinstance(img, (np.ndarray, list, str, bytes))
if isinstance(img, list) and det == True:
@@ -517,7 +635,7 @@ class PaddleOCR(predict_system.TextSystem):
exit(0)
if cls == True and self.use_angle_cls == False:
logger.warning(
- 'Since the angle classifier is not initialized, the angle classifier will not be uesd during the forward process'
+ 'Since the angle classifier is not initialized, it will not be used during the forward process'
)
img = check_img(img)
@@ -528,10 +646,23 @@ class PaddleOCR(predict_system.TextSystem):
imgs = img[:self.page_num]
else:
imgs = [img]
+
+ def preprocess_image(_image):
+ _image = alpha_to_color(_image, alpha_color)
+ if inv:
+ _image = cv2.bitwise_not(_image)
+ if bin:
+ _image = binarize_img(_image)
+ return _image
+
if det and rec:
ocr_res = []
for idx, img in enumerate(imgs):
+ img = preprocess_image(img)
dt_boxes, rec_res, _ = self.__call__(img, cls)
+ if not dt_boxes and not rec_res:
+ ocr_res.append(None)
+ continue
tmp_res = [[box.tolist(), res]
for box, res in zip(dt_boxes, rec_res)]
ocr_res.append(tmp_res)
@@ -539,7 +670,11 @@ class PaddleOCR(predict_system.TextSystem):
elif det and not rec:
ocr_res = []
for idx, img in enumerate(imgs):
+ img = preprocess_image(img)
dt_boxes, elapse = self.text_detector(img)
+ if not dt_boxes:
+ ocr_res.append(None)
+ continue
tmp_res = [box.tolist() for box in dt_boxes]
ocr_res.append(tmp_res)
return ocr_res
@@ -548,6 +683,7 @@ class PaddleOCR(predict_system.TextSystem):
cls_res = []
for idx, img in enumerate(imgs):
if not isinstance(img, list):
+ img = preprocess_image(img)
img = [img]
if self.use_angle_cls and cls:
img, cls_res_tmp, elapse = self.text_classifier(img)
@@ -649,15 +785,35 @@ def main():
img_name = os.path.basename(img_path).split('.')[0]
logger.info('{}{}{}'.format('*' * 10, img_path, '*' * 10))
if args.type == 'ocr':
- result = engine.ocr(img_path,
- det=args.det,
- rec=args.rec,
- cls=args.use_angle_cls)
+ result = engine.ocr(
+ img_path,
+ det=args.det,
+ rec=args.rec,
+ cls=args.use_angle_cls,
+ bin=args.binarize,
+ inv=args.invert,
+ alpha_color=args.alphacolor
+ )
if result is not None:
+ lines = []
for idx in range(len(result)):
res = result[idx]
for line in res:
logger.info(line)
+ val = '['
+ for box in line[0]:
+ val += str(box[0]) + ',' + str(box[1]) + ','
+
+ val = val[:-1]
+ val += '],' + line[1][0] + ',' + str(line[1][1]) + '\n'
+ lines.append(val)
+ if args.savefile:
+ if os.path.exists(args.output) is False:
+ os.mkdir(args.output)
+ outfile = args.output + '/' + img_name + '.txt'
+ with open(outfile,'w',encoding='utf-8') as f:
+ f.writelines(lines)
+
elif args.type == 'structure':
img, flag_gif, flag_pdf = check_and_read(img_path)
if not flag_gif and not flag_pdf:
@@ -694,7 +850,7 @@ def main():
logger.info('processing {}/{} page:'.format(index + 1,
len(img_paths)))
new_img_name = os.path.basename(new_img_path).split('.')[0]
- result = engine(new_img_path, img_idx=index)
+ result = engine(img, img_idx=index)
save_structure_res(result, args.output, img_name, index)
if args.recovery and result != []:
diff --git a/ppocr/data/__init__.py b/ppocr/data/__init__.py
index b602a346dbe4b0d45af287f25f05ead0f62daf44..48cd8ad8c5ccef9b0dd3c9a0c66eb028a70c8334 100644
--- a/ppocr/data/__init__.py
+++ b/ppocr/data/__init__.py
@@ -33,12 +33,22 @@ from paddle.io import Dataset, DataLoader, BatchSampler, DistributedBatchSampler
import paddle.distributed as dist
from ppocr.data.imaug import transform, create_operators
-from ppocr.data.simple_dataset import SimpleDataSet
-from ppocr.data.lmdb_dataset import LMDBDataSet, LMDBDataSetSR
+from ppocr.data.simple_dataset import SimpleDataSet, MultiScaleDataSet
+from ppocr.data.lmdb_dataset import LMDBDataSet, LMDBDataSetSR, LMDBDataSetTableMaster
from ppocr.data.pgnet_dataset import PGDataSet
from ppocr.data.pubtab_dataset import PubTabDataSet
+from ppocr.data.multi_scale_sampler import MultiScaleSampler
-__all__ = ['build_dataloader', 'transform', 'create_operators']
+# for PaddleX dataset_type
+TextDetDataset = SimpleDataSet
+TextRecDataset = SimpleDataSet
+MSTextRecDataset = MultiScaleDataSet
+PubTabTableRecDataset = PubTabDataSet
+KieDataset = SimpleDataSet
+
+__all__ = [
+ 'build_dataloader', 'transform', 'create_operators', 'set_signal_handlers'
+]
def term_mp(sig_num, frame):
@@ -50,12 +60,43 @@ def term_mp(sig_num, frame):
os.killpg(pgid, signal.SIGKILL)
+def set_signal_handlers():
+ pid = os.getpid()
+ try:
+ pgid = os.getpgid(pid)
+ except AttributeError:
+ # In case `os.getpgid` is not available, no signal handler will be set,
+ # because we cannot do safe cleanup.
+ pass
+ else:
+ # XXX: `term_mp` kills all processes in the process group, which in
+ # some cases includes the parent process of current process and may
+ # cause unexpected results. To solve this problem, we set signal
+ # handlers only when current process is the group leader. In the
+ # future, it would be better to consider killing only descendants of
+ # the current process.
+ if pid == pgid:
+ # support exit using ctrl+c
+ signal.signal(signal.SIGINT, term_mp)
+ signal.signal(signal.SIGTERM, term_mp)
+
+
def build_dataloader(config, mode, device, logger, seed=None):
config = copy.deepcopy(config)
support_dict = [
- 'SimpleDataSet', 'LMDBDataSet', 'PGDataSet', 'PubTabDataSet',
- 'LMDBDataSetSR'
+ 'SimpleDataSet',
+ 'LMDBDataSet',
+ 'PGDataSet',
+ 'PubTabDataSet',
+ 'LMDBDataSetSR',
+ 'LMDBDataSetTableMaster',
+ 'MultiScaleDataSet',
+ 'TextDetDataset',
+ 'TextRecDataset',
+ 'MSTextRecDataset',
+ 'PubTabTableRecDataset',
+ 'KieDataset',
]
module_name = config[mode]['dataset']['name']
assert module_name in support_dict, Exception(
@@ -76,11 +117,16 @@ def build_dataloader(config, mode, device, logger, seed=None):
if mode == "Train":
# Distribute data to multiple cards
- batch_sampler = DistributedBatchSampler(
- dataset=dataset,
- batch_size=batch_size,
- shuffle=shuffle,
- drop_last=drop_last)
+ if 'sampler' in config[mode]:
+ config_sampler = config[mode]['sampler']
+ sampler_name = config_sampler.pop("name")
+ batch_sampler = eval(sampler_name)(dataset, **config_sampler)
+ else:
+ batch_sampler = DistributedBatchSampler(
+ dataset=dataset,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ drop_last=drop_last)
else:
# Distribute data to single card
batch_sampler = BatchSampler(
@@ -103,8 +149,4 @@ def build_dataloader(config, mode, device, logger, seed=None):
use_shared_memory=use_shared_memory,
collate_fn=collate_fn)
- # support exit using ctrl+c
- signal.signal(signal.SIGINT, term_mp)
- signal.signal(signal.SIGTERM, term_mp)
-
return data_loader
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 93d97446d44070b9c10064fbe10b0b5e05628a6a..121582b4908750fca6612dc592a3671ef4dcb328 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -27,7 +27,7 @@ from .make_pse_gt import MakePseGt
from .rec_img_aug import BaseDataAugmentation, RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
SRNRecResizeImg, GrayRecResizeImg, SARRecResizeImg, PRENResizeImg, \
ABINetRecResizeImg, SVTRRecResizeImg, ABINetRecAug, VLRecResizeImg, SPINRecResizeImg, RobustScannerRecResizeImg, \
- RFLRecResizeImg
+ RFLRecResizeImg, SVTRRecAug
from .ssl_img_aug import SSLRotateResize
from .randaugment import RandAugment
from .copy_paste import CopyPaste
diff --git a/ppocr/data/imaug/abinet_aug.py b/ppocr/data/imaug/abinet_aug.py
index eefdc75d5a5c0ac3f7136bf22a2adb31129bd313..bcbdadb1bae06d0a58de4743df9ce0d8c15fcfa1 100644
--- a/ppocr/data/imaug/abinet_aug.py
+++ b/ppocr/data/imaug/abinet_aug.py
@@ -205,7 +205,7 @@ class CVRandomAffine(object):
for x, y in startpoints]
rect = cv2.minAreaRect(np.array(endpoints))
- bbox = cv2.boxPoints(rect).astype(dtype=np.int)
+ bbox = cv2.boxPoints(rect).astype(dtype=np.int32)
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
@@ -234,9 +234,9 @@ class CVRandomPerspective(object):
def get_params(self, width, height, distortion):
offset_h = sample_asym(
- distortion * height / 2, size=4).astype(dtype=np.int)
+ distortion * height / 2, size=4).astype(dtype=np.int32)
offset_w = sample_asym(
- distortion * width / 2, size=4).astype(dtype=np.int)
+ distortion * width / 2, size=4).astype(dtype=np.int32)
topleft = (offset_w[0], offset_h[0])
topright = (width - 1 - offset_w[1], offset_h[1])
botright = (width - 1 - offset_w[2], height - 1 - offset_h[2])
@@ -256,7 +256,7 @@ class CVRandomPerspective(object):
# TODO: more robust way to crop image
rect = cv2.minAreaRect(endpoints)
- bbox = cv2.boxPoints(rect).astype(dtype=np.int)
+ bbox = cv2.boxPoints(rect).astype(dtype=np.int32)
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
min_x, min_y = max(min_x, 0), max(min_y, 0)
@@ -405,3 +405,55 @@ class CVColorJitter(object):
def __call__(self, img):
if random.random() < self.p: return self.transforms(img)
else: return img
+
+
+class SVTRDeterioration(object):
+ def __init__(self, var, degrees, factor, p=0.5):
+ self.p = p
+ transforms = []
+ if var is not None:
+ transforms.append(CVGaussianNoise(var=var))
+ if degrees is not None:
+ transforms.append(CVMotionBlur(degrees=degrees))
+ if factor is not None:
+ transforms.append(CVRescale(factor=factor))
+ self.transforms = transforms
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ random.shuffle(self.transforms)
+ transforms = Compose(self.transforms)
+ return transforms(img)
+ else:
+ return img
+
+
+class SVTRGeometry(object):
+ def __init__(self,
+ aug_type=0,
+ degrees=15,
+ translate=(0.3, 0.3),
+ scale=(0.5, 2.),
+ shear=(45, 15),
+ distortion=0.5,
+ p=0.5):
+ self.aug_type = aug_type
+ self.p = p
+ self.transforms = []
+ self.transforms.append(CVRandomRotation(degrees=degrees))
+ self.transforms.append(
+ CVRandomAffine(
+ degrees=degrees, translate=translate, scale=scale, shear=shear))
+ self.transforms.append(CVRandomPerspective(distortion=distortion))
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ if self.aug_type:
+ random.shuffle(self.transforms)
+ transforms = Compose(self.transforms[:random.randint(1, 3)])
+ img = transforms(img)
+ else:
+ img = self.transforms[random.randint(0, 2)](img)
+ return img
+ else:
+ return img
diff --git a/ppocr/data/imaug/ct_process.py b/ppocr/data/imaug/ct_process.py
index 59715090036e1020800950b02b9ea06ab5c8d4c2..933d42f98c068780c2140740eddbc553cec02ee6 100644
--- a/ppocr/data/imaug/ct_process.py
+++ b/ppocr/data/imaug/ct_process.py
@@ -19,7 +19,8 @@ import pyclipper
import paddle
import numpy as np
-import Polygon as plg
+from ppocr.utils.utility import check_install
+
import scipy.io as scio
from PIL import Image
@@ -70,6 +71,8 @@ class MakeShrink():
return peri
def shrink(self, bboxes, rate, max_shr=20):
+ check_install('Polygon', 'Polygon3')
+ import Polygon as plg
rate = rate * rate
shrinked_bboxes = []
for bbox in bboxes:
diff --git a/ppocr/data/imaug/drrg_targets.py b/ppocr/data/imaug/drrg_targets.py
index c56e878b837328ef2efde40b96b5571dffbb4791..7fdfd096819b266290353d842ef531e8220c586c 100644
--- a/ppocr/data/imaug/drrg_targets.py
+++ b/ppocr/data/imaug/drrg_targets.py
@@ -18,7 +18,7 @@ https://github.com/open-mmlab/mmocr/blob/main/mmocr/datasets/pipelines/textdet_t
import cv2
import numpy as np
-from lanms import merge_quadrangle_n9 as la_nms
+from ppocr.utils.utility import check_install
from numpy.linalg import norm
@@ -543,6 +543,8 @@ class DRRGTargets(object):
score = np.ones((text_comps.shape[0], 1), dtype=np.float32)
text_comps = np.hstack([text_comps, score])
+ check_install('lanms', 'lanms-neo')
+ from lanms import merge_quadrangle_n9 as la_nms
text_comps = la_nms(text_comps, self.text_comp_nms_thr)
if text_comps.shape[0] >= 1:
diff --git a/ppocr/data/imaug/fce_aug.py b/ppocr/data/imaug/fce_aug.py
index 66bafef13caaaa958c89f865bde04cb25f031329..baaaa3355558bb6919f6b0b3b58016680f15f31c 100644
--- a/ppocr/data/imaug/fce_aug.py
+++ b/ppocr/data/imaug/fce_aug.py
@@ -208,7 +208,7 @@ class RandomCropFlip:
for polygon in all_polys:
rect = cv2.minAreaRect(polygon.astype(np.int32).reshape(-1, 2))
box = cv2.boxPoints(rect)
- box = np.int0(box)
+ box = np.int64(box)
text_polys.append([box[0], box[1], box[2], box[3]])
polys = np.array(text_polys, dtype=np.int32)
diff --git a/ppocr/data/imaug/fce_targets.py b/ppocr/data/imaug/fce_targets.py
index 8c64276e26665d2779d35154bf9cd77edddad580..054631cb2ddee4e4fd4d5532538f318379568ded 100644
--- a/ppocr/data/imaug/fce_targets.py
+++ b/ppocr/data/imaug/fce_targets.py
@@ -22,10 +22,12 @@ from numpy.fft import fft
from numpy.linalg import norm
import sys
+
def vector_slope(vec):
assert len(vec) == 2
return abs(vec[1] / (vec[0] + 1e-8))
+
class FCENetTargets:
"""Generate the ground truth targets of FCENet: Fourier Contour Embedding
for Arbitrary-Shaped Text Detection.
@@ -107,7 +109,9 @@ class FCENetTargets:
for i in range(1, n):
current_line_len = i * delta_length
- while current_edge_ind + 1 < len(length_cumsum) and current_line_len >= length_cumsum[current_edge_ind + 1]:
+ while current_edge_ind + 1 < len(
+ length_cumsum) and current_line_len >= length_cumsum[
+ current_edge_ind + 1]:
current_edge_ind += 1
current_edge_end_shift = current_line_len - length_cumsum[
@@ -239,10 +243,9 @@ class FCENetTargets:
head_inds = [head_start, head_end]
tail_inds = [tail_start, tail_end]
else:
- if vector_slope(points[1] - points[0]) + vector_slope(
- points[3] - points[2]) < vector_slope(points[
- 2] - points[1]) + vector_slope(points[0] - points[
- 3]):
+ if vector_slope(points[1] - points[0]) + vector_slope(points[
+ 3] - points[2]) < vector_slope(points[2] - points[
+ 1]) + vector_slope(points[0] - points[3]):
horizontal_edge_inds = [[0, 1], [2, 3]]
vertical_edge_inds = [[3, 0], [1, 2]]
else:
@@ -582,7 +585,7 @@ class FCENetTargets:
lv_ignore_polys = [[] for i in range(len(lv_size_divs))]
level_maps = []
for poly in text_polys:
- polygon = np.array(poly, dtype=np.int).reshape((1, -1, 2))
+ polygon = np.array(poly, dtype=np.int32).reshape((1, -1, 2))
_, _, box_w, box_h = cv2.boundingRect(polygon)
proportion = max(box_h, box_w) / (h + 1e-8)
@@ -591,7 +594,7 @@ class FCENetTargets:
lv_text_polys[ind].append(poly / lv_size_divs[ind])
for ignore_poly in ignore_polys:
- polygon = np.array(ignore_poly, dtype=np.int).reshape((1, -1, 2))
+ polygon = np.array(ignore_poly, dtype=np.int32).reshape((1, -1, 2))
_, _, box_w, box_h = cv2.boundingRect(polygon)
proportion = max(box_h, box_w) / (h + 1e-8)
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 63c5d6aa7851422e21a567dfe938c417793ca7ea..148b09368717a09fcc20e0852c69a948311cb511 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -64,7 +64,7 @@ class DetLabelEncode(object):
return None
boxes = self.expand_points_num(boxes)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['texts'] = txts
@@ -218,7 +218,7 @@ class E2ELabelEncodeTest(BaseRecLabelEncode):
else:
txt_tags.append(False)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['ignore_tags'] = txt_tags
temp_texts = []
@@ -254,7 +254,7 @@ class E2ELabelEncodeTrain(object):
else:
txt_tags.append(False)
boxes = np.array(boxes, dtype=np.float32)
- txt_tags = np.array(txt_tags, dtype=np.bool)
+ txt_tags = np.array(txt_tags, dtype=np.bool_)
data['polys'] = boxes
data['texts'] = txts
@@ -886,6 +886,62 @@ class SARLabelEncode(BaseRecLabelEncode):
return [self.padding_idx]
+class SATRNLabelEncode(BaseRecLabelEncode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ lower=False,
+ **kwargs):
+ super(SATRNLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+ self.lower = lower
+
+ def add_special_char(self, dict_character):
+ beg_end_str = ""
+ unknown_str = ""
+ padding_str = ""
+ dict_character = dict_character + [unknown_str]
+ self.unknown_idx = len(dict_character) - 1
+ dict_character = dict_character + [beg_end_str]
+ self.start_idx = len(dict_character) - 1
+ self.end_idx = len(dict_character) - 1
+ dict_character = dict_character + [padding_str]
+ self.padding_idx = len(dict_character) - 1
+
+ return dict_character
+
+ def encode(self, text):
+ if self.lower:
+ text = text.lower()
+ text_list = []
+ for char in text:
+ text_list.append(self.dict.get(char, self.unknown_idx))
+ if len(text_list) == 0:
+ return None
+ return text_list
+
+ def __call__(self, data):
+ text = data['label']
+ text = self.encode(text)
+ if text is None:
+ return None
+ data['length'] = np.array(len(text))
+ target = [self.start_idx] + text + [self.end_idx]
+ padded_text = [self.padding_idx for _ in range(self.max_text_len)]
+ if len(target) > self.max_text_len:
+ padded_text = target[:self.max_text_len]
+ else:
+ padded_text[:len(target)] = target
+ data['label'] = np.array(padded_text)
+ return data
+
+ def get_ignored_tokens(self):
+ return [self.padding_idx]
+
+
class PRENLabelEncode(BaseRecLabelEncode):
def __init__(self,
max_text_length,
@@ -1185,27 +1241,36 @@ class MultiLabelEncode(BaseRecLabelEncode):
max_text_length,
character_dict_path=None,
use_space_char=False,
+ gtc_encode=None,
**kwargs):
super(MultiLabelEncode, self).__init__(
max_text_length, character_dict_path, use_space_char)
self.ctc_encode = CTCLabelEncode(max_text_length, character_dict_path,
use_space_char, **kwargs)
- self.sar_encode = SARLabelEncode(max_text_length, character_dict_path,
- use_space_char, **kwargs)
+ self.gtc_encode_type = gtc_encode
+ if gtc_encode is None:
+ self.gtc_encode = SARLabelEncode(
+ max_text_length, character_dict_path, use_space_char, **kwargs)
+ else:
+ self.gtc_encode = eval(gtc_encode)(
+ max_text_length, character_dict_path, use_space_char, **kwargs)
def __call__(self, data):
data_ctc = copy.deepcopy(data)
- data_sar = copy.deepcopy(data)
+ data_gtc = copy.deepcopy(data)
data_out = dict()
data_out['img_path'] = data.get('img_path', None)
data_out['image'] = data['image']
ctc = self.ctc_encode.__call__(data_ctc)
- sar = self.sar_encode.__call__(data_sar)
- if ctc is None or sar is None:
+ gtc = self.gtc_encode.__call__(data_gtc)
+ if ctc is None or gtc is None:
return None
data_out['label_ctc'] = ctc['label']
- data_out['label_sar'] = sar['label']
+ if self.gtc_encode_type is not None:
+ data_out['label_gtc'] = gtc['label']
+ else:
+ data_out['label_sar'] = gtc['label']
data_out['length'] = ctc['length']
return data_out
@@ -1396,10 +1461,9 @@ class VLLabelEncode(BaseRecLabelEncode):
max_text_length,
character_dict_path=None,
use_space_char=False,
- lower=True,
**kwargs):
- super(VLLabelEncode, self).__init__(
- max_text_length, character_dict_path, use_space_char, lower)
+ super(VLLabelEncode, self).__init__(max_text_length,
+ character_dict_path, use_space_char)
self.dict = {}
for i, char in enumerate(self.character):
self.dict[char] = i
diff --git a/ppocr/data/imaug/make_border_map.py b/ppocr/data/imaug/make_border_map.py
index abab38368db2de84e54b060598fc509a65219296..03b7817cfbe2068184981b18a7aa539c8d350e3b 100644
--- a/ppocr/data/imaug/make_border_map.py
+++ b/ppocr/data/imaug/make_border_map.py
@@ -44,6 +44,10 @@ class MakeBorderMap(object):
self.shrink_ratio = shrink_ratio
self.thresh_min = thresh_min
self.thresh_max = thresh_max
+ if 'total_epoch' in kwargs and 'epoch' in kwargs and kwargs[
+ 'epoch'] != "None":
+ self.shrink_ratio = self.shrink_ratio + 0.2 * kwargs[
+ 'epoch'] / float(kwargs['total_epoch'])
def __call__(self, data):
diff --git a/ppocr/data/imaug/make_shrink_map.py b/ppocr/data/imaug/make_shrink_map.py
index 6c65c20e5621f91a5b1fba549b059c92923fca6f..d0317b61fe05ce75c479a2485cef540742f489e0 100644
--- a/ppocr/data/imaug/make_shrink_map.py
+++ b/ppocr/data/imaug/make_shrink_map.py
@@ -38,6 +38,10 @@ class MakeShrinkMap(object):
def __init__(self, min_text_size=8, shrink_ratio=0.4, **kwargs):
self.min_text_size = min_text_size
self.shrink_ratio = shrink_ratio
+ if 'total_epoch' in kwargs and 'epoch' in kwargs and kwargs[
+ 'epoch'] != "None":
+ self.shrink_ratio = self.shrink_ratio + 0.2 * kwargs[
+ 'epoch'] / float(kwargs['total_epoch'])
def __call__(self, data):
image = data['image']
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index e22153bdeab06565feed79715633172a275aecc7..9780082f1cc3629c7b05a24747537d473d2a42a4 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -18,8 +18,9 @@ import numpy as np
import random
import copy
from PIL import Image
+import PIL
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
-from .abinet_aug import CVGeometry, CVDeterioration, CVColorJitter
+from .abinet_aug import CVGeometry, CVDeterioration, CVColorJitter, SVTRGeometry, SVTRDeterioration
from paddle.vision.transforms import Compose
@@ -69,6 +70,8 @@ class BaseDataAugmentation(object):
self.jitter_prob = jitter_prob
self.blur_prob = blur_prob
self.hsv_aug_prob = hsv_aug_prob
+ # for GaussianBlur
+ self.fil = cv2.getGaussianKernel(ksize=5, sigma=1, ktype=cv2.CV_32F)
def __call__(self, data):
img = data['image']
@@ -78,7 +81,8 @@ class BaseDataAugmentation(object):
img = get_crop(img)
if random.random() <= self.blur_prob:
- img = blur(img)
+ # GaussianBlur
+ img = cv2.sepFilter2D(img, -1, self.fil, self.fil)
if random.random() <= self.hsv_aug_prob:
img = hsv_aug(img)
@@ -169,6 +173,38 @@ class RecConAug(object):
return data
+class SVTRRecAug(object):
+ def __init__(self,
+ aug_type=0,
+ geometry_p=0.5,
+ deterioration_p=0.25,
+ colorjitter_p=0.25,
+ **kwargs):
+ self.transforms = Compose([
+ SVTRGeometry(
+ aug_type=aug_type,
+ degrees=45,
+ translate=(0.0, 0.0),
+ scale=(0.5, 2.),
+ shear=(45, 15),
+ distortion=0.5,
+ p=geometry_p), SVTRDeterioration(
+ var=20, degrees=6, factor=4, p=deterioration_p),
+ CVColorJitter(
+ brightness=0.5,
+ contrast=0.5,
+ saturation=0.5,
+ hue=0.1,
+ p=colorjitter_p)
+ ])
+
+ def __call__(self, data):
+ img = data['image']
+ img = self.transforms(img)
+ data['image'] = img
+ return data
+
+
class ClsResizeImg(object):
def __init__(self, image_shape, **kwargs):
self.image_shape = image_shape
@@ -184,17 +220,20 @@ class RecResizeImg(object):
def __init__(self,
image_shape,
infer_mode=False,
+ eval_mode=False,
character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
padding=True,
**kwargs):
self.image_shape = image_shape
self.infer_mode = infer_mode
+ self.eval_mode = eval_mode
self.character_dict_path = character_dict_path
self.padding = padding
def __call__(self, data):
img = data['image']
- if self.infer_mode and self.character_dict_path is not None:
+ if self.eval_mode or (self.infer_mode and
+ self.character_dict_path is not None):
norm_img, valid_ratio = resize_norm_img_chinese(img,
self.image_shape)
else:
@@ -368,7 +407,7 @@ class GrayRecResizeImg(object):
def __init__(self,
image_shape,
resize_type,
- inter_type='Image.ANTIALIAS',
+ inter_type="Image.Resampling.LANCZOS",
scale=True,
padding=False,
**kwargs):
@@ -538,7 +577,7 @@ def resize_norm_img_chinese(img, image_shape):
max_wh_ratio = imgW * 1.0 / imgH
h, w = img.shape[0], img.shape[1]
ratio = w * 1.0 / h
- max_wh_ratio = min(max(max_wh_ratio, ratio), max_wh_ratio)
+ max_wh_ratio = max(max_wh_ratio, ratio)
imgW = int(imgH * max_wh_ratio)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
diff --git a/ppocr/data/lmdb_dataset.py b/ppocr/data/lmdb_dataset.py
index 295643e401481d30cf433346727f39d4a4c7d2f4..f3efb604285a2dbc0062f80c95ad1ee8a9b3a127 100644
--- a/ppocr/data/lmdb_dataset.py
+++ b/ppocr/data/lmdb_dataset.py
@@ -18,6 +18,7 @@ import lmdb
import cv2
import string
import six
+import pickle
from PIL import Image
from .imaug import transform, create_operators
@@ -203,3 +204,87 @@ class LMDBDataSetSR(LMDBDataSet):
if outs is None:
return self.__getitem__(np.random.randint(self.__len__()))
return outs
+
+
+class LMDBDataSetTableMaster(LMDBDataSet):
+ def load_hierarchical_lmdb_dataset(self, data_dir):
+ lmdb_sets = {}
+ dataset_idx = 0
+ env = lmdb.open(
+ data_dir,
+ max_readers=32,
+ readonly=True,
+ lock=False,
+ readahead=False,
+ meminit=False)
+ txn = env.begin(write=False)
+ num_samples = int(pickle.loads(txn.get(b"__len__")))
+ lmdb_sets[dataset_idx] = {"dirpath":data_dir, "env":env, \
+ "txn":txn, "num_samples":num_samples}
+ return lmdb_sets
+
+ def get_img_data(self, value):
+ """get_img_data"""
+ if not value:
+ return None
+ imgdata = np.frombuffer(value, dtype='uint8')
+ if imgdata is None:
+ return None
+ imgori = cv2.imdecode(imgdata, 1)
+ if imgori is None:
+ return None
+ return imgori
+
+ def get_lmdb_sample_info(self, txn, index):
+ def convert_bbox(bbox_str_list):
+ bbox_list = []
+ for bbox_str in bbox_str_list:
+ bbox_list.append(int(bbox_str))
+ return bbox_list
+
+ try:
+ data = pickle.loads(txn.get(str(index).encode('utf8')))
+ except:
+ return None
+
+ # img_name, img, info_lines
+ file_name = data[0]
+ bytes = data[1]
+ info_lines = data[2] # raw data from TableMASTER annotation file.
+ # parse info_lines
+ raw_data = info_lines.strip().split('\n')
+ raw_name, text = raw_data[0], raw_data[
+ 1] # don't filter the samples's length over max_seq_len.
+ text = text.split(',')
+ bbox_str_list = raw_data[2:]
+ bbox_split = ','
+ bboxes = [{
+ 'bbox': convert_bbox(bsl.strip().split(bbox_split)),
+ 'tokens': ['1', '2']
+ } for bsl in bbox_str_list]
+
+ # advance parse bbox
+ # import pdb;pdb.set_trace()
+
+ line_info = {}
+ line_info['file_name'] = file_name
+ line_info['structure'] = text
+ line_info['cells'] = bboxes
+ line_info['image'] = bytes
+ return line_info
+
+ def __getitem__(self, idx):
+ lmdb_idx, file_idx = self.data_idx_order_list[idx]
+ lmdb_idx = int(lmdb_idx)
+ file_idx = int(file_idx)
+ data = self.get_lmdb_sample_info(self.lmdb_sets[lmdb_idx]['txn'],
+ file_idx)
+ if data is None:
+ return self.__getitem__(np.random.randint(self.__len__()))
+ outs = transform(data, self.ops)
+ if outs is None:
+ return self.__getitem__(np.random.randint(self.__len__()))
+ return outs
+
+ def __len__(self):
+ return self.data_idx_order_list.shape[0]
diff --git a/ppocr/data/multi_scale_sampler.py b/ppocr/data/multi_scale_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..45793e2ba1f5c5a4f4388dd22e7146725854fa76
--- /dev/null
+++ b/ppocr/data/multi_scale_sampler.py
@@ -0,0 +1,171 @@
+from paddle.io import Sampler
+import paddle.distributed as dist
+
+import numpy as np
+import random
+import math
+
+
+class MultiScaleSampler(Sampler):
+ def __init__(self,
+ data_source,
+ scales,
+ first_bs=128,
+ fix_bs=True,
+ divided_factor=[8, 16],
+ is_training=True,
+ ratio_wh=0.8,
+ max_w=480.,
+ seed=None):
+ """
+ multi scale samper
+ Args:
+ data_source(dataset)
+ scales(list): several scales for image resolution
+ first_bs(int): batch size for the first scale in scales
+ divided_factor(list[w, h]): ImageNet models down-sample images by a factor, ensure that width and height dimensions are multiples are multiple of devided_factor.
+ is_training(boolean): mode
+ """
+ # min. and max. spatial dimensions
+ self.data_source = data_source
+ self.data_idx_order_list = np.array(data_source.data_idx_order_list)
+ self.ds_width = data_source.ds_width
+ self.seed = data_source.seed
+ if self.ds_width:
+ self.wh_ratio = data_source.wh_ratio
+ self.wh_ratio_sort = data_source.wh_ratio_sort
+ self.n_data_samples = len(self.data_source)
+ self.ratio_wh = ratio_wh
+ self.max_w = max_w
+
+ if isinstance(scales[0], list):
+ width_dims = [i[0] for i in scales]
+ height_dims = [i[1] for i in scales]
+ elif isinstance(scales[0], int):
+ width_dims = scales
+ height_dims = scales
+ base_im_w = width_dims[0]
+ base_im_h = height_dims[0]
+ base_batch_size = first_bs
+
+ # Get the GPU and node related information
+ num_replicas = dist.get_world_size()
+ rank = dist.get_rank()
+ # adjust the total samples to avoid batch dropping
+ num_samples_per_replica = int(self.n_data_samples * 1.0 / num_replicas)
+
+ img_indices = [idx for idx in range(self.n_data_samples)]
+
+ self.shuffle = False
+ if is_training:
+ # compute the spatial dimensions and corresponding batch size
+ # ImageNet models down-sample images by a factor of 32.
+ # Ensure that width and height dimensions are multiples are multiple of 32.
+ width_dims = [
+ int((w // divided_factor[0]) * divided_factor[0])
+ for w in width_dims
+ ]
+ height_dims = [
+ int((h // divided_factor[1]) * divided_factor[1])
+ for h in height_dims
+ ]
+
+ img_batch_pairs = list()
+ base_elements = base_im_w * base_im_h * base_batch_size
+ for (h, w) in zip(height_dims, width_dims):
+ if fix_bs:
+ batch_size = base_batch_size
+ else:
+ batch_size = int(max(1, (base_elements / (h * w))))
+ img_batch_pairs.append((w, h, batch_size))
+ self.img_batch_pairs = img_batch_pairs
+ self.shuffle = True
+ else:
+ self.img_batch_pairs = [(base_im_w, base_im_h, base_batch_size)]
+
+ self.img_indices = img_indices
+ self.n_samples_per_replica = num_samples_per_replica
+ self.epoch = 0
+ self.rank = rank
+ self.num_replicas = num_replicas
+
+ self.batch_list = []
+ self.current = 0
+ last_index = num_samples_per_replica * num_replicas
+ indices_rank_i = self.img_indices[self.rank:last_index:
+ self.num_replicas]
+ while self.current < self.n_samples_per_replica:
+ for curr_w, curr_h, curr_bsz in self.img_batch_pairs:
+ end_index = min(self.current + curr_bsz,
+ self.n_samples_per_replica)
+ batch_ids = indices_rank_i[self.current:end_index]
+ n_batch_samples = len(batch_ids)
+ if n_batch_samples != curr_bsz:
+ batch_ids += indices_rank_i[:(curr_bsz - n_batch_samples)]
+ self.current += curr_bsz
+
+ if len(batch_ids) > 0:
+ batch = [curr_w, curr_h, len(batch_ids)]
+ self.batch_list.append(batch)
+ random.shuffle(self.batch_list)
+ self.length = len(self.batch_list)
+ self.batchs_in_one_epoch = self.iter()
+ self.batchs_in_one_epoch_id = [
+ i for i in range(len(self.batchs_in_one_epoch))
+ ]
+
+ def __iter__(self):
+ if self.seed is None:
+ random.seed(self.epoch)
+ self.epoch += 1
+ else:
+ random.seed(self.seed)
+ random.shuffle(self.batchs_in_one_epoch_id)
+ for batch_tuple_id in self.batchs_in_one_epoch_id:
+ yield self.batchs_in_one_epoch[batch_tuple_id]
+
+ def iter(self):
+ if self.shuffle:
+ if self.seed is not None:
+ random.seed(self.seed)
+ else:
+ random.seed(self.epoch)
+ if not self.ds_width:
+ random.shuffle(self.img_indices)
+ random.shuffle(self.img_batch_pairs)
+ indices_rank_i = self.img_indices[self.rank:len(self.img_indices):
+ self.num_replicas]
+ else:
+ indices_rank_i = self.img_indices[self.rank:len(self.img_indices):
+ self.num_replicas]
+
+ start_index = 0
+ batchs_in_one_epoch = []
+ for batch_tuple in self.batch_list:
+ curr_w, curr_h, curr_bsz = batch_tuple
+ end_index = min(start_index + curr_bsz, self.n_samples_per_replica)
+ batch_ids = indices_rank_i[start_index:end_index]
+ n_batch_samples = len(batch_ids)
+ if n_batch_samples != curr_bsz:
+ batch_ids += indices_rank_i[:(curr_bsz - n_batch_samples)]
+ start_index += curr_bsz
+
+ if len(batch_ids) > 0:
+ if self.ds_width:
+ wh_ratio_current = self.wh_ratio[self.wh_ratio_sort[
+ batch_ids]]
+ ratio_current = wh_ratio_current.mean()
+ ratio_current = ratio_current if ratio_current * curr_h < self.max_w else self.max_w / curr_h
+ else:
+ ratio_current = None
+ batch = [(curr_w, curr_h, b_id, ratio_current)
+ for b_id in batch_ids]
+ # yield batch
+ batchs_in_one_epoch.append(batch)
+ return batchs_in_one_epoch
+
+ def set_epoch(self, epoch: int):
+ self.epoch = epoch
+
+ def __len__(self):
+ return self.length
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index 402f1e38fed9e32722e2dd160f10f779028807a3..f7c4c8f1a21ddb36e27fe4c1a217ce3fa9caff41 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -12,6 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
+import cv2
+import math
import os
import json
import random
@@ -48,11 +50,31 @@ class SimpleDataSet(Dataset):
self.data_idx_order_list = list(range(len(self.data_lines)))
if self.mode == "train" and self.do_shuffle:
self.shuffle_data_random()
+
+ self.set_epoch_as_seed(self.seed, dataset_config)
+
self.ops = create_operators(dataset_config['transforms'], global_config)
self.ext_op_transform_idx = dataset_config.get("ext_op_transform_idx",
2)
self.need_reset = True in [x < 1 for x in ratio_list]
+ def set_epoch_as_seed(self, seed, dataset_config):
+ if self.mode == 'train':
+ try:
+ border_map_id = [index
+ for index, dictionary in enumerate(dataset_config['transforms'])
+ if 'MakeBorderMap' in dictionary][0]
+ shrink_map_id = [index
+ for index, dictionary in enumerate(dataset_config['transforms'])
+ if 'MakeShrinkMap' in dictionary][0]
+ dataset_config['transforms'][border_map_id]['MakeBorderMap'][
+ 'epoch'] = seed if seed is not None else 0
+ dataset_config['transforms'][shrink_map_id]['MakeShrinkMap'][
+ 'epoch'] = seed if seed is not None else 0
+ except Exception as E:
+ print(E)
+ return
+
def get_image_info_list(self, file_list, ratio_list):
if isinstance(file_list, str):
file_list = [file_list]
@@ -149,3 +171,96 @@ class SimpleDataSet(Dataset):
def __len__(self):
return len(self.data_idx_order_list)
+
+
+class MultiScaleDataSet(SimpleDataSet):
+ def __init__(self, config, mode, logger, seed=None):
+ super(MultiScaleDataSet, self).__init__(config, mode, logger, seed)
+ self.ds_width = config[mode]['dataset'].get('ds_width', False)
+ if self.ds_width:
+ self.wh_aware()
+
+ def wh_aware(self):
+ data_line_new = []
+ wh_ratio = []
+ for lins in self.data_lines:
+ data_line_new.append(lins)
+ lins = lins.decode('utf-8')
+ name, label, w, h = lins.strip("\n").split(self.delimiter)
+ wh_ratio.append(float(w) / float(h))
+
+ self.data_lines = data_line_new
+ self.wh_ratio = np.array(wh_ratio)
+ self.wh_ratio_sort = np.argsort(self.wh_ratio)
+ self.data_idx_order_list = list(range(len(self.data_lines)))
+
+ def resize_norm_img(self, data, imgW, imgH, padding=True):
+ img = data['image']
+ h = img.shape[0]
+ w = img.shape[1]
+ if not padding:
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ else:
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ padding_im = np.zeros((3, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, :resized_w] = resized_image
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ data['image'] = padding_im
+ data['valid_ratio'] = valid_ratio
+ return data
+
+ def __getitem__(self, properties):
+ # properites is a tuple, contains (width, height, index)
+ img_height = properties[1]
+ idx = properties[2]
+ if self.ds_width and properties[3] is not None:
+ wh_ratio = properties[3]
+ img_width = img_height * (1 if int(round(wh_ratio)) == 0 else
+ int(round(wh_ratio)))
+ file_idx = self.wh_ratio_sort[idx]
+ else:
+ file_idx = self.data_idx_order_list[idx]
+ img_width = properties[0]
+ wh_ratio = None
+
+ data_line = self.data_lines[file_idx]
+ try:
+ data_line = data_line.decode('utf-8')
+ substr = data_line.strip("\n").split(self.delimiter)
+ file_name = substr[0]
+ file_name = self._try_parse_filename_list(file_name)
+ label = substr[1]
+ img_path = os.path.join(self.data_dir, file_name)
+ data = {'img_path': img_path, 'label': label}
+ if not os.path.exists(img_path):
+ raise Exception("{} does not exist!".format(img_path))
+ with open(data['img_path'], 'rb') as f:
+ img = f.read()
+ data['image'] = img
+ data['ext_data'] = self.get_ext_data()
+ outs = transform(data, self.ops[:-1])
+ if outs is not None:
+ outs = self.resize_norm_img(outs, img_width, img_height)
+ outs = transform(outs, self.ops[-1:])
+ except:
+ self.logger.error(
+ "When parsing line {}, error happened with msg: {}".format(
+ data_line, traceback.format_exc()))
+ outs = None
+ if outs is None:
+ # during evaluation, we should fix the idx to get same results for many times of evaluation.
+ rnd_idx = (idx + 1) % self.__len__()
+ return self.__getitem__([img_width, img_height, rnd_idx, wh_ratio])
+ return outs
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index c7142e3e5e73e25764dde4631a47be939905e3be..9e6a45478e108637494db694d6a05c8db5b5a40e 100644
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -41,6 +41,8 @@ from .rec_vl_loss import VLLoss
from .rec_spin_att_loss import SPINAttentionLoss
from .rec_rfl_loss import RFLLoss
from .rec_can_loss import CANLoss
+from .rec_satrn_loss import SATRNLoss
+from .rec_nrtr_loss import NRTRLoss
# cls loss
from .cls_loss import ClsLoss
@@ -73,7 +75,8 @@ def build_loss(config):
'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss',
'TableMasterLoss', 'SPINAttentionLoss', 'VLLoss', 'StrokeFocusLoss',
- 'SLALoss', 'CTLoss', 'RFLLoss', 'DRRGLoss', 'CANLoss', 'TelescopeLoss'
+ 'SLALoss', 'CTLoss', 'RFLLoss', 'DRRGLoss', 'CANLoss', 'TelescopeLoss',
+ 'SATRNLoss', 'NRTRLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index 58410b4db2157074c2cb0f7db590c84021e10ace..9ad854cd120c996e2c18c61f00718e5826b25372 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -165,3 +165,79 @@ class LossFromOutput(nn.Layer):
elif self.reduction == 'sum':
loss = paddle.sum(loss)
return {'loss': loss}
+
+
+class KLDivLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self):
+ super().__init__()
+
+ def _kldiv(self, x, target, mask=None):
+ eps = 1.0e-10
+ loss = target * (paddle.log(target + eps) - x)
+ if mask is not None:
+ loss = loss.flatten(0, 1).sum(axis=1)
+ loss = loss.masked_select(mask).mean()
+ else:
+ # batch mean loss
+ loss = paddle.sum(loss) / loss.shape[0]
+ return loss
+
+ def forward(self, logits_s, logits_t, mask=None):
+ log_out_s = F.log_softmax(logits_s, axis=-1)
+ out_t = F.softmax(logits_t, axis=-1)
+ loss = self._kldiv(log_out_s, out_t, mask)
+ return loss
+
+
+class DKDLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self, temperature=1.0, alpha=1.0, beta=1.0):
+ super().__init__()
+ self.temperature = temperature
+ self.alpha = alpha
+ self.beta = beta
+
+ def _cat_mask(self, t, mask1, mask2):
+ t1 = (t * mask1).sum(axis=1, keepdim=True)
+ t2 = (t * mask2).sum(axis=1, keepdim=True)
+ rt = paddle.concat([t1, t2], axis=1)
+ return rt
+
+ def _kl_div(self, x, label, mask=None):
+ y = (label * (paddle.log(label + 1e-10) - x)).sum(axis=1)
+ if mask is not None:
+ y = y.masked_select(mask).mean()
+ else:
+ y = y.mean()
+ return y
+
+ def forward(self, logits_student, logits_teacher, target, mask=None):
+ gt_mask = F.one_hot(
+ target.reshape([-1]), num_classes=logits_student.shape[-1])
+ other_mask = 1 - gt_mask
+ logits_student = logits_student.flatten(0, 1)
+ logits_teacher = logits_teacher.flatten(0, 1)
+ pred_student = F.softmax(logits_student / self.temperature, axis=1)
+ pred_teacher = F.softmax(logits_teacher / self.temperature, axis=1)
+ pred_student = self._cat_mask(pred_student, gt_mask, other_mask)
+ pred_teacher = self._cat_mask(pred_teacher, gt_mask, other_mask)
+ log_pred_student = paddle.log(pred_student)
+ tckd_loss = self._kl_div(log_pred_student,
+ pred_teacher) * (self.temperature**2)
+ pred_teacher_part2 = F.softmax(
+ logits_teacher / self.temperature - 1000.0 * gt_mask, axis=1)
+ log_pred_student_part2 = F.log_softmax(
+ logits_student / self.temperature - 1000.0 * gt_mask, axis=1)
+ nckd_loss = self._kl_div(log_pred_student_part2,
+ pred_teacher_part2) * (self.temperature**2)
+
+ loss = self.alpha * tckd_loss + self.beta * nckd_loss
+
+ return loss
diff --git a/ppocr/losses/combined_loss.py b/ppocr/losses/combined_loss.py
index 8d697d544b51899cdafeff94be2ecce067b907a2..a520f10ffb6a83b444fb98c7d461bbcfaf4ce14d 100644
--- a/ppocr/losses/combined_loss.py
+++ b/ppocr/losses/combined_loss.py
@@ -20,9 +20,9 @@ from .center_loss import CenterLoss
from .ace_loss import ACELoss
from .rec_sar_loss import SARLoss
-from .distillation_loss import DistillationCTCLoss
-from .distillation_loss import DistillationSARLoss
-from .distillation_loss import DistillationDMLLoss
+from .distillation_loss import DistillationCTCLoss, DistillCTCLogits
+from .distillation_loss import DistillationSARLoss, DistillationNRTRLoss
+from .distillation_loss import DistillationDMLLoss, DistillationKLDivLoss, DistillationDKDLoss
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
from .distillation_loss import DistillationVQASerTokenLayoutLMLoss, DistillationSERDMLLoss
from .distillation_loss import DistillationLossFromOutput
diff --git a/ppocr/losses/det_db_loss.py b/ppocr/losses/det_db_loss.py
index 708ffbdb47f349304e2bfd781a836e79348475f4..ce31ef124591ce3e5351460eb94ca50490bcf0e5 100755
--- a/ppocr/losses/det_db_loss.py
+++ b/ppocr/losses/det_db_loss.py
@@ -20,6 +20,7 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
+import paddle
from paddle import nn
from .det_basic_loss import BalanceLoss, MaskL1Loss, DiceLoss
@@ -66,11 +67,21 @@ class DBLoss(nn.Layer):
label_shrink_mask)
loss_shrink_maps = self.alpha * loss_shrink_maps
loss_threshold_maps = self.beta * loss_threshold_maps
+ # CBN loss
+ if 'distance_maps' in predicts.keys():
+ distance_maps = predicts['distance_maps']
+ cbn_maps = predicts['cbn_maps']
+ cbn_loss = self.bce_loss(cbn_maps[:, 0, :, :], label_shrink_map,
+ label_shrink_mask)
+ else:
+ dis_loss = paddle.to_tensor([0.])
+ cbn_loss = paddle.to_tensor([0.])
loss_all = loss_shrink_maps + loss_threshold_maps \
+ loss_binary_maps
- losses = {'loss': loss_all, \
+ losses = {'loss': loss_all+ cbn_loss, \
"loss_shrink_maps": loss_shrink_maps, \
"loss_threshold_maps": loss_threshold_maps, \
- "loss_binary_maps": loss_binary_maps}
+ "loss_binary_maps": loss_binary_maps, \
+ "loss_cbn": cbn_loss}
return losses
diff --git a/ppocr/losses/distillation_loss.py b/ppocr/losses/distillation_loss.py
index 4bfbed75a338e2bd3bca0b80d16028030bf2f0b5..5812544e91d8357c161e4faa4d0e36ce4dbd9374 100644
--- a/ppocr/losses/distillation_loss.py
+++ b/ppocr/losses/distillation_loss.py
@@ -14,12 +14,14 @@
import paddle
import paddle.nn as nn
+import paddle.nn.functional as F
import numpy as np
import cv2
from .rec_ctc_loss import CTCLoss
from .rec_sar_loss import SARLoss
-from .basic_loss import DMLLoss
+from .rec_ce_loss import CELoss
+from .basic_loss import DMLLoss, KLDivLoss, DKDLoss
from .basic_loss import DistanceLoss
from .basic_loss import LossFromOutput
from .det_db_loss import DBLoss
@@ -102,7 +104,6 @@ class DistillationDMLLoss(DMLLoss):
if self.key is not None:
out1 = out1[self.key]
out2 = out2[self.key]
-
if self.maps_name is None:
if self.multi_head:
loss = super().forward(out1[self.dis_head],
@@ -133,6 +134,449 @@ class DistillationDMLLoss(DMLLoss):
return loss_dict
+class DistillationKLDivLoss(KLDivLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="kl_div"):
+ super().__init__()
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head], non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationDKDLoss(DKDLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="dkd",
+ temperature=1.0,
+ alpha=1.0,
+ beta=1.0):
+ super().__init__(temperature, alpha, beta)
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 +
+ max_len] # [batch_size, max_len + 1]
+
+ tgt = tgt.reshape([-1]) # batch_size * (max_len + 1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape,
+ dtype=tgt.dtype)) # batch_size * (max_len + 1)
+
+ loss = super().forward(
+ out1[self.dis_head], out2[self.dis_head], tgt,
+ non_pad_mask) # [batch_size, max_len + 1, num_char]
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationNRTRDMLLoss(DistillationDMLLoss):
+ """
+ """
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head], out2[self.dis_head],
+ non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationKLDivLoss(KLDivLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="kl_div"):
+ super().__init__()
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 + max_len]
+ tgt = tgt.reshape([-1])
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head], non_pad_mask)
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
+class DistillationDKDLoss(DKDLoss):
+ """
+ """
+
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ multi_head=False,
+ dis_head='ctc',
+ maps_name=None,
+ name="dkd",
+ temperature=1.0,
+ alpha=1.0,
+ beta=1.0):
+ super().__init__(temperature, alpha, beta)
+ assert isinstance(model_name_pairs, list)
+ self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.name = name
+ self.maps_name = self._check_maps_name(maps_name)
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def _check_maps_name(self, maps_name):
+ if maps_name is None:
+ return None
+ elif type(maps_name) == str:
+ return [maps_name]
+ elif type(maps_name) == list:
+ return [maps_name]
+ else:
+ return None
+
+ def _slice_out(self, outs):
+ new_outs = {}
+ for k in self.maps_name:
+ if k == "thrink_maps":
+ new_outs[k] = outs[:, 0, :, :]
+ elif k == "threshold_maps":
+ new_outs[k] = outs[:, 1, :, :]
+ elif k == "binary_maps":
+ new_outs[k] = outs[:, 2, :, :]
+ else:
+ continue
+ return new_outs
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+ if self.key is not None:
+ out1 = out1[self.key]
+ out2 = out2[self.key]
+ if self.maps_name is None:
+ if self.multi_head:
+ # for nrtr dml loss
+ max_len = batch[3].max()
+ tgt = batch[2][:, 1:2 +
+ max_len] # [batch_size, max_len + 1]
+
+ tgt = tgt.reshape([-1]) # batch_size * (max_len + 1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape,
+ dtype=tgt.dtype)) # batch_size * (max_len + 1)
+
+ loss = super().forward(
+ out1[self.dis_head], out2[self.dis_head], tgt,
+ non_pad_mask) # [batch_size, max_len + 1, num_char]
+ else:
+ loss = super().forward(out1, out2)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ else:
+ outs1 = self._slice_out(out1)
+ outs2 = self._slice_out(out2)
+ for _c, k in enumerate(outs1.keys()):
+ loss = super().forward(outs1[k], outs2[k])
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}_{}_{}".format(key, pair[
+ 0], pair[1], self.maps_name, idx)] = loss[key]
+ else:
+ loss_dict["{}_{}_{}".format(self.name, self.maps_name[
+ _c], idx)] = loss
+
+ loss_dict = _sum_loss(loss_dict)
+
+ return loss_dict
+
+
class DistillationCTCLoss(CTCLoss):
def __init__(self,
model_name_list=[],
@@ -199,6 +643,40 @@ class DistillationSARLoss(SARLoss):
return loss_dict
+class DistillationNRTRLoss(CELoss):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ smoothing=True,
+ name="loss_nrtr",
+ **kwargs):
+ super().__init__(smoothing=smoothing)
+ self.model_name_list = model_name_list
+ self.key = key
+ self.name = name
+ self.multi_head = multi_head
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, model_name in enumerate(self.model_name_list):
+ out = predicts[model_name]
+ if self.key is not None:
+ out = out[self.key]
+ if self.multi_head:
+ assert 'gtc' in out, 'multi head has multi out'
+ loss = super().forward(out['gtc'], batch[:1] + batch[2:])
+ else:
+ loss = super().forward(out, batch)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, model_name)] = loss
+ return loss_dict
+
+
class DistillationDBLoss(DBLoss):
def __init__(self,
model_name_list=[],
@@ -459,3 +937,212 @@ class DistillationVQADistanceLoss(DistanceLoss):
loss_dict["{}_{}_{}_{}".format(self.name, pair[0], pair[1],
idx)] = loss
return loss_dict
+
+
+class CTCDKDLoss(nn.Layer):
+ """
+ KLDivLoss
+ """
+
+ def __init__(self, temperature=0.5, alpha=1.0, beta=1.0):
+ super().__init__()
+ self.temperature = temperature
+ self.alpha = alpha
+ self.beta = beta
+ self.eps = 1e-6
+ self.t = temperature
+ self.act = nn.Softmax(axis=-1)
+ self.use_log = True
+
+ def kl_loss(self, p1, p2): # predict, label
+ loss = paddle.multiply(
+ p2, paddle.log((p2 + self.eps) / (p1 + self.eps) + self.eps))
+ bs = loss.shape[0]
+ loss = paddle.sum(loss) / bs
+ return loss
+
+ def _cat_mask(self, t, mask1, mask2):
+ t1 = (t * mask1).sum(axis=1, keepdim=True)
+ t2 = (t * mask2).sum(axis=1, keepdim=True)
+ rt = paddle.concat([t1, t2], axis=1)
+ return rt
+
+ def multi_label_mask(self, targets):
+
+ targets = targets.astype("int32")
+ res = F.one_hot(targets, num_classes=11465)
+ mask = paddle.clip(paddle.sum(res, axis=1), 0, 1)
+ mask[:, 0] = 0 # ingore ctc blank label
+ return mask
+
+ def forward(self, logits_student, logits_teacher, targets, mask=None):
+
+ gt_mask = self.multi_label_mask(targets)
+ other_mask = paddle.ones_like(gt_mask) - gt_mask
+
+ pred_student = F.softmax(logits_student / self.temperature, axis=-1)
+ pred_teacher = F.softmax(logits_teacher / self.temperature, axis=-1)
+
+ # differents with dkd
+ pred_student = paddle.mean(pred_student, axis=1)
+ pred_teacher = paddle.mean(pred_teacher, axis=1)
+
+ pred_student = self._cat_mask(pred_student, gt_mask, other_mask)
+ pred_teacher = self._cat_mask(pred_teacher, gt_mask, other_mask)
+
+ # differents with dkd
+ tckd_loss = self.kl_loss(pred_student, pred_teacher)
+
+ gt_mask_ex = paddle.expand_as(gt_mask.unsqueeze(axis=1), logits_teacher)
+ pred_teacher_part2 = F.softmax(
+ logits_teacher / self.temperature - 1000.0 * gt_mask_ex, axis=-1)
+ pred_student_part2 = F.softmax(
+ logits_student / self.temperature - 1000.0 * gt_mask_ex, axis=-1)
+ # differents with dkd
+ pred_teacher_part2 = paddle.mean(pred_teacher_part2, axis=1)
+ pred_student_part2 = paddle.mean(pred_student_part2, axis=1)
+
+ # differents with dkd
+ nckd_loss = self.kl_loss(pred_student_part2, pred_teacher_part2)
+ loss = self.alpha * tckd_loss + self.beta * nckd_loss
+ return loss
+
+
+class KLCTCLogits(nn.Layer):
+ def __init__(self, weight=1.0, reduction='mean', mode="mean"):
+ super().__init__()
+ self.weight = weight
+ self.reduction = reduction
+ self.eps = 1e-6
+ self.t = 0.5
+ self.act = nn.Softmax(axis=-1)
+ self.use_log = True
+ self.mode = mode
+ self.ctc_dkd_loss = CTCDKDLoss()
+
+ def kl_loss(self, p1, p2): # predict, label
+ loss = paddle.multiply(
+ p2, paddle.log((p2 + self.eps) / (p1 + self.eps) + self.eps))
+ bs = loss.shape[0]
+ loss = paddle.sum(loss) / bs
+ return loss
+
+ def forward_meanmax(self, stu_out, tea_out):
+
+ stu_out = paddle.mean(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.mean(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ loss = self.kl_loss(stu_out, tea_out)
+
+ return loss
+
+ def forward_meanlog(self, stu_out, tea_out):
+ stu_out = paddle.mean(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.mean(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ if self.use_log is True:
+ # for recognition distillation, log is needed for feature map
+ log_out1 = paddle.log(stu_out)
+ log_out2 = paddle.log(tea_out)
+ loss = (
+ self._kldiv(log_out1, tea_out) + self._kldiv(log_out2, stu_out)
+ ) / 2.0
+
+ return loss
+
+ def forward_sum(self, stu_out, tea_out):
+ stu_out = paddle.sum(F.softmax(stu_out / self.t, axis=-1), axis=1)
+ tea_out = paddle.sum(F.softmax(tea_out / self.t, axis=-1), axis=1)
+ stu_out = paddle.log(stu_out)
+ bs = stu_out.shape[0]
+ loss = tea_out * (paddle.log(tea_out + self.eps) - stu_out)
+ loss = paddle.sum(loss, axis=1) / loss.shape[0]
+ return loss
+
+ def _kldiv(self, x, target):
+ eps = 1.0e-10
+ loss = target * (paddle.log(target + eps) - x)
+ loss = paddle.sum(paddle.mean(loss, axis=1)) / loss.shape[0]
+ return loss
+
+ def forward(self, stu_out, tea_out, targets=None):
+ if self.mode == "log":
+ return self.forward_log(stu_out, tea_out)
+ elif self.mode == "mean":
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.forward_meanmax(stu_out, tea_out)
+ elif self.mode == "sum":
+ return self.forward_sum(stu_out, tea_out)
+ elif self.mode == "meanlog":
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.forward_meanlog(stu_out, tea_out)
+ elif self.mode == "ctcdkd":
+ # ingore ctc blank logits
+ blank_mask = paddle.ones_like(stu_out)
+ blank_mask.stop_gradient = True
+ blank_mask[:, :, 0] = -1
+ stu_out *= blank_mask
+ tea_out *= blank_mask
+ return self.ctc_dkd_loss(stu_out, tea_out, targets)
+ else:
+ raise ValueError("error!!!!!!")
+
+ def forward_log(self, out1, out2):
+ if self.act is not None:
+ out1 = self.act(out1) + 1e-10
+ out2 = self.act(out2) + 1e-10
+ if self.use_log is True:
+ # for recognition distillation, log is needed for feature map
+ log_out1 = paddle.log(out1)
+ log_out2 = paddle.log(out2)
+ loss = (
+ self._kldiv(log_out1, out2) + self._kldiv(log_out2, out1)) / 2.0
+
+ return loss
+
+
+class DistillCTCLogits(KLCTCLogits):
+ def __init__(self,
+ model_name_pairs=[],
+ key=None,
+ name="ctc_logits",
+ reduction="mean"):
+ super().__init__(reduction=reduction)
+ self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
+ self.key = key
+ self.name = name
+
+ def _check_model_name_pairs(self, model_name_pairs):
+ if not isinstance(model_name_pairs, list):
+ return []
+ elif isinstance(model_name_pairs[0], list) and isinstance(
+ model_name_pairs[0][0], str):
+ return model_name_pairs
+ else:
+ return [model_name_pairs]
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, pair in enumerate(self.model_name_pairs):
+ out1 = predicts[pair[0]]
+ out2 = predicts[pair[1]]
+
+ if self.key is not None:
+ out1 = out1[self.key]['ctc']
+ out2 = out2[self.key]['ctc']
+
+ ctc_label = batch[1]
+ loss = super().forward(out1, out2, ctc_label)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, idx)] = loss
+ return loss_dict
diff --git a/ppocr/losses/rec_aster_loss.py b/ppocr/losses/rec_aster_loss.py
index 52605e46db35339cc22f7f1e6642456bfaf02f11..9b0a34eeac57089ae1d45ad9d8c0427b234c50c9 100644
--- a/ppocr/losses/rec_aster_loss.py
+++ b/ppocr/losses/rec_aster_loss.py
@@ -28,7 +28,7 @@ class CosineEmbeddingLoss(nn.Layer):
def forward(self, x1, x2, target):
similarity = paddle.sum(
- x1 * x2, dim=-1) / (paddle.norm(
+ x1 * x2, axis=-1) / (paddle.norm(
x1, axis=-1) * paddle.norm(
x2, axis=-1) + self.epsilon)
one_list = paddle.full_like(target, fill_value=1)
diff --git a/ppocr/losses/rec_multi_loss.py b/ppocr/losses/rec_multi_loss.py
index 09f007afe6303e83b9a6948df553ec0fca8b6b2d..4f9365750b29368b6fa70e300e6d1b6562ccd4db 100644
--- a/ppocr/losses/rec_multi_loss.py
+++ b/ppocr/losses/rec_multi_loss.py
@@ -21,6 +21,7 @@ from paddle import nn
from .rec_ctc_loss import CTCLoss
from .rec_sar_loss import SARLoss
+from .rec_nrtr_loss import NRTRLoss
class MultiLoss(nn.Layer):
@@ -30,7 +31,6 @@ class MultiLoss(nn.Layer):
self.loss_list = kwargs.pop('loss_config_list')
self.weight_1 = kwargs.get('weight_1', 1.0)
self.weight_2 = kwargs.get('weight_2', 1.0)
- self.gtc_loss = kwargs.get('gtc_loss', 'sar')
for loss_info in self.loss_list:
for name, param in loss_info.items():
if param is not None:
@@ -49,6 +49,9 @@ class MultiLoss(nn.Layer):
elif name == 'SARLoss':
loss = loss_func(predicts['sar'],
batch[:1] + batch[2:])['loss'] * self.weight_2
+ elif name == 'NRTRLoss':
+ loss = loss_func(predicts['nrtr'],
+ batch[:1] + batch[2:])['loss'] * self.weight_2
else:
raise NotImplementedError(
'{} is not supported in MultiLoss yet'.format(name))
diff --git a/ppocr/losses/rec_nrtr_loss.py b/ppocr/losses/rec_nrtr_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbd397fbf0be638d9b43ae5abb36ae1cfc3bb9eb
--- /dev/null
+++ b/ppocr/losses/rec_nrtr_loss.py
@@ -0,0 +1,32 @@
+import paddle
+from paddle import nn
+import paddle.nn.functional as F
+
+
+class NRTRLoss(nn.Layer):
+ def __init__(self, smoothing=True, ignore_index=0, **kwargs):
+ super(NRTRLoss, self).__init__()
+ if ignore_index >= 0 and not smoothing:
+ self.loss_func = nn.CrossEntropyLoss(
+ reduction='mean', ignore_index=ignore_index)
+ self.smoothing = smoothing
+
+ def forward(self, pred, batch):
+ max_len = batch[2].max()
+ tgt = batch[1][:, 1:2 + max_len]
+ pred = pred.reshape([-1, pred.shape[2]])
+ tgt = tgt.reshape([-1])
+ if self.smoothing:
+ eps = 0.1
+ n_class = pred.shape[1]
+ one_hot = F.one_hot(tgt, pred.shape[1])
+ one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)
+ log_prb = F.log_softmax(pred, axis=1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = -(one_hot * log_prb).sum(axis=1)
+ loss = loss.masked_select(non_pad_mask).mean()
+ else:
+ loss = self.loss_func(pred, tgt)
+ return {'loss': loss}
diff --git a/ppocr/losses/rec_satrn_loss.py b/ppocr/losses/rec_satrn_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc7b517878d5349154fa6a9c6e05fe6d45a00dd7
--- /dev/null
+++ b/ppocr/losses/rec_satrn_loss.py
@@ -0,0 +1,46 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/module_losses/ce_module_loss.py
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import nn
+
+
+class SATRNLoss(nn.Layer):
+ def __init__(self, **kwargs):
+ super(SATRNLoss, self).__init__()
+ ignore_index = kwargs.get('ignore_index', 92) # 6626
+ self.loss_func = paddle.nn.loss.CrossEntropyLoss(
+ reduction="none", ignore_index=ignore_index)
+
+ def forward(self, predicts, batch):
+ predict = predicts[:, :
+ -1, :] # ignore last index of outputs to be in same seq_len with targets
+ label = batch[1].astype(
+ "int64")[:, 1:] # ignore first index of target in loss calculation
+ batch_size, num_steps, num_classes = predict.shape[0], predict.shape[
+ 1], predict.shape[2]
+ assert len(label.shape) == len(list(predict.shape)) - 1, \
+ "The target's shape and inputs's shape is [N, d] and [N, num_steps]"
+
+ inputs = paddle.reshape(predict, [-1, num_classes])
+ targets = paddle.reshape(label, [-1])
+ loss = self.loss_func(inputs, targets)
+ return {'loss': loss.mean()}
diff --git a/ppocr/modeling/architectures/__init__.py b/ppocr/modeling/architectures/__init__.py
index 1c955ef3abe9c38e816616cc9b5399c6832aa5f1..00220d28de9387859102d6cf9bc4bb66c923a3fe 100755
--- a/ppocr/modeling/architectures/__init__.py
+++ b/ppocr/modeling/architectures/__init__.py
@@ -38,9 +38,11 @@ def build_model(config):
def apply_to_static(model, config, logger):
if config["Global"].get("to_static", False) is not True:
return model
- assert "image_shape" in config[
- "Global"], "image_shape must be assigned for static training mode..."
- supported_list = ["DB", "SVTR"]
+ assert "d2s_train_image_shape" in config[
+ "Global"], "d2s_train_image_shape must be assigned for static training mode..."
+ supported_list = [
+ "DB", "SVTR_LCNet", "TableMaster", "LayoutXLM", "SLANet", "SVTR"
+ ]
if config["Architecture"]["algorithm"] in ["Distillation"]:
algo = list(config["Architecture"]["Models"].values())[0]["algorithm"]
else:
@@ -49,10 +51,10 @@ def apply_to_static(model, config, logger):
specs = [
InputSpec(
- [None] + config["Global"]["image_shape"], dtype='float32')
+ [None] + config["Global"]["d2s_train_image_shape"], dtype='float32')
]
- if algo == "SVTR":
+ if algo == "SVTR_LCNet":
specs.append([
InputSpec(
[None, config["Global"]["max_text_length"]],
@@ -62,7 +64,55 @@ def apply_to_static(model, config, logger):
[None], dtype='int64'), InputSpec(
[None], dtype='float64')
])
-
+ elif algo == "TableMaster":
+ specs.append(
+ [
+ InputSpec(
+ [None, config["Global"]["max_text_length"]], dtype='int64'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"], 4],
+ dtype='float32'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"], 1],
+ dtype='float32'),
+ InputSpec(
+ [None, 6], dtype='float32'),
+ ])
+ elif algo == "LayoutXLM":
+ specs = [[
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # input_ids
+ InputSpec(
+ shape=[None, 512, 4], dtype="int64"), # bbox
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # attention_mask
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # token_type_ids
+ InputSpec(
+ shape=[None, 3, 224, 224], dtype="float32"), # image
+ InputSpec(
+ shape=[None, 512], dtype="int64"), # label
+ ]]
+ elif algo == "SLANet":
+ specs.append([
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2], dtype='int64'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2, 4],
+ dtype='float32'),
+ InputSpec(
+ [None, config["Global"]["max_text_length"] + 2, 1],
+ dtype='float32'),
+ InputSpec(
+ [None, 6], dtype='float64'),
+ ])
+ elif algo == "SVTR":
+ specs.append([
+ InputSpec(
+ [None, config["Global"]["max_text_length"]], dtype='int64'),
+ InputSpec(
+ [None], dtype='int64')
+ ])
model = to_static(model, input_spec=specs)
logger.info("Successfully to apply @to_static with specs: {}".format(specs))
return model
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index e2c2e9c4a4ed526b36d512d824ae8a8a701c17bc..873e8f6de1249bc8f76c4b720b1555d794ba9c4c 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -22,8 +22,11 @@ def build_backbone(config, model_type):
from .det_resnet_vd import ResNet_vd
from .det_resnet_vd_sast import ResNet_SAST
from .det_pp_lcnet import PPLCNet
+ from .rec_lcnetv3 import PPLCNetV3
+ from .rec_hgnet import PPHGNet_small
support_dict = [
- "MobileNetV3", "ResNet", "ResNet_vd", "ResNet_SAST", "PPLCNet"
+ "MobileNetV3", "ResNet", "ResNet_vd", "ResNet_SAST", "PPLCNet",
+ "PPLCNetV3", "PPHGNet_small"
]
if model_type == "table":
from .table_master_resnet import TableResNetExtra
@@ -44,11 +47,14 @@ def build_backbone(config, model_type):
from .rec_vitstr import ViTSTR
from .rec_resnet_rfl import ResNetRFL
from .rec_densenet import DenseNet
+ from .rec_shallow_cnn import ShallowCNN
+ from .rec_lcnetv3 import PPLCNetV3
+ from .rec_hgnet import PPHGNet_small
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
'ResNet31', 'ResNet45', 'ResNet_ASTER', 'MicroNet',
'EfficientNetb3_PREN', 'SVTRNet', 'ViTSTR', 'ResNet32', 'ResNetRFL',
- 'DenseNet'
+ 'DenseNet', 'ShallowCNN', 'PPLCNetV3', 'PPHGNet_small'
]
elif model_type == 'e2e':
from .e2e_resnet_vd_pg import ResNet
diff --git a/ppocr/modeling/backbones/rec_hgnet.py b/ppocr/modeling/backbones/rec_hgnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d990453308a47f3e68f2d899c01edf3ecbdae8db
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_hgnet.py
@@ -0,0 +1,350 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle.nn.initializer import KaimingNormal, Constant
+from paddle.nn import Conv2D, BatchNorm2D, ReLU, AdaptiveAvgPool2D, MaxPool2D
+from paddle.regularizer import L2Decay
+from paddle import ParamAttr
+
+kaiming_normal_ = KaimingNormal()
+zeros_ = Constant(value=0.)
+ones_ = Constant(value=1.)
+
+
+class ConvBNAct(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=1,
+ use_act=True):
+ super().__init__()
+ self.use_act = use_act
+ self.conv = Conv2D(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ bias_attr=False)
+ self.bn = BatchNorm2D(
+ out_channels,
+ weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
+ bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
+ if self.use_act:
+ self.act = ReLU()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.bn(x)
+ if self.use_act:
+ x = self.act(x)
+ return x
+
+
+class ESEModule(nn.Layer):
+ def __init__(self, channels):
+ super().__init__()
+ self.avg_pool = AdaptiveAvgPool2D(1)
+ self.conv = Conv2D(
+ in_channels=channels,
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ self.sigmoid = nn.Sigmoid()
+
+ def forward(self, x):
+ identity = x
+ x = self.avg_pool(x)
+ x = self.conv(x)
+ x = self.sigmoid(x)
+ return paddle.multiply(x=identity, y=x)
+
+
+class HG_Block(nn.Layer):
+ def __init__(
+ self,
+ in_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=False, ):
+ super().__init__()
+ self.identity = identity
+
+ self.layers = nn.LayerList()
+ self.layers.append(
+ ConvBNAct(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=3,
+ stride=1))
+ for _ in range(layer_num - 1):
+ self.layers.append(
+ ConvBNAct(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=3,
+ stride=1))
+
+ # feature aggregation
+ total_channels = in_channels + layer_num * mid_channels
+ self.aggregation_conv = ConvBNAct(
+ in_channels=total_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1)
+ self.att = ESEModule(out_channels)
+
+ def forward(self, x):
+ identity = x
+ output = []
+ output.append(x)
+ for layer in self.layers:
+ x = layer(x)
+ output.append(x)
+ x = paddle.concat(output, axis=1)
+ x = self.aggregation_conv(x)
+ x = self.att(x)
+ if self.identity:
+ x += identity
+ return x
+
+
+class HG_Stage(nn.Layer):
+ def __init__(self,
+ in_channels,
+ mid_channels,
+ out_channels,
+ block_num,
+ layer_num,
+ downsample=True,
+ stride=[2, 1]):
+ super().__init__()
+ self.downsample = downsample
+ if downsample:
+ self.downsample = ConvBNAct(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ stride=stride,
+ groups=in_channels,
+ use_act=False)
+
+ blocks_list = []
+ blocks_list.append(
+ HG_Block(
+ in_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=False))
+ for _ in range(block_num - 1):
+ blocks_list.append(
+ HG_Block(
+ out_channels,
+ mid_channels,
+ out_channels,
+ layer_num,
+ identity=True))
+ self.blocks = nn.Sequential(*blocks_list)
+
+ def forward(self, x):
+ if self.downsample:
+ x = self.downsample(x)
+ x = self.blocks(x)
+ return x
+
+
+class PPHGNet(nn.Layer):
+ """
+ PPHGNet
+ Args:
+ stem_channels: list. Stem channel list of PPHGNet.
+ stage_config: dict. The configuration of each stage of PPHGNet. such as the number of channels, stride, etc.
+ layer_num: int. Number of layers of HG_Block.
+ use_last_conv: boolean. Whether to use a 1x1 convolutional layer before the classification layer.
+ class_expand: int=2048. Number of channels for the last 1x1 convolutional layer.
+ dropout_prob: float. Parameters of dropout, 0.0 means dropout is not used.
+ class_num: int=1000. The number of classes.
+ Returns:
+ model: nn.Layer. Specific PPHGNet model depends on args.
+ """
+
+ def __init__(
+ self,
+ stem_channels,
+ stage_config,
+ layer_num,
+ in_channels=3,
+ det=False,
+ out_indices=None, ):
+ super().__init__()
+ self.det = det
+ self.out_indices = out_indices if out_indices is not None else [
+ 0, 1, 2, 3
+ ]
+
+ # stem
+ stem_channels.insert(0, in_channels)
+ self.stem = nn.Sequential(* [
+ ConvBNAct(
+ in_channels=stem_channels[i],
+ out_channels=stem_channels[i + 1],
+ kernel_size=3,
+ stride=2 if i == 0 else 1) for i in range(
+ len(stem_channels) - 1)
+ ])
+
+ if self.det:
+ self.pool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
+ # stages
+ self.stages = nn.LayerList()
+ self.out_channels = []
+ for block_id, k in enumerate(stage_config):
+ in_channels, mid_channels, out_channels, block_num, downsample, stride = stage_config[
+ k]
+ self.stages.append(
+ HG_Stage(in_channels, mid_channels, out_channels, block_num,
+ layer_num, downsample, stride))
+ if block_id in self.out_indices:
+ self.out_channels.append(out_channels)
+
+ if not self.det:
+ self.out_channels = stage_config["stage4"][2]
+
+ self._init_weights()
+
+ def _init_weights(self):
+ for m in self.sublayers():
+ if isinstance(m, nn.Conv2D):
+ kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2D)):
+ ones_(m.weight)
+ zeros_(m.bias)
+ elif isinstance(m, nn.Linear):
+ zeros_(m.bias)
+
+ def forward(self, x):
+ x = self.stem(x)
+ if self.det:
+ x = self.pool(x)
+
+ out = []
+ for i, stage in enumerate(self.stages):
+ x = stage(x)
+ if self.det and i in self.out_indices:
+ out.append(x)
+ if self.det:
+ return out
+
+ if self.training:
+ x = F.adaptive_avg_pool2d(x, [1, 40])
+ else:
+ x = F.avg_pool2d(x, [3, 2])
+ return x
+
+
+def PPHGNet_tiny(pretrained=False, use_ssld=False, **kwargs):
+ """
+ PPHGNet_tiny
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_tiny` model depends on args.
+ """
+ stage_config = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [96, 96, 224, 1, False, [2, 1]],
+ "stage2": [224, 128, 448, 1, True, [1, 2]],
+ "stage3": [448, 160, 512, 2, True, [2, 1]],
+ "stage4": [512, 192, 768, 1, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[48, 48, 96],
+ stage_config=stage_config,
+ layer_num=5,
+ **kwargs)
+ return model
+
+
+def PPHGNet_small(pretrained=False, use_ssld=False, det=False, **kwargs):
+ """
+ PPHGNet_small
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_small` model depends on args.
+ """
+ stage_config_det = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [128, 128, 256, 1, False, 2],
+ "stage2": [256, 160, 512, 1, True, 2],
+ "stage3": [512, 192, 768, 2, True, 2],
+ "stage4": [768, 224, 1024, 1, True, 2],
+ }
+
+ stage_config_rec = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [128, 128, 256, 1, True, [2, 1]],
+ "stage2": [256, 160, 512, 1, True, [1, 2]],
+ "stage3": [512, 192, 768, 2, True, [2, 1]],
+ "stage4": [768, 224, 1024, 1, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[64, 64, 128],
+ stage_config=stage_config_det if det else stage_config_rec,
+ layer_num=6,
+ det=det,
+ **kwargs)
+ return model
+
+
+def PPHGNet_base(pretrained=False, use_ssld=True, **kwargs):
+ """
+ PPHGNet_base
+ Args:
+ pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
+ If str, means the path of the pretrained model.
+ use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
+ Returns:
+ model: nn.Layer. Specific `PPHGNet_base` model depends on args.
+ """
+ stage_config = {
+ # in_channels, mid_channels, out_channels, blocks, downsample
+ "stage1": [160, 192, 320, 1, False, [2, 1]],
+ "stage2": [320, 224, 640, 2, True, [1, 2]],
+ "stage3": [640, 256, 960, 3, True, [2, 1]],
+ "stage4": [960, 288, 1280, 2, True, [2, 1]],
+ }
+
+ model = PPHGNet(
+ stem_channels=[96, 96, 160],
+ stage_config=stage_config,
+ layer_num=7,
+ dropout_prob=0.2,
+ **kwargs)
+ return model
diff --git a/ppocr/modeling/backbones/rec_lcnetv3.py b/ppocr/modeling/backbones/rec_lcnetv3.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab0951761d0c13d9ad8e0884118086a93f39269b
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_lcnetv3.py
@@ -0,0 +1,491 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import ParamAttr
+from paddle.nn.initializer import Constant, KaimingNormal
+from paddle.nn import AdaptiveAvgPool2D, BatchNorm2D, Conv2D, Dropout, Hardsigmoid, Hardswish, Identity, Linear, ReLU
+from paddle.regularizer import L2Decay
+
+NET_CONFIG_det = {
+ "blocks2":
+ #k, in_c, out_c, s, use_se
+ [[3, 16, 32, 1, False]],
+ "blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
+ "blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
+ "blocks5":
+ [[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False],
+ [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
+ "blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True],
+ [5, 512, 512, 1, False], [5, 512, 512, 1, False]]
+}
+
+NET_CONFIG_rec = {
+ "blocks2":
+ #k, in_c, out_c, s, use_se
+ [[3, 16, 32, 1, False]],
+ "blocks3": [[3, 32, 64, 1, False], [3, 64, 64, 1, False]],
+ "blocks4": [[3, 64, 128, (2, 1), False], [3, 128, 128, 1, False]],
+ "blocks5":
+ [[3, 128, 256, (1, 2), False], [5, 256, 256, 1, False],
+ [5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
+ "blocks6": [[5, 256, 512, (2, 1), True], [5, 512, 512, 1, True],
+ [5, 512, 512, (2, 1), False], [5, 512, 512, 1, False]]
+}
+
+
+def make_divisible(v, divisor=16, min_value=None):
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
+
+
+class LearnableAffineBlock(nn.Layer):
+ def __init__(self, scale_value=1.0, bias_value=0.0, lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.scale = self.create_parameter(
+ shape=[1, ],
+ default_initializer=Constant(value=scale_value),
+ attr=ParamAttr(learning_rate=lr_mult * lab_lr))
+ self.add_parameter("scale", self.scale)
+ self.bias = self.create_parameter(
+ shape=[1, ],
+ default_initializer=Constant(value=bias_value),
+ attr=ParamAttr(learning_rate=lr_mult * lab_lr))
+ self.add_parameter("bias", self.bias)
+
+ def forward(self, x):
+ return self.scale * x + self.bias
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=1,
+ lr_mult=1.0):
+ super().__init__()
+ self.conv = Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(
+ initializer=KaimingNormal(), learning_rate=lr_mult),
+ bias_attr=False)
+
+ self.bn = BatchNorm2D(
+ out_channels,
+ weight_attr=ParamAttr(
+ regularizer=L2Decay(0.0), learning_rate=lr_mult),
+ bias_attr=ParamAttr(
+ regularizer=L2Decay(0.0), learning_rate=lr_mult))
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.bn(x)
+ return x
+
+
+class Act(nn.Layer):
+ def __init__(self, act="hswish", lr_mult=1.0, lab_lr=0.1):
+ super().__init__()
+ if act == "hswish":
+ self.act = Hardswish()
+ else:
+ assert act == "relu"
+ self.act = ReLU()
+ self.lab = LearnableAffineBlock(lr_mult=lr_mult, lab_lr=lab_lr)
+
+ def forward(self, x):
+ return self.lab(self.act(x))
+
+
+class LearnableRepLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ groups=1,
+ num_conv_branches=1,
+ lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.is_repped = False
+ self.groups = groups
+ self.stride = stride
+ self.kernel_size = kernel_size
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_conv_branches = num_conv_branches
+ self.padding = (kernel_size - 1) // 2
+
+ self.identity = BatchNorm2D(
+ num_features=in_channels,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult)
+ ) if out_channels == in_channels and stride == 1 else None
+
+ self.conv_kxk = nn.LayerList([
+ ConvBNLayer(
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride,
+ groups=groups,
+ lr_mult=lr_mult) for _ in range(self.num_conv_branches)
+ ])
+
+ self.conv_1x1 = ConvBNLayer(
+ in_channels,
+ out_channels,
+ 1,
+ stride,
+ groups=groups,
+ lr_mult=lr_mult) if kernel_size > 1 else None
+
+ self.lab = LearnableAffineBlock(lr_mult=lr_mult, lab_lr=lab_lr)
+ self.act = Act(lr_mult=lr_mult, lab_lr=lab_lr)
+
+ def forward(self, x):
+ # for export
+ if self.is_repped:
+ out = self.lab(self.reparam_conv(x))
+ if self.stride != 2:
+ out = self.act(out)
+ return out
+
+ out = 0
+ if self.identity is not None:
+ out += self.identity(x)
+
+ if self.conv_1x1 is not None:
+ out += self.conv_1x1(x)
+
+ for conv in self.conv_kxk:
+ out += conv(x)
+
+ out = self.lab(out)
+ if self.stride != 2:
+ out = self.act(out)
+ return out
+
+ def rep(self):
+ if self.is_repped:
+ return
+ kernel, bias = self._get_kernel_bias()
+ self.reparam_conv = Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ groups=self.groups)
+ self.reparam_conv.weight.set_value(kernel)
+ self.reparam_conv.bias.set_value(bias)
+ self.is_repped = True
+
+ def _pad_kernel_1x1_to_kxk(self, kernel1x1, pad):
+ if not isinstance(kernel1x1, paddle.Tensor):
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [pad, pad, pad, pad])
+
+ def _get_kernel_bias(self):
+ kernel_conv_1x1, bias_conv_1x1 = self._fuse_bn_tensor(self.conv_1x1)
+ kernel_conv_1x1 = self._pad_kernel_1x1_to_kxk(kernel_conv_1x1,
+ self.kernel_size // 2)
+
+ kernel_identity, bias_identity = self._fuse_bn_tensor(self.identity)
+
+ kernel_conv_kxk = 0
+ bias_conv_kxk = 0
+ for conv in self.conv_kxk:
+ kernel, bias = self._fuse_bn_tensor(conv)
+ kernel_conv_kxk += kernel
+ bias_conv_kxk += bias
+
+ kernel_reparam = kernel_conv_kxk + kernel_conv_1x1 + kernel_identity
+ bias_reparam = bias_conv_kxk + bias_conv_1x1 + bias_identity
+ return kernel_reparam, bias_reparam
+
+ def _fuse_bn_tensor(self, branch):
+ if not branch:
+ return 0, 0
+ elif isinstance(branch, ConvBNLayer):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = paddle.zeros(
+ (self.in_channels, input_dim, self.kernel_size,
+ self.kernel_size),
+ dtype=branch.weight.dtype)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, self.kernel_size // 2,
+ self.kernel_size // 2] = 1
+ self.id_tensor = kernel_value
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+class SELayer(nn.Layer):
+ def __init__(self, channel, reduction=4, lr_mult=1.0):
+ super().__init__()
+ self.avg_pool = AdaptiveAvgPool2D(1)
+ self.conv1 = Conv2D(
+ in_channels=channel,
+ out_channels=channel // reduction,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult))
+ self.relu = ReLU()
+ self.conv2 = Conv2D(
+ in_channels=channel // reduction,
+ out_channels=channel,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ weight_attr=ParamAttr(learning_rate=lr_mult),
+ bias_attr=ParamAttr(learning_rate=lr_mult))
+ self.hardsigmoid = Hardsigmoid()
+
+ def forward(self, x):
+ identity = x
+ x = self.avg_pool(x)
+ x = self.conv1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.hardsigmoid(x)
+ x = paddle.multiply(x=identity, y=x)
+ return x
+
+
+class LCNetV3Block(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride,
+ dw_size,
+ use_se=False,
+ conv_kxk_num=4,
+ lr_mult=1.0,
+ lab_lr=0.1):
+ super().__init__()
+ self.use_se = use_se
+ self.dw_conv = LearnableRepLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=dw_size,
+ stride=stride,
+ groups=in_channels,
+ num_conv_branches=conv_kxk_num,
+ lr_mult=lr_mult,
+ lab_lr=lab_lr)
+ if use_se:
+ self.se = SELayer(in_channels, lr_mult=lr_mult)
+ self.pw_conv = LearnableRepLayer(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ num_conv_branches=conv_kxk_num,
+ lr_mult=lr_mult,
+ lab_lr=lab_lr)
+
+ def forward(self, x):
+ x = self.dw_conv(x)
+ if self.use_se:
+ x = self.se(x)
+ x = self.pw_conv(x)
+ return x
+
+
+class PPLCNetV3(nn.Layer):
+ def __init__(self,
+ scale=1.0,
+ conv_kxk_num=4,
+ lr_mult_list=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
+ lab_lr=0.1,
+ det=False,
+ **kwargs):
+ super().__init__()
+ self.scale = scale
+ self.lr_mult_list = lr_mult_list
+ self.det = det
+
+ self.net_config = NET_CONFIG_det if self.det else NET_CONFIG_rec
+
+ assert isinstance(self.lr_mult_list, (
+ list, tuple
+ )), "lr_mult_list should be in (list, tuple) but got {}".format(
+ type(self.lr_mult_list))
+ assert len(self.lr_mult_list
+ ) == 6, "lr_mult_list length should be 6 but got {}".format(
+ len(self.lr_mult_list))
+
+ self.conv1 = ConvBNLayer(
+ in_channels=3,
+ out_channels=make_divisible(16 * scale),
+ kernel_size=3,
+ stride=2,
+ lr_mult=self.lr_mult_list[0])
+
+ self.blocks2 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[1],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks2"])
+ ])
+
+ self.blocks3 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[2],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks3"])
+ ])
+
+ self.blocks4 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[3],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks4"])
+ ])
+
+ self.blocks5 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[4],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks5"])
+ ])
+
+ self.blocks6 = nn.Sequential(*[
+ LCNetV3Block(
+ in_channels=make_divisible(in_c * scale),
+ out_channels=make_divisible(out_c * scale),
+ dw_size=k,
+ stride=s,
+ use_se=se,
+ conv_kxk_num=conv_kxk_num,
+ lr_mult=self.lr_mult_list[5],
+ lab_lr=lab_lr)
+ for i, (k, in_c, out_c, s, se
+ ) in enumerate(self.net_config["blocks6"])
+ ])
+ self.out_channels = make_divisible(512 * scale)
+
+ if self.det:
+ mv_c = [16, 24, 56, 480]
+ self.out_channels = [
+ make_divisible(self.net_config["blocks3"][-1][2] * scale),
+ make_divisible(self.net_config["blocks4"][-1][2] * scale),
+ make_divisible(self.net_config["blocks5"][-1][2] * scale),
+ make_divisible(self.net_config["blocks6"][-1][2] * scale),
+ ]
+
+ self.layer_list = nn.LayerList([
+ nn.Conv2D(self.out_channels[0], int(mv_c[0] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[1], int(mv_c[1] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[2], int(mv_c[2] * scale), 1, 1, 0),
+ nn.Conv2D(self.out_channels[3], int(mv_c[3] * scale), 1, 1, 0)
+ ])
+ self.out_channels = [
+ int(mv_c[0] * scale), int(mv_c[1] * scale),
+ int(mv_c[2] * scale), int(mv_c[3] * scale)
+ ]
+
+ def forward(self, x):
+ out_list = []
+ x = self.conv1(x)
+
+ x = self.blocks2(x)
+ x = self.blocks3(x)
+ out_list.append(x)
+ x = self.blocks4(x)
+ out_list.append(x)
+ x = self.blocks5(x)
+ out_list.append(x)
+ x = self.blocks6(x)
+ out_list.append(x)
+
+ if self.det:
+ out_list[0] = self.layer_list[0](out_list[0])
+ out_list[1] = self.layer_list[1](out_list[1])
+ out_list[2] = self.layer_list[2](out_list[2])
+ out_list[3] = self.layer_list[3](out_list[3])
+ return out_list
+
+ if self.training:
+ x = F.adaptive_avg_pool2d(x, [1, 40])
+ else:
+ x = F.avg_pool2d(x, [3, 2])
+ return x
diff --git a/ppocr/modeling/backbones/rec_mv1_enhance.py b/ppocr/modeling/backbones/rec_mv1_enhance.py
index bb6af5e82cf13ac42d9a970787596a65986ade54..2d4efe720991618f33cbc42c0fb84bc795bc7437 100644
--- a/ppocr/modeling/backbones/rec_mv1_enhance.py
+++ b/ppocr/modeling/backbones/rec_mv1_enhance.py
@@ -108,6 +108,7 @@ class MobileNetV1Enhance(nn.Layer):
scale=0.5,
last_conv_stride=1,
last_pool_type='max',
+ last_pool_kernel_size=[3, 2],
**kwargs):
super().__init__()
self.scale = scale
@@ -214,7 +215,10 @@ class MobileNetV1Enhance(nn.Layer):
self.block_list = nn.Sequential(*self.block_list)
if last_pool_type == 'avg':
- self.pool = nn.AvgPool2D(kernel_size=2, stride=2, padding=0)
+ self.pool = nn.AvgPool2D(
+ kernel_size=last_pool_kernel_size,
+ stride=last_pool_kernel_size,
+ padding=0)
else:
self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = int(1024 * scale)
diff --git a/ppocr/modeling/backbones/rec_shallow_cnn.py b/ppocr/modeling/backbones/rec_shallow_cnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..544f108d26397421ae77ee025b15f31e319ab54c
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_shallow_cnn.py
@@ -0,0 +1,87 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/backbones/shallow_cnn.py
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+import numpy as np
+import paddle
+from paddle import ParamAttr
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle.nn import MaxPool2D
+from paddle.nn.initializer import KaimingNormal, Uniform, Constant
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ num_channels,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ num_groups=1):
+ super(ConvBNLayer, self).__init__()
+
+ self.conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False)
+
+ self.bn = nn.BatchNorm2D(
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(0, 1)),
+ bias_attr=ParamAttr(initializer=Constant(0)))
+ self.relu = nn.ReLU()
+
+ def forward(self, inputs):
+ y = self.conv(inputs)
+ y = self.bn(y)
+ y = self.relu(y)
+ return y
+
+
+class ShallowCNN(nn.Layer):
+ def __init__(self, in_channels=1, hidden_dim=512):
+ super().__init__()
+ assert isinstance(in_channels, int)
+ assert isinstance(hidden_dim, int)
+
+ self.conv1 = ConvBNLayer(
+ in_channels, 3, hidden_dim // 2, stride=1, padding=1)
+ self.conv2 = ConvBNLayer(
+ hidden_dim // 2, 3, hidden_dim, stride=1, padding=1)
+ self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
+ self.out_channels = hidden_dim
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = self.pool(x)
+
+ x = self.conv2(x)
+ x = self.pool(x)
+
+ return x
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
index c2c07f4476929d49237c8e9a10713f881f5f556b..ea865a2da148bc5a0afe9eea4f74c1f26d782649 100644
--- a/ppocr/modeling/backbones/rec_svtrnet.py
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -32,7 +32,7 @@ def drop_path(x, drop_prob=0., training=False):
"""
if drop_prob == 0. or not training:
return x
- keep_prob = paddle.to_tensor(1 - drop_prob)
+ keep_prob = paddle.to_tensor(1 - drop_prob, dtype=x.dtype)
shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
@@ -155,8 +155,9 @@ class Attention(nn.Layer):
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim**-0.5
+ self.dim = dim
+ self.head_dim = dim // num_heads
+ self.scale = qk_scale or self.head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
@@ -183,13 +184,9 @@ class Attention(nn.Layer):
self.mixer = mixer
def forward(self, x):
- if self.HW is not None:
- N = self.N
- C = self.C
- else:
- _, N, C = x.shape
- qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
- self.num_heads)).transpose((2, 0, 3, 1, 4))
+ qkv = self.qkv(x).reshape(
+ (0, -1, 3, self.num_heads, self.head_dim)).transpose(
+ (2, 0, 3, 1, 4))
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = (q.matmul(k.transpose((0, 1, 3, 2))))
@@ -198,7 +195,7 @@ class Attention(nn.Layer):
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
- x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, -1, self.dim))
x = self.proj(x)
x = self.proj_drop(x)
return x
diff --git a/ppocr/modeling/backbones/vqa_layoutlm.py b/ppocr/modeling/backbones/vqa_layoutlm.py
index acb1315cc0a588396549e5b8928bd2e4d3c769be..4357b5664587d74ecf0e1fc54a427a138a2f656e 100644
--- a/ppocr/modeling/backbones/vqa_layoutlm.py
+++ b/ppocr/modeling/backbones/vqa_layoutlm.py
@@ -54,18 +54,11 @@ class NLPBaseModel(nn.Layer):
if checkpoints is not None: # load the trained model
self.model = model_class.from_pretrained(checkpoints)
else: # load the pretrained-model
- pretrained_model_name = pretrained_model_dict[base_model_class][
- mode]
- if pretrained is True:
- base_model = base_model_class.from_pretrained(
- pretrained_model_name)
- else:
- base_model = base_model_class.from_pretrained(pretrained)
+ pretrained_model_name = pretrained_model_dict[base_model_class][mode]
if type == "ser":
- self.model = model_class(
- base_model, num_classes=kwargs["num_classes"], dropout=None)
+ self.model = model_class.from_pretrained(pretrained_model_name, num_classes=kwargs["num_classes"], dropout=0)
else:
- self.model = model_class(base_model, dropout=None)
+ self.model = model_class.from_pretrained(pretrained_model_name, dropout=0)
self.out_channels = 1
self.use_visual_backbone = True
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index 65afaf84f4453f2d4199371576ac71bb93a1e6d5..440d9e0293af2c92c3c3bfbba82b39a851fd1331 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -17,14 +17,13 @@ __all__ = ['build_head']
def build_head(config):
# det head
- from .det_db_head import DBHead
+ from .det_db_head import DBHead, PFHeadLocal
from .det_east_head import EASTHead
from .det_sast_head import SASTHead
from .det_pse_head import PSEHead
from .det_fce_head import FCEHead
from .e2e_pg_head import PGHead
from .det_ct_head import CT_Head
-
# rec head
from .rec_ctc_head import CTCHead
from .rec_att_head import AttentionHead
@@ -40,6 +39,7 @@ def build_head(config):
from .rec_visionlan_head import VLHead
from .rec_rfl_head import RFLHead
from .rec_can_head import CANHead
+ from .rec_satrn_head import SATRNHead
# cls head
from .cls_head import ClsHead
@@ -56,7 +56,7 @@ def build_head(config):
'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
'MultiHead', 'ABINetHead', 'TableMasterHead', 'SPINAttentionHead',
'VLHead', 'SLAHead', 'RobustScannerHead', 'CT_Head', 'RFLHead',
- 'DRRGHead', 'CANHead'
+ 'DRRGHead', 'CANHead', 'SATRNHead', 'PFHeadLocal'
]
if config['name'] == 'DRRGHead':
diff --git a/ppocr/modeling/heads/det_db_head.py b/ppocr/modeling/heads/det_db_head.py
index a686ae5ab0662ad31ddfd339bd1999c45c370cf0..8db14d7f6f043b53f2df3c929579c202358e5345 100644
--- a/ppocr/modeling/heads/det_db_head.py
+++ b/ppocr/modeling/heads/det_db_head.py
@@ -21,6 +21,7 @@ import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
+from ppocr.modeling.backbones.det_mobilenet_v3 import ConvBNLayer
def get_bias_attr(k):
@@ -31,7 +32,7 @@ def get_bias_attr(k):
class Head(nn.Layer):
- def __init__(self, in_channels, name_list, kernel_list=[3, 2, 2], **kwargs):
+ def __init__(self, in_channels, kernel_list=[3, 2, 2], **kwargs):
super(Head, self).__init__()
self.conv1 = nn.Conv2D(
@@ -48,6 +49,7 @@ class Head(nn.Layer):
bias_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1e-4)),
act='relu')
+
self.conv2 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=in_channels // 4,
@@ -72,13 +74,17 @@ class Head(nn.Layer):
initializer=paddle.nn.initializer.KaimingUniform()),
bias_attr=get_bias_attr(in_channels // 4), )
- def forward(self, x):
+ def forward(self, x, return_f=False):
x = self.conv1(x)
x = self.conv_bn1(x)
x = self.conv2(x)
x = self.conv_bn2(x)
+ if return_f is True:
+ f = x
x = self.conv3(x)
x = F.sigmoid(x)
+ if return_f is True:
+ return x, f
return x
@@ -93,16 +99,8 @@ class DBHead(nn.Layer):
def __init__(self, in_channels, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
- binarize_name_list = [
- 'conv2d_56', 'batch_norm_47', 'conv2d_transpose_0', 'batch_norm_48',
- 'conv2d_transpose_1', 'binarize'
- ]
- thresh_name_list = [
- 'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
- 'conv2d_transpose_3', 'thresh'
- ]
- self.binarize = Head(in_channels, binarize_name_list, **kwargs)
- self.thresh = Head(in_channels, thresh_name_list, **kwargs)
+ self.binarize = Head(in_channels, **kwargs)
+ self.thresh = Head(in_channels, **kwargs)
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
@@ -116,3 +114,41 @@ class DBHead(nn.Layer):
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
return {'maps': y}
+
+
+class LocalModule(nn.Layer):
+ def __init__(self, in_c, mid_c, use_distance=True):
+ super(self.__class__, self).__init__()
+ self.last_3 = ConvBNLayer(in_c + 1, mid_c, 3, 1, 1, act='relu')
+ self.last_1 = nn.Conv2D(mid_c, 1, 1, 1, 0)
+
+ def forward(self, x, init_map, distance_map):
+ outf = paddle.concat([init_map, x], axis=1)
+ # last Conv
+ out = self.last_1(self.last_3(outf))
+ return out
+
+
+class PFHeadLocal(DBHead):
+ def __init__(self, in_channels, k=50, mode='small', **kwargs):
+ super(PFHeadLocal, self).__init__(in_channels, k, **kwargs)
+ self.mode = mode
+
+ self.up_conv = nn.Upsample(scale_factor=2, mode="nearest", align_mode=1)
+ if self.mode == 'large':
+ self.cbn_layer = LocalModule(in_channels // 4, in_channels // 4)
+ elif self.mode == 'small':
+ self.cbn_layer = LocalModule(in_channels // 4, in_channels // 8)
+
+ def forward(self, x, targets=None):
+ shrink_maps, f = self.binarize(x, return_f=True)
+ base_maps = shrink_maps
+ cbn_maps = self.cbn_layer(self.up_conv(f), shrink_maps, None)
+ cbn_maps = F.sigmoid(cbn_maps)
+ if not self.training:
+ return {'maps': 0.5 * (base_maps + cbn_maps), 'cbn_maps': cbn_maps}
+
+ threshold_maps = self.thresh(x)
+ binary_maps = self.step_function(shrink_maps, threshold_maps)
+ y = paddle.concat([cbn_maps, threshold_maps, binary_maps], axis=1)
+ return {'maps': y, 'distance_maps': cbn_maps, 'cbn_maps': binary_maps}
diff --git a/ppocr/modeling/heads/proposal_local_graph.py b/ppocr/modeling/heads/proposal_local_graph.py
index 7887c4ff42f8ae9d1826a71f01208cd81bb2d52c..a48656135b2292f32c7285e767f8fea1a7318e08 100644
--- a/ppocr/modeling/heads/proposal_local_graph.py
+++ b/ppocr/modeling/heads/proposal_local_graph.py
@@ -40,7 +40,7 @@ def fill_hole(input_mask):
mask = np.zeros((h + 4, w + 4), np.uint8)
cv2.floodFill(canvas, mask, (0, 0), 1)
- canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool_)
return ~canvas | input_mask
diff --git a/ppocr/modeling/heads/rec_multi_head.py b/ppocr/modeling/heads/rec_multi_head.py
index 2f10e7bdf90025d3304128e720ce561c8bb269c1..0b4fa939eecad15c79f5e37384944720b1879205 100644
--- a/ppocr/modeling/heads/rec_multi_head.py
+++ b/ppocr/modeling/heads/rec_multi_head.py
@@ -25,12 +25,28 @@ import paddle.nn.functional as F
from ppocr.modeling.necks.rnn import Im2Seq, EncoderWithRNN, EncoderWithFC, SequenceEncoder, EncoderWithSVTR
from .rec_ctc_head import CTCHead
from .rec_sar_head import SARHead
+from .rec_nrtr_head import Transformer
+
+
+class FCTranspose(nn.Layer):
+ def __init__(self, in_channels, out_channels, only_transpose=False):
+ super().__init__()
+ self.only_transpose = only_transpose
+ if not self.only_transpose:
+ self.fc = nn.Linear(in_channels, out_channels, bias_attr=False)
+
+ def forward(self, x):
+ if self.only_transpose:
+ return x.transpose([0, 2, 1])
+ else:
+ return self.fc(x.transpose([0, 2, 1]))
class MultiHead(nn.Layer):
def __init__(self, in_channels, out_channels_list, **kwargs):
super().__init__()
self.head_list = kwargs.pop('head_list')
+
self.gtc_head = 'sar'
assert len(self.head_list) >= 2
for idx, head_name in enumerate(self.head_list):
@@ -40,12 +56,27 @@ class MultiHead(nn.Layer):
sar_args = self.head_list[idx][name]
self.sar_head = eval(name)(in_channels=in_channels, \
out_channels=out_channels_list['SARLabelDecode'], **sar_args)
+ elif name == 'NRTRHead':
+ gtc_args = self.head_list[idx][name]
+ max_text_length = gtc_args.get('max_text_length', 25)
+ nrtr_dim = gtc_args.get('nrtr_dim', 256)
+ num_decoder_layers = gtc_args.get('num_decoder_layers', 4)
+ self.before_gtc = nn.Sequential(
+ nn.Flatten(2), FCTranspose(in_channels, nrtr_dim))
+ self.gtc_head = Transformer(
+ d_model=nrtr_dim,
+ nhead=nrtr_dim // 32,
+ num_encoder_layers=-1,
+ beam_size=-1,
+ num_decoder_layers=num_decoder_layers,
+ max_len=max_text_length,
+ dim_feedforward=nrtr_dim * 4,
+ out_channels=out_channels_list['NRTRLabelDecode'])
elif name == 'CTCHead':
# ctc neck
self.encoder_reshape = Im2Seq(in_channels)
neck_args = self.head_list[idx][name]['Neck']
encoder_type = neck_args.pop('name')
- self.encoder = encoder_type
self.ctc_encoder = SequenceEncoder(in_channels=in_channels, \
encoder_type=encoder_type, **neck_args)
# ctc head
@@ -57,6 +88,7 @@ class MultiHead(nn.Layer):
'{} is not supported in MultiHead yet'.format(name))
def forward(self, x, targets=None):
+
ctc_encoder = self.ctc_encoder(x)
ctc_out = self.ctc_head(ctc_encoder, targets)
head_out = dict()
@@ -68,6 +100,7 @@ class MultiHead(nn.Layer):
if self.gtc_head == 'sar':
sar_out = self.sar_head(x, targets[1:])
head_out['sar'] = sar_out
- return head_out
else:
- return head_out
+ gtc_out = self.gtc_head(self.before_gtc(x), targets[1:])
+ head_out['nrtr'] = gtc_out
+ return head_out
diff --git a/ppocr/modeling/heads/rec_nrtr_head.py b/ppocr/modeling/heads/rec_nrtr_head.py
index bf9ef56145e6edfb15bd30235b4a62588396ba96..eb279400203b9ef173793bc0d90e5ab99701cb3a 100644
--- a/ppocr/modeling/heads/rec_nrtr_head.py
+++ b/ppocr/modeling/heads/rec_nrtr_head.py
@@ -162,7 +162,7 @@ class Transformer(nn.Layer):
memory = src
dec_seq = paddle.full((bs, 1), 2, dtype=paddle.int64)
dec_prob = paddle.full((bs, 1), 1., dtype=paddle.float32)
- for len_dec_seq in range(1, self.max_len):
+ for len_dec_seq in range(1, paddle.to_tensor(self.max_len)):
dec_seq_embed = self.embedding(dec_seq)
dec_seq_embed = self.positional_encoding(dec_seq_embed)
tgt_mask = self.generate_square_subsequent_mask(
@@ -304,7 +304,7 @@ class Transformer(nn.Layer):
inst_idx_to_position_map = get_inst_idx_to_tensor_position_map(
active_inst_idx_list)
# Decode
- for len_dec_seq in range(1, self.max_len):
+ for len_dec_seq in range(1, paddle.to_tensor(self.max_len)):
src_enc_copy = src_enc.clone()
active_inst_idx_list = beam_decode_step(
inst_dec_beams, len_dec_seq, src_enc_copy,
diff --git a/ppocr/modeling/heads/rec_robustscanner_head.py b/ppocr/modeling/heads/rec_robustscanner_head.py
index 7956059ecfe01f27db364d3d748d6af24dad0aac..550836bd401b0b8799e2afb9b185de8ed6b3d5b1 100644
--- a/ppocr/modeling/heads/rec_robustscanner_head.py
+++ b/ppocr/modeling/heads/rec_robustscanner_head.py
@@ -99,10 +99,11 @@ class DotProductAttentionLayer(nn.Layer):
logits = paddle.reshape(logits, [n, c, h, w])
if valid_ratios is not None:
# cal mask of attention weight
- for i, valid_ratio in enumerate(valid_ratios):
- valid_width = min(w, int(w * valid_ratio + 0.5))
- if valid_width < w:
- logits[i, :, :, valid_width:] = float('-inf')
+ with paddle.fluid.framework._stride_in_no_check_dy2st_diff():
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, int(w * valid_ratio + 0.5))
+ if valid_width < w:
+ logits[i, :, :, valid_width:] = float('-inf')
# reshape to (n, c, h, w)
logits = paddle.reshape(logits, [n, c, t])
diff --git a/ppocr/modeling/heads/rec_sar_head.py b/ppocr/modeling/heads/rec_sar_head.py
index 5e64cae85afafc555f2519ed6dd3f05eafff7ea2..11fe253b67f82ec321bcd3b51c39de318a7aec2f 100644
--- a/ppocr/modeling/heads/rec_sar_head.py
+++ b/ppocr/modeling/heads/rec_sar_head.py
@@ -276,7 +276,9 @@ class ParallelSARDecoder(BaseDecoder):
hf_c = holistic_feat.shape[-1]
holistic_feat = paddle.expand(
holistic_feat, shape=[bsz, seq_len, hf_c])
- y = self.prediction(paddle.concat((y, attn_feat, holistic_feat), 2))
+ y = self.prediction(
+ paddle.concat((y, attn_feat.astype(y.dtype),
+ holistic_feat.astype(y.dtype)), 2))
else:
y = self.prediction(attn_feat)
# bsz * (seq_len + 1) * num_classes
@@ -298,7 +300,7 @@ class ParallelSARDecoder(BaseDecoder):
lab_embedding = self.embedding(label)
# bsz * seq_len * emb_dim
- out_enc = out_enc.unsqueeze(1)
+ out_enc = out_enc.unsqueeze(1).astype(lab_embedding.dtype)
# bsz * 1 * emb_dim
in_dec = paddle.concat((out_enc, lab_embedding), axis=1)
# bsz * (seq_len + 1) * C
diff --git a/ppocr/modeling/heads/rec_satrn_head.py b/ppocr/modeling/heads/rec_satrn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b969c89693b677489b7191a9120f16d02c322802
--- /dev/null
+++ b/ppocr/modeling/heads/rec_satrn_head.py
@@ -0,0 +1,568 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/encoders/satrn_encoder.py
+https://github.com/open-mmlab/mmocr/blob/1.x/mmocr/models/textrecog/decoders/nrtr_decoder.py
+"""
+
+import math
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import ParamAttr, reshape, transpose
+from paddle.nn import Conv2D, BatchNorm, Linear, Dropout
+from paddle.nn import AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
+from paddle.nn.initializer import KaimingNormal, Uniform, Constant
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ num_channels,
+ filter_size,
+ num_filters,
+ stride,
+ padding,
+ num_groups=1):
+ super(ConvBNLayer, self).__init__()
+
+ self.conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=padding,
+ groups=num_groups,
+ bias_attr=False)
+
+ self.bn = nn.BatchNorm2D(
+ num_filters,
+ weight_attr=ParamAttr(initializer=Constant(1)),
+ bias_attr=ParamAttr(initializer=Constant(0)))
+ self.relu = nn.ReLU()
+
+ def forward(self, inputs):
+ y = self.conv(inputs)
+ y = self.bn(y)
+ y = self.relu(y)
+ return y
+
+
+class SATRNEncoderLayer(nn.Layer):
+ def __init__(self,
+ d_model=512,
+ d_inner=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.norm1 = nn.LayerNorm(d_model)
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.feed_forward = LocalityAwareFeedforward(
+ d_model, d_inner, dropout=dropout)
+
+ def forward(self, x, h, w, mask=None):
+ n, hw, c = x.shape
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+ residual = x
+ x = self.norm2(x)
+ x = x.transpose([0, 2, 1]).reshape([n, c, h, w])
+ x = self.feed_forward(x)
+ x = x.reshape([n, c, hw]).transpose([0, 2, 1])
+ x = residual + x
+ return x
+
+
+class LocalityAwareFeedforward(nn.Layer):
+ def __init__(
+ self,
+ d_in,
+ d_hid,
+ dropout=0.1, ):
+ super().__init__()
+ self.conv1 = ConvBNLayer(d_in, 1, d_hid, stride=1, padding=0)
+
+ self.depthwise_conv = ConvBNLayer(
+ d_hid, 3, d_hid, stride=1, padding=1, num_groups=d_hid)
+
+ self.conv2 = ConvBNLayer(d_hid, 1, d_in, stride=1, padding=0)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.depthwise_conv(x)
+ x = self.conv2(x)
+
+ return x
+
+
+class Adaptive2DPositionalEncoding(nn.Layer):
+ def __init__(self, d_hid=512, n_height=100, n_width=100, dropout=0.1):
+ super().__init__()
+
+ h_position_encoder = self._get_sinusoid_encoding_table(n_height, d_hid)
+ h_position_encoder = h_position_encoder.transpose([1, 0])
+ h_position_encoder = h_position_encoder.reshape([1, d_hid, n_height, 1])
+
+ w_position_encoder = self._get_sinusoid_encoding_table(n_width, d_hid)
+ w_position_encoder = w_position_encoder.transpose([1, 0])
+ w_position_encoder = w_position_encoder.reshape([1, d_hid, 1, n_width])
+
+ self.register_buffer('h_position_encoder', h_position_encoder)
+ self.register_buffer('w_position_encoder', w_position_encoder)
+
+ self.h_scale = self.scale_factor_generate(d_hid)
+ self.w_scale = self.scale_factor_generate(d_hid)
+ self.pool = nn.AdaptiveAvgPool2D(1)
+ self.dropout = nn.Dropout(p=dropout)
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = paddle.to_tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.reshape([1, -1])
+ pos_tensor = paddle.cast(
+ paddle.arange(n_position).unsqueeze(-1), 'float32')
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = paddle.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = paddle.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table
+
+ def scale_factor_generate(self, d_hid):
+ scale_factor = nn.Sequential(
+ nn.Conv2D(d_hid, d_hid, 1),
+ nn.ReLU(), nn.Conv2D(d_hid, d_hid, 1), nn.Sigmoid())
+
+ return scale_factor
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+
+ avg_pool = self.pool(x)
+
+ h_pos_encoding = \
+ self.h_scale(avg_pool) * self.h_position_encoder[:, :, :h, :]
+ w_pos_encoding = \
+ self.w_scale(avg_pool) * self.w_position_encoder[:, :, :, :w]
+
+ out = x + h_pos_encoding + w_pos_encoding
+
+ out = self.dropout(out)
+
+ return out
+
+
+class ScaledDotProductAttention(nn.Layer):
+ def __init__(self, temperature, attn_dropout=0.1):
+ super().__init__()
+ self.temperature = temperature
+ self.dropout = nn.Dropout(attn_dropout)
+
+ def forward(self, q, k, v, mask=None):
+ def masked_fill(x, mask, value):
+ y = paddle.full(x.shape, value, x.dtype)
+ return paddle.where(mask, y, x)
+
+ attn = paddle.matmul(q / self.temperature, k.transpose([0, 1, 3, 2]))
+ if mask is not None:
+ attn = masked_fill(attn, mask == 0, -1e9)
+ # attn = attn.masked_fill(mask == 0, float('-inf'))
+ # attn += mask
+
+ attn = self.dropout(F.softmax(attn, axis=-1))
+ output = paddle.matmul(attn, v)
+
+ return output, attn
+
+
+class MultiHeadAttention(nn.Layer):
+ def __init__(self,
+ n_head=8,
+ d_model=512,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.n_head = n_head
+ self.d_k = d_k
+ self.d_v = d_v
+
+ self.dim_k = n_head * d_k
+ self.dim_v = n_head * d_v
+
+ self.linear_q = nn.Linear(self.dim_k, self.dim_k, bias_attr=qkv_bias)
+ self.linear_k = nn.Linear(self.dim_k, self.dim_k, bias_attr=qkv_bias)
+ self.linear_v = nn.Linear(self.dim_v, self.dim_v, bias_attr=qkv_bias)
+
+ self.attention = ScaledDotProductAttention(d_k**0.5, dropout)
+
+ self.fc = nn.Linear(self.dim_v, d_model, bias_attr=qkv_bias)
+ self.proj_drop = nn.Dropout(dropout)
+
+ def forward(self, q, k, v, mask=None):
+ batch_size, len_q, _ = q.shape
+ _, len_k, _ = k.shape
+
+ q = self.linear_q(q).reshape([batch_size, len_q, self.n_head, self.d_k])
+ k = self.linear_k(k).reshape([batch_size, len_k, self.n_head, self.d_k])
+ v = self.linear_v(v).reshape([batch_size, len_k, self.n_head, self.d_v])
+
+ q, k, v = q.transpose([0, 2, 1, 3]), k.transpose(
+ [0, 2, 1, 3]), v.transpose([0, 2, 1, 3])
+
+ if mask is not None:
+ if mask.dim() == 3:
+ mask = mask.unsqueeze(1)
+ elif mask.dim() == 2:
+ mask = mask.unsqueeze(1).unsqueeze(1)
+
+ attn_out, _ = self.attention(q, k, v, mask=mask)
+
+ attn_out = attn_out.transpose([0, 2, 1, 3]).reshape(
+ [batch_size, len_q, self.dim_v])
+
+ attn_out = self.fc(attn_out)
+ attn_out = self.proj_drop(attn_out)
+
+ return attn_out
+
+
+class SATRNEncoder(nn.Layer):
+ def __init__(self,
+ n_layers=12,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ n_position=100,
+ d_inner=256,
+ dropout=0.1):
+ super().__init__()
+ self.d_model = d_model
+ self.position_enc = Adaptive2DPositionalEncoding(
+ d_hid=d_model,
+ n_height=n_position,
+ n_width=n_position,
+ dropout=dropout)
+ self.layer_stack = nn.LayerList([
+ SATRNEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def forward(self, feat, valid_ratios=None):
+ """
+ Args:
+ feat (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, T, D_m)`.
+ """
+ if valid_ratios is None:
+ valid_ratios = [1.0 for _ in range(feat.shape[0])]
+ feat = self.position_enc(feat)
+ n, c, h, w = feat.shape
+
+ mask = paddle.zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, :valid_width] = 1
+
+ mask = mask.reshape([n, h * w])
+ feat = feat.reshape([n, c, h * w])
+
+ output = feat.transpose([0, 2, 1])
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, h, w, mask)
+ output = self.layer_norm(output)
+
+ return output
+
+
+class PositionwiseFeedForward(nn.Layer):
+ def __init__(self, d_in, d_hid, dropout=0.1):
+ super().__init__()
+ self.w_1 = nn.Linear(d_in, d_hid)
+ self.w_2 = nn.Linear(d_hid, d_in)
+ self.act = nn.GELU()
+ self.dropout = nn.Dropout(dropout)
+
+ def forward(self, x):
+ x = self.w_1(x)
+ x = self.act(x)
+ x = self.w_2(x)
+ x = self.dropout(x)
+
+ return x
+
+
+class PositionalEncoding(nn.Layer):
+ def __init__(self, d_hid=512, n_position=200, dropout=0):
+ super().__init__()
+ self.dropout = nn.Dropout(p=dropout)
+
+ # Not a parameter
+ # Position table of shape (1, n_position, d_hid)
+ self.register_buffer(
+ 'position_table',
+ self._get_sinusoid_encoding_table(n_position, d_hid))
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = paddle.to_tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.reshape([1, -1])
+ pos_tensor = paddle.cast(
+ paddle.arange(n_position).unsqueeze(-1), 'float32')
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = paddle.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = paddle.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table.unsqueeze(0)
+
+ def forward(self, x):
+
+ x = x + self.position_table[:, :x.shape[1]].clone().detach()
+ return self.dropout(x)
+
+
+class TFDecoderLayer(nn.Layer):
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ operation_order=None):
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.norm3 = nn.LayerNorm(d_model)
+
+ self.self_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.enc_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.mlp = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn')
+ assert self.operation_order in [
+ ('norm', 'self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn', 'norm')
+ ]
+
+ def forward(self,
+ dec_input,
+ enc_output,
+ self_attn_mask=None,
+ dec_enc_attn_mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'enc_dec_attn', 'norm',
+ 'ffn', 'norm'):
+ dec_attn_out = self.self_attn(dec_input, dec_input, dec_input,
+ self_attn_mask)
+ dec_attn_out += dec_input
+ dec_attn_out = self.norm1(dec_attn_out)
+
+ enc_dec_attn_out = self.enc_attn(dec_attn_out, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+ enc_dec_attn_out = self.norm2(enc_dec_attn_out)
+
+ mlp_out = self.mlp(enc_dec_attn_out)
+ mlp_out += enc_dec_attn_out
+ mlp_out = self.norm3(mlp_out)
+ elif self.operation_order == ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn'):
+ dec_input_norm = self.norm1(dec_input)
+ dec_attn_out = self.self_attn(dec_input_norm, dec_input_norm,
+ dec_input_norm, self_attn_mask)
+ dec_attn_out += dec_input
+
+ enc_dec_attn_in = self.norm2(dec_attn_out)
+ enc_dec_attn_out = self.enc_attn(enc_dec_attn_in, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+
+ mlp_out = self.mlp(self.norm3(enc_dec_attn_out))
+ mlp_out += enc_dec_attn_out
+
+ return mlp_out
+
+
+class SATRNDecoder(nn.Layer):
+ def __init__(self,
+ n_layers=6,
+ d_embedding=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ d_inner=256,
+ n_position=200,
+ dropout=0.1,
+ num_classes=93,
+ max_seq_len=40,
+ start_idx=1,
+ padding_idx=92):
+ super().__init__()
+
+ self.padding_idx = padding_idx
+ self.start_idx = start_idx
+ self.max_seq_len = max_seq_len
+
+ self.trg_word_emb = nn.Embedding(
+ num_classes, d_embedding, padding_idx=padding_idx)
+
+ self.position_enc = PositionalEncoding(
+ d_embedding, n_position=n_position)
+ self.dropout = nn.Dropout(p=dropout)
+
+ self.layer_stack = nn.LayerList([
+ TFDecoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-6)
+
+ pred_num_class = num_classes - 1 # ignore padding_idx
+ self.classifier = nn.Linear(d_model, pred_num_class)
+
+ @staticmethod
+ def get_pad_mask(seq, pad_idx):
+
+ return (seq != pad_idx).unsqueeze(-2)
+
+ @staticmethod
+ def get_subsequent_mask(seq):
+ """For masking out the subsequent info."""
+ len_s = seq.shape[1]
+ subsequent_mask = 1 - paddle.triu(
+ paddle.ones((len_s, len_s)), diagonal=1)
+ subsequent_mask = paddle.cast(subsequent_mask.unsqueeze(0), 'bool')
+
+ return subsequent_mask
+
+ def _attention(self, trg_seq, src, src_mask=None):
+ trg_embedding = self.trg_word_emb(trg_seq)
+ trg_pos_encoded = self.position_enc(trg_embedding)
+ tgt = self.dropout(trg_pos_encoded)
+
+ trg_mask = self.get_pad_mask(
+ trg_seq,
+ pad_idx=self.padding_idx) & self.get_subsequent_mask(trg_seq)
+ output = tgt
+ for dec_layer in self.layer_stack:
+ output = dec_layer(
+ output,
+ src,
+ self_attn_mask=trg_mask,
+ dec_enc_attn_mask=src_mask)
+ output = self.layer_norm(output)
+
+ return output
+
+ def _get_mask(self, logit, valid_ratios):
+ N, T, _ = logit.shape
+ mask = None
+ if valid_ratios is not None:
+ mask = paddle.zeros((N, T))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def forward_train(self, feat, out_enc, targets, valid_ratio):
+ src_mask = self._get_mask(out_enc, valid_ratio)
+ attn_output = self._attention(targets, out_enc, src_mask=src_mask)
+ outputs = self.classifier(attn_output)
+
+ return outputs
+
+ def forward_test(self, feat, out_enc, valid_ratio):
+
+ src_mask = self._get_mask(out_enc, valid_ratio)
+ N = out_enc.shape[0]
+ init_target_seq = paddle.full(
+ (N, self.max_seq_len + 1), self.padding_idx, dtype='int64')
+ # bsz * seq_len
+ init_target_seq[:, 0] = self.start_idx
+
+ outputs = []
+ for step in range(0, paddle.to_tensor(self.max_seq_len)):
+ decoder_output = self._attention(
+ init_target_seq, out_enc, src_mask=src_mask)
+ # bsz * seq_len * C
+ step_result = F.softmax(
+ self.classifier(decoder_output[:, step, :]), axis=-1)
+ # bsz * num_classes
+ outputs.append(step_result)
+ step_max_index = paddle.argmax(step_result, axis=-1)
+ init_target_seq[:, step + 1] = step_max_index
+
+ outputs = paddle.stack(outputs, axis=1)
+
+ return outputs
+
+ def forward(self, feat, out_enc, targets=None, valid_ratio=None):
+ if self.training:
+ return self.forward_train(feat, out_enc, targets, valid_ratio)
+ else:
+ return self.forward_test(feat, out_enc, valid_ratio)
+
+
+class SATRNHead(nn.Layer):
+ def __init__(self, enc_cfg, dec_cfg, **kwargs):
+ super(SATRNHead, self).__init__()
+
+ # encoder module
+ self.encoder = SATRNEncoder(**enc_cfg)
+
+ # decoder module
+ self.decoder = SATRNDecoder(**dec_cfg)
+
+ def forward(self, feat, targets=None):
+
+ if targets is not None:
+ targets, valid_ratio = targets
+ else:
+ targets, valid_ratio = None, None
+ holistic_feat = self.encoder(feat, valid_ratio) # bsz c
+
+ final_out = self.decoder(feat, holistic_feat, targets, valid_ratio)
+
+ return final_out
diff --git a/ppocr/modeling/heads/sr_rensnet_transformer.py b/ppocr/modeling/heads/sr_rensnet_transformer.py
index 654f3fca5486229c176246237708c4cf6a8da9ec..df0d0c9299170993fb881714c1f07b618cee9612 100644
--- a/ppocr/modeling/heads/sr_rensnet_transformer.py
+++ b/ppocr/modeling/heads/sr_rensnet_transformer.py
@@ -78,7 +78,7 @@ class MultiHeadedAttention(nn.Layer):
def forward(self, query, key, value, mask=None, attention_map=None):
if mask is not None:
mask = mask.unsqueeze(1)
- nbatches = query.shape[0]
+ nbatches = paddle.shape(query)[0]
query, key, value = \
[paddle.transpose(l(x).reshape([nbatches, -1, self.h, self.d_k]), [0,2,1,3])
diff --git a/ppocr/modeling/necks/db_fpn.py b/ppocr/modeling/necks/db_fpn.py
index 8c3f52a331db5daafab2a38c0a441edd44eb141d..0f5b826bfb023895d6216605e2b2faf82023fa80 100644
--- a/ppocr/modeling/necks/db_fpn.py
+++ b/ppocr/modeling/necks/db_fpn.py
@@ -22,6 +22,7 @@ import paddle.nn.functional as F
from paddle import ParamAttr
import os
import sys
+from ppocr.modeling.necks.intracl import IntraCLBlock
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
@@ -228,6 +229,13 @@ class RSEFPN(nn.Layer):
self.out_channels = out_channels
self.ins_conv = nn.LayerList()
self.inp_conv = nn.LayerList()
+ self.intracl = False
+ if 'intracl' in kwargs.keys() and kwargs['intracl'] is True:
+ self.intracl = kwargs['intracl']
+ self.incl1 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl2 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl3 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl4 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
for i in range(len(in_channels)):
self.ins_conv.append(
@@ -263,6 +271,12 @@ class RSEFPN(nn.Layer):
p3 = self.inp_conv[1](out3)
p2 = self.inp_conv[0](out2)
+ if self.intracl is True:
+ p5 = self.incl4(p5)
+ p4 = self.incl3(p4)
+ p3 = self.incl2(p3)
+ p2 = self.incl1(p2)
+
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
@@ -329,6 +343,14 @@ class LKPAN(nn.Layer):
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False))
+ self.intracl = False
+ if 'intracl' in kwargs.keys() and kwargs['intracl'] is True:
+ self.intracl = kwargs['intracl']
+ self.incl1 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl2 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl3 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+ self.incl4 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
+
def forward(self, x):
c2, c3, c4, c5 = x
@@ -358,6 +380,12 @@ class LKPAN(nn.Layer):
p4 = self.pan_lat_conv[2](pan4)
p5 = self.pan_lat_conv[3](pan5)
+ if self.intracl is True:
+ p5 = self.incl4(p5)
+ p4 = self.incl3(p4)
+ p3 = self.incl2(p3)
+ p2 = self.incl1(p2)
+
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
@@ -424,4 +452,4 @@ class ASFBlock(nn.Layer):
out_list = []
for i in range(self.out_features_num):
out_list.append(attention_scores[:, i:i + 1] * features_list[i])
- return paddle.concat(out_list, axis=1)
+ return paddle.concat(out_list, axis=1)
\ No newline at end of file
diff --git a/ppocr/modeling/necks/intracl.py b/ppocr/modeling/necks/intracl.py
new file mode 100644
index 0000000000000000000000000000000000000000..205b52e35f04e59d35ae6a89bfe1b920a3890d5f
--- /dev/null
+++ b/ppocr/modeling/necks/intracl.py
@@ -0,0 +1,118 @@
+import paddle
+from paddle import nn
+
+# refer from: https://github.com/ViTAE-Transformer/I3CL/blob/736c80237f66d352d488e83b05f3e33c55201317/mmdet/models/detectors/intra_cl_module.py
+
+
+class IntraCLBlock(nn.Layer):
+ def __init__(self, in_channels=96, reduce_factor=4):
+ super(IntraCLBlock, self).__init__()
+ self.channels = in_channels
+ self.rf = reduce_factor
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+ self.conv1x1_reduce_channel = nn.Conv2D(
+ self.channels,
+ self.channels // self.rf,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+ self.conv1x1_return_channel = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ self.v_layer_7x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(7, 1),
+ stride=(1, 1),
+ padding=(3, 0))
+ self.v_layer_5x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(5, 1),
+ stride=(1, 1),
+ padding=(2, 0))
+ self.v_layer_3x1 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(3, 1),
+ stride=(1, 1),
+ padding=(1, 0))
+
+ self.q_layer_1x7 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 7),
+ stride=(1, 1),
+ padding=(0, 3))
+ self.q_layer_1x5 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 5),
+ stride=(1, 1),
+ padding=(0, 2))
+ self.q_layer_1x3 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(1, 3),
+ stride=(1, 1),
+ padding=(0, 1))
+
+ # base
+ self.c_layer_7x7 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(7, 7),
+ stride=(1, 1),
+ padding=(3, 3))
+ self.c_layer_5x5 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(5, 5),
+ stride=(1, 1),
+ padding=(2, 2))
+ self.c_layer_3x3 = nn.Conv2D(
+ self.channels // self.rf,
+ self.channels // self.rf,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=(1, 1))
+
+ self.bn = nn.BatchNorm2D(self.channels)
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ x_new = self.conv1x1_reduce_channel(x)
+
+ x_7_c = self.c_layer_7x7(x_new)
+ x_7_v = self.v_layer_7x1(x_new)
+ x_7_q = self.q_layer_1x7(x_new)
+ x_7 = x_7_c + x_7_v + x_7_q
+
+ x_5_c = self.c_layer_5x5(x_7)
+ x_5_v = self.v_layer_5x1(x_7)
+ x_5_q = self.q_layer_1x5(x_7)
+ x_5 = x_5_c + x_5_v + x_5_q
+
+ x_3_c = self.c_layer_3x3(x_5)
+ x_3_v = self.v_layer_3x1(x_5)
+ x_3_q = self.q_layer_1x3(x_5)
+ x_3 = x_3_c + x_3_v + x_3_q
+
+ x_relation = self.conv1x1_return_channel(x_3)
+
+ x_relation = self.bn(x_relation)
+ x_relation = self.relu(x_relation)
+
+ return x + x_relation
+
+
+def build_intraclblock_list(num_block):
+ IntraCLBlock_list = nn.LayerList()
+ for i in range(num_block):
+ IntraCLBlock_list.append(IntraCLBlock())
+
+ return IntraCLBlock_list
\ No newline at end of file
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index 33be9400b34cb535d260881748e179c3df106caa..a195a6217ae1246316ef441d7f4772ca296914c9 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -47,8 +47,10 @@ class EncoderWithRNN(nn.Layer):
x, _ = self.lstm(x)
return x
+
class BidirectionalLSTM(nn.Layer):
- def __init__(self, input_size,
+ def __init__(self,
+ input_size,
hidden_size,
output_size=None,
num_layers=1,
@@ -58,39 +60,46 @@ class BidirectionalLSTM(nn.Layer):
with_linear=False):
super(BidirectionalLSTM, self).__init__()
self.with_linear = with_linear
- self.rnn = nn.LSTM(input_size,
- hidden_size,
- num_layers=num_layers,
- dropout=dropout,
- direction=direction,
- time_major=time_major)
+ self.rnn = nn.LSTM(
+ input_size,
+ hidden_size,
+ num_layers=num_layers,
+ dropout=dropout,
+ direction=direction,
+ time_major=time_major)
# text recognition the specified structure LSTM with linear
if self.with_linear:
self.linear = nn.Linear(hidden_size * 2, output_size)
def forward(self, input_feature):
- recurrent, _ = self.rnn(input_feature) # batch_size x T x input_size -> batch_size x T x (2*hidden_size)
+ recurrent, _ = self.rnn(
+ input_feature
+ ) # batch_size x T x input_size -> batch_size x T x (2*hidden_size)
if self.with_linear:
- output = self.linear(recurrent) # batch_size x T x output_size
+ output = self.linear(recurrent) # batch_size x T x output_size
return output
return recurrent
+
class EncoderWithCascadeRNN(nn.Layer):
- def __init__(self, in_channels, hidden_size, out_channels, num_layers=2, with_linear=False):
+ def __init__(self,
+ in_channels,
+ hidden_size,
+ out_channels,
+ num_layers=2,
+ with_linear=False):
super(EncoderWithCascadeRNN, self).__init__()
self.out_channels = out_channels[-1]
- self.encoder = nn.LayerList(
- [BidirectionalLSTM(
- in_channels if i == 0 else out_channels[i - 1],
- hidden_size,
- output_size=out_channels[i],
- num_layers=1,
- direction='bidirectional',
- with_linear=with_linear)
- for i in range(num_layers)]
- )
-
+ self.encoder = nn.LayerList([
+ BidirectionalLSTM(
+ in_channels if i == 0 else out_channels[i - 1],
+ hidden_size,
+ output_size=out_channels[i],
+ num_layers=1,
+ direction='bidirectional',
+ with_linear=with_linear) for i in range(num_layers)
+ ])
def forward(self, x):
for i, l in enumerate(self.encoder):
@@ -130,12 +139,17 @@ class EncoderWithSVTR(nn.Layer):
drop_rate=0.1,
attn_drop_rate=0.1,
drop_path=0.,
+ kernel_size=[3, 3],
qk_scale=None):
super(EncoderWithSVTR, self).__init__()
self.depth = depth
self.use_guide = use_guide
self.conv1 = ConvBNLayer(
- in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ in_channels,
+ in_channels // 8,
+ kernel_size=kernel_size,
+ padding=[kernel_size[0] // 2, kernel_size[1] // 2],
+ act=nn.Swish)
self.conv2 = ConvBNLayer(
in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
@@ -161,7 +175,11 @@ class EncoderWithSVTR(nn.Layer):
hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
# last conv-nxn, the input is concat of input tensor and conv3 output tensor
self.conv4 = ConvBNLayer(
- 2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ 2 * in_channels,
+ in_channels // 8,
+ kernel_size=kernel_size,
+ padding=[kernel_size[0] // 2, kernel_size[1] // 2],
+ act=nn.Swish)
self.conv1x1 = ConvBNLayer(
in_channels // 8, dims, kernel_size=1, act=nn.Swish)
diff --git a/ppocr/modeling/transforms/gaspin_transformer.py b/ppocr/modeling/transforms/gaspin_transformer.py
index f4719eb2162a02141620586bcb6a849ae16f3b62..7afa21609336c6914c92b2d7b2b291f7e0fbffdd 100644
--- a/ppocr/modeling/transforms/gaspin_transformer.py
+++ b/ppocr/modeling/transforms/gaspin_transformer.py
@@ -280,5 +280,13 @@ class GA_SPIN_Transformer(nn.Layer):
x = self.sp_net(x, sp_weight, offsets, lambda_color)
if self.stn:
+ is_fp16 = False
+ if build_P_prime_reshape.dtype != paddle.float32:
+ data_type = build_P_prime_reshape.dtype
+ x = x.cast(paddle.float32)
+ build_P_prime_reshape = build_P_prime_reshape.cast(paddle.float32)
+ is_fp16 = True
x = F.grid_sample(x=x, grid=build_P_prime_reshape, padding_mode='border')
+ if is_fp16:
+ x = x.cast(data_type)
return x
diff --git a/ppocr/modeling/transforms/tbsrn.py b/ppocr/modeling/transforms/tbsrn.py
index ee119003600b0515feb6fd1049e2c91565528b7d..e3e77bd36aa1047812a0e41de30a1541c984b2a6 100644
--- a/ppocr/modeling/transforms/tbsrn.py
+++ b/ppocr/modeling/transforms/tbsrn.py
@@ -45,21 +45,24 @@ def positionalencoding2d(d_model, height, width):
pe = paddle.zeros([d_model, height, width])
# Each dimension use half of d_model
d_model = int(d_model / 2)
- div_term = paddle.exp(paddle.arange(0., d_model, 2) *
- -(math.log(10000.0) / d_model))
+ div_term = paddle.exp(
+ paddle.arange(0., d_model, 2, dtype='int64') * -(math.log(10000.0) / d_model))
pos_w = paddle.arange(0., width, dtype='float32').unsqueeze(1)
pos_h = paddle.arange(0., height, dtype='float32').unsqueeze(1)
- pe[0:d_model:2, :, :] = paddle.sin(pos_w * div_term).transpose([1, 0]).unsqueeze(1).tile([1, height, 1])
- pe[1:d_model:2, :, :] = paddle.cos(pos_w * div_term).transpose([1, 0]).unsqueeze(1).tile([1, height, 1])
- pe[d_model::2, :, :] = paddle.sin(pos_h * div_term).transpose([1, 0]).unsqueeze(2).tile([1, 1, width])
- pe[d_model + 1::2, :, :] = paddle.cos(pos_h * div_term).transpose([1, 0]).unsqueeze(2).tile([1, 1, width])
+ pe[0:d_model:2, :, :] = paddle.sin(pos_w * div_term).transpose(
+ [1, 0]).unsqueeze(1).tile([1, height, 1])
+ pe[1:d_model:2, :, :] = paddle.cos(pos_w * div_term).transpose(
+ [1, 0]).unsqueeze(1).tile([1, height, 1])
+ pe[d_model::2, :, :] = paddle.sin(pos_h * div_term).transpose(
+ [1, 0]).unsqueeze(2).tile([1, 1, width])
+ pe[d_model + 1::2, :, :] = paddle.cos(pos_h * div_term).transpose(
+ [1, 0]).unsqueeze(2).tile([1, 1, width])
return pe
class FeatureEnhancer(nn.Layer):
-
def __init__(self):
super(FeatureEnhancer, self).__init__()
@@ -77,13 +80,16 @@ class FeatureEnhancer(nn.Layer):
global_info: (batch, embedding_size, 1, 1)
conv_feature: (batch, channel, H, W)
'''
- batch = conv_feature.shape[0]
- position2d = positionalencoding2d(64, 16, 64).cast('float32').unsqueeze(0).reshape([1, 64, 1024])
+ batch = paddle.shape(conv_feature)[0]
+ position2d = positionalencoding2d(
+ 64, 16, 64).cast('float32').unsqueeze(0).reshape([1, 64, 1024])
position2d = position2d.tile([batch, 1, 1])
- conv_feature = paddle.concat([conv_feature, position2d], 1) # batch, 128(64+64), 32, 128
+ conv_feature = paddle.concat([conv_feature, position2d],
+ 1) # batch, 128(64+64), 32, 128
result = conv_feature.transpose([0, 2, 1])
origin_result = result
- result = self.mul_layernorm1(origin_result + self.multihead(result, result, result, mask=None)[0])
+ result = self.mul_layernorm1(origin_result + self.multihead(
+ result, result, result, mask=None)[0])
origin_result = result
result = self.mul_layernorm3(origin_result + self.pff(result))
result = self.linear(result)
@@ -124,23 +130,35 @@ class TBSRN(nn.Layer):
assert math.log(scale_factor, 2) % 1 == 0
upsample_block_num = int(math.log(scale_factor, 2))
self.block1 = nn.Sequential(
- nn.Conv2D(in_planes, 2 * hidden_units, kernel_size=9, padding=4),
+ nn.Conv2D(
+ in_planes, 2 * hidden_units, kernel_size=9, padding=4),
nn.PReLU()
# nn.ReLU()
)
self.srb_nums = srb_nums
for i in range(srb_nums):
- setattr(self, 'block%d' % (i + 2), RecurrentResidualBlock(2 * hidden_units))
-
- setattr(self, 'block%d' % (srb_nums + 2),
- nn.Sequential(
- nn.Conv2D(2 * hidden_units, 2 * hidden_units, kernel_size=3, padding=1),
- nn.BatchNorm2D(2 * hidden_units)
- ))
+ setattr(self, 'block%d' % (i + 2),
+ RecurrentResidualBlock(2 * hidden_units))
+
+ setattr(
+ self,
+ 'block%d' % (srb_nums + 2),
+ nn.Sequential(
+ nn.Conv2D(
+ 2 * hidden_units,
+ 2 * hidden_units,
+ kernel_size=3,
+ padding=1),
+ nn.BatchNorm2D(2 * hidden_units)))
# self.non_local = NonLocalBlock2D(64, 64)
- block_ = [UpsampleBLock(2 * hidden_units, 2) for _ in range(upsample_block_num)]
- block_.append(nn.Conv2D(2 * hidden_units, in_planes, kernel_size=9, padding=4))
+ block_ = [
+ UpsampleBLock(2 * hidden_units, 2)
+ for _ in range(upsample_block_num)
+ ]
+ block_.append(
+ nn.Conv2D(
+ 2 * hidden_units, in_planes, kernel_size=9, padding=4))
setattr(self, 'block%d' % (srb_nums + 3), nn.Sequential(*block_))
self.tps_inputsize = [height // scale_factor, width // scale_factor]
tps_outputsize = [height // scale_factor, width // scale_factor]
@@ -164,7 +182,8 @@ class TBSRN(nn.Layer):
self.english_dict = {}
for index in range(len(self.english_alphabet)):
self.english_dict[self.english_alphabet[index]] = index
- transformer = Transformer(alphabet='-0123456789abcdefghijklmnopqrstuvwxyz')
+ transformer = Transformer(
+ alphabet='-0123456789abcdefghijklmnopqrstuvwxyz')
self.transformer = transformer
for param in self.transformer.parameters():
param.trainable = False
@@ -219,10 +238,10 @@ class TBSRN(nn.Layer):
# add transformer
label = [str_filt(i, 'lower') + '-' for i in x[2]]
length_tensor, input_tensor, text_gt = self.label_encoder(label)
- hr_pred, word_attention_map_gt, hr_correct_list = self.transformer(hr_img, length_tensor,
- input_tensor)
- sr_pred, word_attention_map_pred, sr_correct_list = self.transformer(sr_img, length_tensor,
- input_tensor)
+ hr_pred, word_attention_map_gt, hr_correct_list = self.transformer(
+ hr_img, length_tensor, input_tensor)
+ sr_pred, word_attention_map_pred, sr_correct_list = self.transformer(
+ sr_img, length_tensor, input_tensor)
output["hr_img"] = hr_img
output["hr_pred"] = hr_pred
output["text_gt"] = text_gt
@@ -257,8 +276,8 @@ class RecurrentResidualBlock(nn.Layer):
residual = self.conv2(residual)
residual = self.bn2(residual)
- size = residual.shape
+ size = paddle.shape(residual)
residual = residual.reshape([size[0], size[1], -1])
residual = self.feature_enhancer(residual)
residual = residual.reshape([size[0], size[1], size[2], size[3]])
- return x + residual
\ No newline at end of file
+ return x + residual
diff --git a/ppocr/modeling/transforms/tps.py b/ppocr/modeling/transforms/tps.py
index 9bdab0f85112b90d8da959dce4e258188a812052..ac5ce998b00c92042517f48b3bed81756c230b51 100644
--- a/ppocr/modeling/transforms/tps.py
+++ b/ppocr/modeling/transforms/tps.py
@@ -304,5 +304,14 @@ class TPS(nn.Layer):
batch_P_prime = self.grid_generator(batch_C_prime, image.shape[2:])
batch_P_prime = batch_P_prime.reshape(
[-1, image.shape[2], image.shape[3], 2])
+ is_fp16 = False
+ if batch_P_prime.dtype != paddle.float32:
+ data_type = batch_P_prime.dtype
+ image = image.cast(paddle.float32)
+ batch_P_prime = batch_P_prime.cast(paddle.float32)
+ is_fp16 = True
batch_I_r = F.grid_sample(x=image, grid=batch_P_prime)
+ if is_fp16:
+ batch_I_r = batch_I_r.cast(data_type)
+
return batch_I_r
diff --git a/ppocr/modeling/transforms/tps_spatial_transformer.py b/ppocr/modeling/transforms/tps_spatial_transformer.py
index e7ec2c848f192d766722f824962a7f8d0fed41f9..35b1d8bf7164a1a0dd6e5905dc0c91112008c3e0 100644
--- a/ppocr/modeling/transforms/tps_spatial_transformer.py
+++ b/ppocr/modeling/transforms/tps_spatial_transformer.py
@@ -29,12 +29,28 @@ import itertools
def grid_sample(input, grid, canvas=None):
input.stop_gradient = False
+
+ is_fp16 = False
+ if grid.dtype != paddle.float32:
+ data_type = grid.dtype
+ input = input.cast(paddle.float32)
+ grid = grid.cast(paddle.float32)
+ is_fp16 = True
output = F.grid_sample(input, grid)
+ if is_fp16:
+ output = output.cast(data_type)
+ grid = grid.cast(data_type)
+
if canvas is None:
return output
else:
input_mask = paddle.ones(shape=input.shape)
+ if is_fp16:
+ input_mask = input_mask.cast(paddle.float32)
+ grid = grid.cast(paddle.float32)
output_mask = F.grid_sample(input_mask, grid)
+ if is_fp16:
+ output_mask = output_mask.cast(data_type)
padded_output = output * output_mask + canvas * (1 - output_mask)
return padded_output
@@ -140,7 +156,9 @@ class TPSSpatialTransformer(nn.Layer):
padding_matrix = paddle.expand(
self.padding_matrix, shape=[batch_size, 3, 2])
- Y = paddle.concat([source_control_points, padding_matrix], 1)
+ Y = paddle.concat([
+ source_control_points.astype(padding_matrix.dtype), padding_matrix
+ ], 1)
mapping_matrix = paddle.matmul(self.inverse_kernel, Y)
source_coordinate = paddle.matmul(self.target_coordinate_repr,
mapping_matrix)
@@ -153,4 +171,4 @@ class TPSSpatialTransformer(nn.Layer):
# the input to grid_sample is normalized [-1, 1], but what we get is [0, 1]
grid = 2.0 * grid - 1.0
output_maps = grid_sample(input, grid, canvas=None)
- return output_maps, source_coordinate
\ No newline at end of file
+ return output_maps, source_coordinate
diff --git a/ppocr/optimizer/optimizer.py b/ppocr/optimizer/optimizer.py
index 144f011c79ec2303b7fbc73ac078afe3ce92c255..ffe72d7db309ab832a258dcc73916f9fa4485c2b 100644
--- a/ppocr/optimizer/optimizer.py
+++ b/ppocr/optimizer/optimizer.py
@@ -84,8 +84,7 @@ class Adam(object):
if self.group_lr:
if self.training_step == 'LF_2':
import paddle
- if isinstance(model, paddle.fluid.dygraph.parallel.
- DataParallel): # multi gpu
+ if isinstance(model, paddle.DataParallel): # multi gpu
mlm = model._layers.head.MLM_VRM.MLM.parameters()
pre_mlm_pp = model._layers.head.MLM_VRM.Prediction.pp_share.parameters(
)
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index 36a3152f2f2d68ed0884bd415844d209d850f5ca..c89345e70b3dcf22b292ebf1250bf3f258a3355c 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -28,7 +28,7 @@ from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, NRTRLabelDecode, SARLabelDecode, \
SEEDLabelDecode, PRENLabelDecode, ViTSTRLabelDecode, ABINetLabelDecode, \
- SPINLabelDecode, VLLabelDecode, RFLLabelDecode
+ SPINLabelDecode, VLLabelDecode, RFLLabelDecode, SATRNLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess, DistillationSerPostProcess
@@ -52,7 +52,8 @@ def build_post_process(config, global_config=None):
'TableMasterLabelDecode', 'SPINLabelDecode',
'DistillationSerPostProcess', 'DistillationRePostProcess',
'VLLabelDecode', 'PicoDetPostProcess', 'CTPostProcess',
- 'RFLLabelDecode', 'DRRGPostprocess', 'CANLabelDecode'
+ 'RFLLabelDecode', 'DRRGPostprocess', 'CANLabelDecode',
+ 'SATRNLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/db_postprocess.py b/ppocr/postprocess/db_postprocess.py
index dfe107816c195b36bf06568843b008bf66ff24c7..244825b76a47162419b4ae68103b182331be1791 100755
--- a/ppocr/postprocess/db_postprocess.py
+++ b/ppocr/postprocess/db_postprocess.py
@@ -144,9 +144,9 @@ class DBPostProcess(object):
np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(
np.round(box[:, 1] / height * dest_height), 0, dest_height)
- boxes.append(box.astype(np.int16))
+ boxes.append(box.astype("int32"))
scores.append(score)
- return np.array(boxes, dtype=np.int16), scores
+ return np.array(boxes, dtype="int32"), scores
def unclip(self, box, unclip_ratio):
poly = Polygon(box)
@@ -185,15 +185,15 @@ class DBPostProcess(object):
'''
h, w = bitmap.shape[:2]
box = _box.copy()
- xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
- xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
- ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
- ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
+ xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
- cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
def box_score_slow(self, bitmap, contour):
@@ -214,7 +214,7 @@ class DBPostProcess(object):
contour[:, 0] = contour[:, 0] - xmin
contour[:, 1] = contour[:, 1] - ymin
- cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
+ cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
def __call__(self, outs_dict, shape_list):
diff --git a/ppocr/postprocess/drrg_postprocess.py b/ppocr/postprocess/drrg_postprocess.py
index 353081c9d4d0fa1d04d995c84445445767276cc8..56fd034f7c18ee31e8af6c5c72461bcd98021809 100644
--- a/ppocr/postprocess/drrg_postprocess.py
+++ b/ppocr/postprocess/drrg_postprocess.py
@@ -68,7 +68,7 @@ def graph_propagation(edges, scores, text_comps, edge_len_thr=50.):
score_dict[edge[0], edge[1]] = scores[i]
nodes = np.sort(np.unique(edges.flatten()))
- mapping = -1 * np.ones((np.max(nodes) + 1), dtype=np.int)
+ mapping = -1 * np.ones((np.max(nodes) + 1), dtype=np.int32)
mapping[nodes] = np.arange(nodes.shape[0])
order_inds = mapping[edges]
vertices = [Node(node) for node in nodes]
@@ -93,9 +93,8 @@ def connected_components(nodes, score_dict, link_thr):
while node_queue:
node = node_queue.pop(0)
neighbors = set([
- neighbor for neighbor in node.links
- if score_dict[tuple(sorted([node.ind, neighbor.ind]))] >=
- link_thr
+ neighbor for neighbor in node.links if
+ score_dict[tuple(sorted([node.ind, neighbor.ind]))] >= link_thr
])
neighbors.difference_update(cluster)
nodes.difference_update(neighbors)
diff --git a/ppocr/postprocess/east_postprocess.py b/ppocr/postprocess/east_postprocess.py
index c194c81c6911aac0f9210109c37b76b44532e9c4..c1af3eccef84d0044c7962094b85ad5f4399e09e 100755
--- a/ppocr/postprocess/east_postprocess.py
+++ b/ppocr/postprocess/east_postprocess.py
@@ -22,6 +22,7 @@ import cv2
import paddle
import os
+from ppocr.utils.utility import check_install
import sys
@@ -78,11 +79,12 @@ class EASTPostProcess(object):
boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
try:
+ check_install('lanms', 'lanms-nova')
import lanms
boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)
except:
print(
- 'you should install lanms by pip3 install lanms-nova to speed up nms_locality'
+ 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'
)
boxes = nms_locality(boxes.astype(np.float64), nms_thresh)
if boxes.shape[0] == 0:
diff --git a/ppocr/postprocess/fce_postprocess.py b/ppocr/postprocess/fce_postprocess.py
index 8e0716f9f2f3a7cb585fa40a2e2a27aecb606a9b..959f86efa4c3180a1fe4e6e2115bbf32966a7f09 100755
--- a/ppocr/postprocess/fce_postprocess.py
+++ b/ppocr/postprocess/fce_postprocess.py
@@ -31,7 +31,7 @@ def fill_hole(input_mask):
mask = np.zeros((h + 4, w + 4), np.uint8)
cv2.floodFill(canvas, mask, (0, 0), 1)
- canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool_)
return ~canvas | input_mask
@@ -234,7 +234,7 @@ class FCEPostProcess(object):
poly = np.array(boundary[:-1]).reshape(-1, 2).astype(np.float32)
score = boundary[-1]
points = cv2.boxPoints(cv2.minAreaRect(poly))
- points = np.int0(points)
+ points = np.int64(points)
new_boundaries.append(points.reshape(-1).tolist() + [score])
boundaries = new_boundaries
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index fbf8b93e3d11121c99ce5b2dcbf2149e15453d4a..ce2e9f8b579f2e2fb6d25390db71eb4e45ddeef3 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -67,7 +67,66 @@ class BaseRecLabelDecode(object):
def add_special_char(self, dict_character):
return dict_character
- def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
+ def get_word_info(self, text, selection):
+ """
+ Group the decoded characters and record the corresponding decoded positions.
+
+ Args:
+ text: the decoded text
+ selection: the bool array that identifies which columns of features are decoded as non-separated characters
+ Returns:
+ word_list: list of the grouped words
+ word_col_list: list of decoding positions corresponding to each character in the grouped word
+ state_list: list of marker to identify the type of grouping words, including two types of grouping words:
+ - 'cn': continous chinese characters (e.g., 你好啊)
+ - 'en&num': continous english characters (e.g., hello), number (e.g., 123, 1.123), or mixed of them connected by '-' (e.g., VGG-16)
+ The remaining characters in text are treated as separators between groups (e.g., space, '(', ')', etc.).
+ """
+ state = None
+ word_content = []
+ word_col_content = []
+ word_list = []
+ word_col_list = []
+ state_list = []
+ valid_col = np.where(selection==True)[0]
+
+ for c_i, char in enumerate(text):
+ if '\u4e00' <= char <= '\u9fff':
+ c_state = 'cn'
+ elif bool(re.search('[a-zA-Z0-9]', char)):
+ c_state = 'en&num'
+ else:
+ c_state = 'splitter'
+
+ if char == '.' and state == 'en&num' and c_i + 1 < len(text) and bool(re.search('[0-9]', text[c_i+1])): # grouping floting number
+ c_state = 'en&num'
+ if char == '-' and state == "en&num": # grouping word with '-', such as 'state-of-the-art'
+ c_state = 'en&num'
+
+ if state == None:
+ state = c_state
+
+ if state != c_state:
+ if len(word_content) != 0:
+ word_list.append(word_content)
+ word_col_list.append(word_col_content)
+ state_list.append(state)
+ word_content = []
+ word_col_content = []
+ state = c_state
+
+ if state != "splitter":
+ word_content.append(char)
+ word_col_content.append(valid_col[c_i])
+
+ if len(word_content) != 0:
+ word_list.append(word_content)
+ word_col_list.append(word_col_content)
+ state_list.append(state)
+
+ return word_list, word_col_list, state_list
+
+ def decode(self, text_index, text_prob=None, is_remove_duplicate=False, return_word_box=False):
""" convert text-index into text-label. """
result_list = []
ignored_tokens = self.get_ignored_tokens()
@@ -95,8 +154,12 @@ class BaseRecLabelDecode(object):
if self.reverse: # for arabic rec
text = self.pred_reverse(text)
-
- result_list.append((text, np.mean(conf_list).tolist()))
+
+ if return_word_box:
+ word_list, word_col_list, state_list = self.get_word_info(text, selection)
+ result_list.append((text, np.mean(conf_list).tolist(), [len(text_index[batch_idx]), word_list, word_col_list, state_list]))
+ else:
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def get_ignored_tokens(self):
@@ -111,14 +174,19 @@ class CTCLabelDecode(BaseRecLabelDecode):
super(CTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
- def __call__(self, preds, label=None, *args, **kwargs):
+ def __call__(self, preds, label=None, return_word_box=False, *args, **kwargs):
if isinstance(preds, tuple) or isinstance(preds, list):
preds = preds[-1]
if isinstance(preds, paddle.Tensor):
preds = preds.numpy()
preds_idx = preds.argmax(axis=2)
preds_prob = preds.max(axis=2)
- text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True, return_word_box=return_word_box)
+ if return_word_box:
+ for rec_idx, rec in enumerate(text):
+ wh_ratio = kwargs['wh_ratio_list'][rec_idx]
+ max_wh_ratio = kwargs['max_wh_ratio']
+ rec[2][0] = rec[2][0]*(wh_ratio/max_wh_ratio)
if label is None:
return text
label = self.decode(label)
@@ -568,6 +636,82 @@ class SARLabelDecode(BaseRecLabelDecode):
return [self.padding_idx]
+class SATRNLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(SATRNLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ self.rm_symbol = kwargs.get('rm_symbol', False)
+
+ def add_special_char(self, dict_character):
+ beg_end_str = ""
+ unknown_str = ""
+ padding_str = ""
+ dict_character = dict_character + [unknown_str]
+ self.unknown_idx = len(dict_character) - 1
+ dict_character = dict_character + [beg_end_str]
+ self.start_idx = len(dict_character) - 1
+ self.end_idx = len(dict_character) - 1
+ dict_character = dict_character + [padding_str]
+ self.padding_idx = len(dict_character) - 1
+ return dict_character
+
+ def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
+ """ convert text-index into text-label. """
+ result_list = []
+ ignored_tokens = self.get_ignored_tokens()
+
+ batch_size = len(text_index)
+ for batch_idx in range(batch_size):
+ char_list = []
+ conf_list = []
+ for idx in range(len(text_index[batch_idx])):
+ if text_index[batch_idx][idx] in ignored_tokens:
+ continue
+ if int(text_index[batch_idx][idx]) == int(self.end_idx):
+ if text_prob is None and idx == 0:
+ continue
+ else:
+ break
+ if is_remove_duplicate:
+ # only for predict
+ if idx > 0 and text_index[batch_idx][idx - 1] == text_index[
+ batch_idx][idx]:
+ continue
+ char_list.append(self.character[int(text_index[batch_idx][
+ idx])])
+ if text_prob is not None:
+ conf_list.append(text_prob[batch_idx][idx])
+ else:
+ conf_list.append(1)
+ text = ''.join(char_list)
+ if self.rm_symbol:
+ comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
+ text = text.lower()
+ text = comp.sub('', text)
+ result_list.append((text, np.mean(conf_list).tolist()))
+ return result_list
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=2)
+ preds_prob = preds.max(axis=2)
+
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+
+ if label is None:
+ return text
+ label = self.decode(label, is_remove_duplicate=False)
+ return text, label
+
+ def get_ignored_tokens(self):
+ return [self.padding_idx]
+
+
class DistillationSARLabelDecode(SARLabelDecode):
"""
Convert
@@ -723,7 +867,7 @@ class NRTRLabelDecode(BaseRecLabelDecode):
else:
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text.lower(), np.mean(conf_list).tolist()))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
@@ -891,7 +1035,7 @@ class VLLabelDecode(BaseRecLabelDecode):
) + length[i])].topk(1)[0][:, 0]
preds_prob = paddle.exp(
paddle.log(preds_prob).sum() / (preds_prob.shape[0] + 1e-6))
- text.append((preds_text, preds_prob.numpy()[0]))
+ text.append((preds_text, float(preds_prob)))
if label is None:
return text
label = self.decode(label)
diff --git a/ppocr/postprocess/sast_postprocess.py b/ppocr/postprocess/sast_postprocess.py
index bee75c05b1a3ea59193d566f91378c96797f533b..594bf17d6a0db2ebee17e7476834ce7b6b4289e6 100755
--- a/ppocr/postprocess/sast_postprocess.py
+++ b/ppocr/postprocess/sast_postprocess.py
@@ -141,6 +141,8 @@ class SASTPostProcess(object):
def nms(self, dets):
if self.is_python35:
+ from ppocr.utils.utility import check_install
+ check_install('lanms', 'lanms-nova')
import lanms
dets = lanms.merge_quadrangle_n9(dets, self.nms_thresh)
else:
diff --git a/ppocr/utils/e2e_metric/Deteval.py b/ppocr/utils/e2e_metric/Deteval.py
index 6ce56eda2aa9f38fdc712d49ae64945c558b418d..c2a4383eed38acc4e4c7effea2aa688007a0c24a 100755
--- a/ppocr/utils/e2e_metric/Deteval.py
+++ b/ppocr/utils/e2e_metric/Deteval.py
@@ -15,7 +15,9 @@
import json
import numpy as np
import scipy.io as io
-import Polygon as plg
+
+from ppocr.utils.utility import check_install
+
from ppocr.utils.e2e_metric.polygon_fast import iod, area_of_intersection, area
@@ -275,6 +277,8 @@ def get_score_C(gt_label, text, pred_bboxes):
"""
get score for CentripetalText (CT) prediction.
"""
+ check_install("Polygon", "Polygon3")
+ import Polygon as plg
def gt_reading_mod(gt_label, text):
"""This helper reads groundtruths from mat files"""
diff --git a/ppocr/utils/gen_label.py b/ppocr/utils/gen_label.py
index fb78bd38bcfc1a59cac48a28bbb655ecb83bcb3f..56d75544dbee596a87343c90320b0ea3178e6b28 100644
--- a/ppocr/utils/gen_label.py
+++ b/ppocr/utils/gen_label.py
@@ -29,7 +29,7 @@ def gen_rec_label(input_path, out_label):
def gen_det_label(root_path, input_dir, out_label):
with open(out_label, 'w') as out_file:
for label_file in os.listdir(input_dir):
- img_path = root_path + label_file[3:-4] + ".jpg"
+ img_path = os.path.join(root_path, label_file[3:-4] + ".jpg")
label = []
with open(
os.path.join(input_dir, label_file), 'r',
diff --git a/ppocr/utils/network.py b/ppocr/utils/network.py
index 080a5d160116cfdd3b255a883525281d97ee9cc9..f2cd690e12fd06f2749320f1319fde9de8ebe18d 100644
--- a/ppocr/utils/network.py
+++ b/ppocr/utils/network.py
@@ -20,6 +20,8 @@ from tqdm import tqdm
from ppocr.utils.logging import get_logger
+MODELS_DIR = os.path.expanduser("~/.paddleocr/models/")
+
def download_with_progressbar(url, save_path):
logger = get_logger()
@@ -67,6 +69,18 @@ def maybe_download(model_storage_directory, url):
os.remove(tmp_path)
+def maybe_download_params(model_path):
+ if os.path.exists(model_path) or not is_link(model_path):
+ return model_path
+ else:
+ url = model_path
+ tmp_path = os.path.join(MODELS_DIR, url.split('/')[-1])
+ print('download {} to {}'.format(url, tmp_path))
+ os.makedirs(MODELS_DIR, exist_ok=True)
+ download_with_progressbar(url, tmp_path)
+ return tmp_path
+
+
def is_link(s):
return s is not None and s.startswith('http')
diff --git a/ppocr/utils/profiler.py b/ppocr/utils/profiler.py
index c4e28bc6bea9ca912a0786d879a48ec0349e7698..629ef4ef054a050afd1bc0ce819cb664b9503e9f 100644
--- a/ppocr/utils/profiler.py
+++ b/ppocr/utils/profiler.py
@@ -13,7 +13,7 @@
# limitations under the License.
import sys
-import paddle
+import paddle.profiler as profiler
# A global variable to record the number of calling times for profiler
# functions. It is used to specify the tracing range of training steps.
@@ -21,7 +21,7 @@ _profiler_step_id = 0
# A global variable to avoid parsing from string every time.
_profiler_options = None
-
+_prof = None
class ProfilerOptions(object):
'''
@@ -31,6 +31,7 @@ class ProfilerOptions(object):
"profile_path=model.profile"
"batch_range=[50, 60]; profile_path=model.profile"
"batch_range=[50, 60]; tracer_option=OpDetail; profile_path=model.profile"
+
ProfilerOptions supports following key-value pair:
batch_range - a integer list, e.g. [100, 110].
state - a string, the optional values are 'CPU', 'GPU' or 'All'.
@@ -52,7 +53,8 @@ class ProfilerOptions(object):
'sorted_key': 'total',
'tracer_option': 'Default',
'profile_path': '/tmp/profile',
- 'exit_on_finished': True
+ 'exit_on_finished': True,
+ 'timer_only': True
}
self._parse_from_string(options_str)
@@ -71,6 +73,8 @@ class ProfilerOptions(object):
'state', 'sorted_key', 'tracer_option', 'profile_path'
]:
self._options[key] = value
+ elif key == 'timer_only':
+ self._options[key] = value
def __getitem__(self, name):
if self._options.get(name, None) is None:
@@ -84,7 +88,6 @@ def add_profiler_step(options_str=None):
Enable the operator-level timing using PaddlePaddle's profiler.
The profiler uses a independent variable to count the profiler steps.
One call of this function is treated as a profiler step.
-
Args:
profiler_options - a string to initialize the ProfilerOptions.
Default is None, and the profiler is disabled.
@@ -92,18 +95,33 @@ def add_profiler_step(options_str=None):
if options_str is None:
return
+ global _prof
global _profiler_step_id
global _profiler_options
if _profiler_options is None:
_profiler_options = ProfilerOptions(options_str)
-
- if _profiler_step_id == _profiler_options['batch_range'][0]:
- paddle.utils.profiler.start_profiler(
- _profiler_options['state'], _profiler_options['tracer_option'])
- elif _profiler_step_id == _profiler_options['batch_range'][1]:
- paddle.utils.profiler.stop_profiler(_profiler_options['sorted_key'],
- _profiler_options['profile_path'])
+ # profile : https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/performance_improving/profiling_model.html#chakanxingnengshujudetongjibiaodan
+ # timer_only = True only the model's throughput and time overhead are displayed
+ # timer_only = False calling summary can print a statistical form that presents performance data from different perspectives.
+ # timer_only = False the output Timeline information can be found in the profiler_log directory
+ if _prof is None:
+ _timer_only = str(_profiler_options['timer_only']) == str(True)
+ _prof = profiler.Profiler(
+ scheduler = (_profiler_options['batch_range'][0], _profiler_options['batch_range'][1]),
+ on_trace_ready = profiler.export_chrome_tracing('./profiler_log'),
+ timer_only = _timer_only)
+ _prof.start()
+ else:
+ _prof.step()
+
+ if _profiler_step_id == _profiler_options['batch_range'][1]:
+ _prof.stop()
+ _prof.summary(
+ op_detail=True,
+ thread_sep=False,
+ time_unit='ms')
+ _prof = None
if _profiler_options['exit_on_finished']:
sys.exit(0)
diff --git a/ppocr/utils/save_load.py b/ppocr/utils/save_load.py
index aa65f290c0a5f4f13b3103fb4404815e2ae74a88..e6a81c48dfd43245f13f69e1a5679d08838ca603 100644
--- a/ppocr/utils/save_load.py
+++ b/ppocr/utils/save_load.py
@@ -24,6 +24,7 @@ import six
import paddle
from ppocr.utils.logging import get_logger
+from ppocr.utils.network import maybe_download_params
__all__ = ['load_model']
@@ -145,6 +146,7 @@ def load_model(config, model, optimizer=None, model_type='det'):
def load_pretrained_params(model, path):
logger = get_logger()
+ path = maybe_download_params(path)
if path.endswith('.pdparams'):
path = path.replace('.pdparams', '')
assert os.path.exists(path + ".pdparams"), \
@@ -195,13 +197,26 @@ def save_model(model,
"""
_mkdir_if_not_exist(model_path, logger)
model_prefix = os.path.join(model_path, prefix)
+
+ if prefix == 'best_accuracy':
+ best_model_path = os.path.join(model_path, 'best_model')
+ _mkdir_if_not_exist(best_model_path, logger)
+
paddle.save(optimizer.state_dict(), model_prefix + '.pdopt')
+ if prefix == 'best_accuracy':
+ paddle.save(optimizer.state_dict(),
+ os.path.join(best_model_path, 'model.pdopt'))
is_nlp_model = config['Architecture']["model_type"] == 'kie' and config[
"Architecture"]["algorithm"] not in ["SDMGR"]
if is_nlp_model is not True:
paddle.save(model.state_dict(), model_prefix + '.pdparams')
metric_prefix = model_prefix
+
+ if prefix == 'best_accuracy':
+ paddle.save(model.state_dict(),
+ os.path.join(best_model_path, 'model.pdparams'))
+
else: # for kie system, we follow the save/load rules in NLP
if config['Global']['distributed']:
arch = model._layers
@@ -211,6 +226,10 @@ def save_model(model,
arch = arch.Student
arch.backbone.model.save_pretrained(model_prefix)
metric_prefix = os.path.join(model_prefix, 'metric')
+
+ if prefix == 'best_accuracy':
+ arch.backbone.model.save_pretrained(best_model_path)
+
# save metric and config
with open(metric_prefix + '.states', 'wb') as f:
pickle.dump(kwargs, f, protocol=2)
diff --git a/ppocr/utils/utility.py b/ppocr/utils/utility.py
index 18357c8e97bcea8ee321856a87146a4a7b901469..f788e79cd53a24d4d7f979f359cacd0532a1ff05 100755
--- a/ppocr/utils/utility.py
+++ b/ppocr/utils/utility.py
@@ -19,6 +19,9 @@ import cv2
import random
import numpy as np
import paddle
+import importlib.util
+import sys
+import subprocess
def print_dict(d, logger, delimiter=0):
@@ -72,6 +75,25 @@ def get_image_file_list(img_file):
imgs_lists = sorted(imgs_lists)
return imgs_lists
+def binarize_img(img):
+ if len(img.shape) == 3 and img.shape[2] == 3:
+ gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # conversion to grayscale image
+ # use cv2 threshold binarization
+ _, gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
+ img = cv2.cvtColor(gray, cv2.COLOR_GRAY2BGR)
+ return img
+
+def alpha_to_color(img, alpha_color=(255, 255, 255)):
+ if len(img.shape) == 3 and img.shape[2] == 4:
+ B, G, R, A = cv2.split(img)
+ alpha = A / 255
+
+ R = (alpha_color[0] * (1 - alpha) + R * alpha).astype(np.uint8)
+ G = (alpha_color[1] * (1 - alpha) + G * alpha).astype(np.uint8)
+ B = (alpha_color[2] * (1 - alpha) + B * alpha).astype(np.uint8)
+
+ img = cv2.merge((B, G, R))
+ return img
def check_and_read(img_path):
if os.path.basename(img_path)[-3:] in ['gif', 'GIF']:
@@ -131,6 +153,26 @@ def set_seed(seed=1024):
paddle.seed(seed)
+def check_install(module_name, install_name):
+ spec = importlib.util.find_spec(module_name)
+ if spec is None:
+ print(f'Warnning! The {module_name} module is NOT installed')
+ print(
+ f'Try install {module_name} module automatically. You can also try to install manually by pip install {install_name}.'
+ )
+ python = sys.executable
+ try:
+ subprocess.check_call(
+ [python, '-m', 'pip', 'install', install_name],
+ stdout=subprocess.DEVNULL)
+ print(f'The {module_name} module is now installed')
+ except subprocess.CalledProcessError as exc:
+ raise Exception(
+ f"Install {module_name} failed, please install manually")
+ else:
+ print(f"{module_name} has been installed.")
+
+
class AverageMeter:
def __init__(self):
self.reset()
diff --git a/ppocr/utils/visual.py b/ppocr/utils/visual.py
index b6de446593984788bea5c03026f4a5b8c0187909..9108a3728143e0ef0a0d6705e4cc701ab9588394 100644
--- a/ppocr/utils/visual.py
+++ b/ppocr/utils/visual.py
@@ -14,6 +14,7 @@
import cv2
import os
import numpy as np
+import PIL
from PIL import Image, ImageDraw, ImageFont
@@ -62,8 +63,13 @@ def draw_box_txt(bbox, text, draw, font, font_size, color):
draw.rectangle(bbox, fill=color)
# draw ocr results
- tw = font.getsize(text)[0]
- th = font.getsize(text)[1]
+ if int(PIL.__version__.split('.')[0]) < 10:
+ tw = font.getsize(text)[0]
+ th = font.getsize(text)[1]
+ else:
+ left, top, right, bottom = font.getbbox(text)
+ tw, th = right - left, bottom - top
+
start_y = max(0, bbox[0][1] - th)
draw.rectangle(
[(bbox[0][0] + 1, start_y), (bbox[0][0] + tw + 1, start_y + th)],
diff --git a/ppstructure/docs/quickstart_en.md b/ppstructure/docs/quickstart_en.md
index 9229a79de1f14ea738a4ca2b93cf44d48508ff40..bbaac342fdfdb797c9f0f6b8b343713c5afb970f 100644
--- a/ppstructure/docs/quickstart_en.md
+++ b/ppstructure/docs/quickstart_en.md
@@ -311,7 +311,7 @@ Please refer to: [Key Information Extraction](../kie/README.md) .
| save_pdf | Whether to convert docx to pdf when recovery| False |
| structure_version | Structure version, optional PP-structure and PP-structurev2 | PP-structure |
-Most of the parameters are consistent with the PaddleOCR whl package, see [whl package documentation](../../doc/doc_en/whl.md)
+Most of the parameters are consistent with the PaddleOCR whl package, see [whl package documentation](../../doc/doc_en/whl_en.md)
## 3. Summary
diff --git a/ppstructure/kie/README.md b/ppstructure/kie/README.md
index 872edb959276e22b22e4b733df44bdb6a6819c98..6717aa0c8c349da717b3fd01d9ae209b15eae026 100644
--- a/ppstructure/kie/README.md
+++ b/ppstructure/kie/README.md
@@ -89,7 +89,7 @@ Boxes of different colors in the image represent different categories.
The invoice and application form images have three categories: `request`, `answer` and `header`. The `question` and 'answer' can be used to extract the relationship.
-For the ID card image, the mdoel can be directly identify the key information such as `name`, `gender`, `nationality`, so that the subsequent relationship extraction process is not required, and the key information extraction task can be completed using only on model.
+For the ID card image, the model can directly identify the key information such as `name`, `gender`, `nationality`, so that the subsequent relationship extraction process is not required, and the key information extraction task can be completed using only on model.
### 3.2 RE
@@ -186,6 +186,10 @@ python3 ./tools/infer_kie_token_ser_re.py \
The visual result images and the predicted text file will be saved in the `Global.save_res_path` directory.
+If you want to use a custom ocr model, you can set it through the following fields
+- `Global.kie_det_model_dir`: the detection inference model path
+- `Global.kie_rec_model_dir`: the recognition inference model path
+
If you want to load the text detection and recognition results collected before, you can use the following command to predict.
@@ -257,6 +261,9 @@ python3 kie/predict_kie_token_ser_re.py \
The visual results and text file will be saved in directory `output`.
+If you want to use a custom ocr model, you can set it through the following fields
+- `--det_model_dir`: the detection inference model path
+- `--rec_model_dir`: the recognition inference model path
### 4.3 More
diff --git a/ppstructure/kie/README_ch.md b/ppstructure/kie/README_ch.md
index 7a8b1942b1849834f8843c8f272ce08e95f4b993..2efb49fd9622e767bbb8696e946bb05dcf72781f 100644
--- a/ppstructure/kie/README_ch.md
+++ b/ppstructure/kie/README_ch.md
@@ -170,6 +170,10 @@ python3 ./tools/infer_kie_token_ser_re.py \
`Global.save_res_path`目录中会保存可视化的结果图像以及预测的文本文件。
+如果想使用自定义OCR模型,可通过如下字段进行设置
+- `Global.kie_det_model_dir`: 设置检测inference模型地址
+- `Global.kie_rec_model_dir`: 设置识别inference模型地址
+
如果希望加载标注好的文本检测与识别结果,仅预测可以使用下面的命令进行预测。
@@ -239,6 +243,9 @@ python3 kie/predict_kie_token_ser_re.py \
可视化结果保存在`output`目录下。
+如果想使用自定义OCR模型,可通过如下字段进行设置
+- `--det_model_dir`: 设置检测inference模型地址
+- `--rec_model_dir`: 设置识别inference模型地址
### 4.3 更多
diff --git a/ppstructure/kie/requirements.txt b/ppstructure/kie/requirements.txt
index 6cfcba764190fd46f98b76c27e93db6f4fa36c45..61c230d3ed5bedc093c40af8228d3ea685382f54 100644
--- a/ppstructure/kie/requirements.txt
+++ b/ppstructure/kie/requirements.txt
@@ -2,6 +2,6 @@ sentencepiece
yacs
seqeval
pypandoc
-attrdict
+attrdict3
python_docx
paddlenlp>=2.4.1
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index bb061c998f6f8b16c06f9ee94299af0f59c53eb2..b8b871689c919097e480f726a402da1c54873df0 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -34,7 +34,7 @@ from ppocr.utils.visual import draw_ser_results, draw_re_results
from tools.infer.predict_system import TextSystem
from ppstructure.layout.predict_layout import LayoutPredictor
from ppstructure.table.predict_table import TableSystem, to_excel
-from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.utility import parse_args, draw_structure_result, cal_ocr_word_box
logger = get_logger()
@@ -79,6 +79,8 @@ class StructureSystem(object):
from ppstructure.kie.predict_kie_token_ser_re import SerRePredictor
self.kie_predictor = SerRePredictor(args)
+ self.return_word_box = args.return_word_box
+
def __call__(self, img, return_ocr_result_in_table=False, img_idx=0):
time_dict = {
'image_orientation': 0,
@@ -156,17 +158,27 @@ class StructureSystem(object):
]
res = []
for box, rec_res in zip(filter_boxes, filter_rec_res):
- rec_str, rec_conf = rec_res
+ rec_str, rec_conf = rec_res[0], rec_res[1]
for token in style_token:
if token in rec_str:
rec_str = rec_str.replace(token, '')
if not self.recovery:
box += [x1, y1]
- res.append({
- 'text': rec_str,
- 'confidence': float(rec_conf),
- 'text_region': box.tolist()
- })
+ if self.return_word_box:
+ word_box_content_list, word_box_list = cal_ocr_word_box(rec_str, box, rec_res[2])
+ res.append({
+ 'text': rec_str,
+ 'confidence': float(rec_conf),
+ 'text_region': box.tolist(),
+ 'text_word': word_box_content_list,
+ 'text_word_region': word_box_list
+ })
+ else:
+ res.append({
+ 'text': rec_str,
+ 'confidence': float(rec_conf),
+ 'text_region': box.tolist()
+ })
res_list.append({
'type': region['label'].lower(),
'bbox': [x1, y1, x2, y2],
@@ -229,7 +241,9 @@ def main(args):
if args.recovery and args.use_pdf2docx_api and flag_pdf:
from pdf2docx.converter import Converter
- docx_file = os.path.join(args.output, '{}.docx'.format(img_name))
+ os.makedirs(args.output, exist_ok=True)
+ docx_file = os.path.join(args.output,
+ '{}_api.docx'.format(img_name))
cv = Converter(image_file)
cv.convert(docx_file)
cv.close()
diff --git a/ppstructure/recovery/recovery_to_doc.py b/ppstructure/recovery/recovery_to_doc.py
index 1d8f8d9d4babca7410d6625dbeac4c41668f58a7..cd1728b6668577266c10ab71667e630c21a5703b 100644
--- a/ppstructure/recovery/recovery_to_doc.py
+++ b/ppstructure/recovery/recovery_to_doc.py
@@ -36,6 +36,8 @@ def convert_info_docx(img, res, save_folder, img_name):
flag = 1
for i, region in enumerate(res):
+ if len(region['res']) == 0:
+ continue
img_idx = region['img_idx']
if flag == 2 and region['layout'] == 'single':
section = doc.add_section(WD_SECTION.CONTINUOUS)
@@ -73,7 +75,7 @@ def convert_info_docx(img, res, save_folder, img_name):
text_run.font.size = shared.Pt(10)
# save to docx
- docx_path = os.path.join(save_folder, '{}.docx'.format(img_name))
+ docx_path = os.path.join(save_folder, '{}_ocr.docx'.format(img_name))
doc.save(docx_path)
logger.info('docx save to {}'.format(docx_path))
diff --git a/ppstructure/recovery/requirements.txt b/ppstructure/recovery/requirements.txt
index ec08f9d0a28b54e3e082db4d32799f8384250c1d..761b9d7c3e34cedb335e2c93707619593ebede63 100644
--- a/ppstructure/recovery/requirements.txt
+++ b/ppstructure/recovery/requirements.txt
@@ -1,5 +1,4 @@
python-docx
-PyMuPDF==1.19.0
beautifulsoup4
fonttools>=4.24.0
fire>=0.3.0
diff --git a/ppstructure/recovery/table_process.py b/ppstructure/recovery/table_process.py
index 982e6b760f9291628d0514728dc8f684f183aa2c..77a6ef7659666ebcbe54dd0c107cb2d62e4c7273 100644
--- a/ppstructure/recovery/table_process.py
+++ b/ppstructure/recovery/table_process.py
@@ -278,8 +278,6 @@ class HtmlToDocx(HTMLParser):
cell_col += colspan
cell_row += 1
- doc.save('1.docx')
-
def handle_data(self, data):
if self.skip:
return
diff --git a/ppstructure/table/predict_table.py b/ppstructure/table/predict_table.py
index 354baf6ddf5e73b2e933a9b9e8a568bda80340e5..76bd42dc003cdbd1037cdfe4d50b480f777b41c0 100644
--- a/ppstructure/table/predict_table.py
+++ b/ppstructure/table/predict_table.py
@@ -93,7 +93,7 @@ class TableSystem(object):
time_dict['rec'] = rec_elapse
if return_ocr_result_in_table:
- result['boxes'] = dt_boxes #[x.tolist() for x in dt_boxes]
+ result['boxes'] = [x.tolist() for x in dt_boxes]
result['rec_res'] = rec_res
tic = time.time()
diff --git a/ppstructure/utility.py b/ppstructure/utility.py
index d909f1a8a165745a5c0df78cc3d89960ec4469e7..4ab4b88b9bc073287ec33b29eea9fca471da8470 100644
--- a/ppstructure/utility.py
+++ b/ppstructure/utility.py
@@ -13,9 +13,11 @@
# limitations under the License.
import random
import ast
+import PIL
from PIL import Image, ImageDraw, ImageFont
import numpy as np
-from tools.infer.utility import draw_ocr_box_txt, str2bool, init_args as infer_args
+from tools.infer.utility import draw_ocr_box_txt, str2bool, str2int_tuple, init_args as infer_args
+import math
def init_args():
@@ -98,6 +100,21 @@ def init_args():
type=str2bool,
default=False,
help='Whether to use pdf2docx api')
+ parser.add_argument(
+ "--invert",
+ type=str2bool,
+ default=False,
+ help='Whether to invert image before processing')
+ parser.add_argument(
+ "--binarize",
+ type=str2bool,
+ default=False,
+ help='Whether to threshold binarize image before processing')
+ parser.add_argument(
+ "--alphacolor",
+ type=str2int_tuple,
+ default=(255, 255, 255),
+ help='Replacement color for the alpha channel, if the latter is present; R,G,B integers')
return parser
@@ -132,7 +149,13 @@ def draw_structure_result(image, result, font_path):
[(box_layout[0], box_layout[1]), (box_layout[2], box_layout[3])],
outline=box_color,
width=3)
- text_w, text_h = font.getsize(region['type'])
+
+ if int(PIL.__version__.split('.')[0]) < 10:
+ text_w, text_h = font.getsize(region['type'])
+ else:
+ left, top, right, bottom = font.getbbox(region['type'])
+ text_w, text_h = right - left, bottom - top
+
draw_layout.rectangle(
[(box_layout[0], box_layout[1]),
(box_layout[0] + text_w, box_layout[1] + text_h)],
@@ -151,6 +174,71 @@ def draw_structure_result(image, result, font_path):
txts.append(text_result['text'])
scores.append(text_result['confidence'])
+ if 'text_word_region' in text_result:
+ for word_region in text_result['text_word_region']:
+ char_box = word_region
+ box_height = int(
+ math.sqrt((char_box[0][0] - char_box[3][0])**2 + (
+ char_box[0][1] - char_box[3][1])**2))
+ box_width = int(
+ math.sqrt((char_box[0][0] - char_box[1][0])**2 + (
+ char_box[0][1] - char_box[1][1])**2))
+ if box_height == 0 or box_width == 0:
+ continue
+ boxes.append(word_region)
+ txts.append("")
+ scores.append(1.0)
+
im_show = draw_ocr_box_txt(
img_layout, boxes, txts, scores, font_path=font_path, drop_score=0)
return im_show
+
+
+def cal_ocr_word_box(rec_str, box, rec_word_info):
+ ''' Calculate the detection frame for each word based on the results of recognition and detection of ocr'''
+
+ col_num, word_list, word_col_list, state_list = rec_word_info
+ box = box.tolist()
+ bbox_x_start = box[0][0]
+ bbox_x_end = box[1][0]
+ bbox_y_start = box[0][1]
+ bbox_y_end = box[2][1]
+
+ cell_width = (bbox_x_end - bbox_x_start) / col_num
+
+ word_box_list = []
+ word_box_content_list = []
+ cn_width_list = []
+ cn_col_list = []
+ for word, word_col, state in zip(word_list, word_col_list, state_list):
+ if state == 'cn':
+ if len(word_col) != 1:
+ char_seq_length = (word_col[-1] - word_col[0] + 1) * cell_width
+ char_width = char_seq_length / (len(word_col) - 1)
+ cn_width_list.append(char_width)
+ cn_col_list += word_col
+ word_box_content_list += word
+ else:
+ cell_x_start = bbox_x_start + int(word_col[0] * cell_width)
+ cell_x_end = bbox_x_start + int((word_col[-1] + 1) * cell_width)
+ cell = ((cell_x_start, bbox_y_start), (cell_x_end, bbox_y_start),
+ (cell_x_end, bbox_y_end), (cell_x_start, bbox_y_end))
+ word_box_list.append(cell)
+ word_box_content_list.append("".join(word))
+ if len(cn_col_list) != 0:
+ if len(cn_width_list) != 0:
+ avg_char_width = np.mean(cn_width_list)
+ else:
+ avg_char_width = (bbox_x_end - bbox_x_start) / len(rec_str)
+ for center_idx in cn_col_list:
+ center_x = (center_idx + 0.5) * cell_width
+ cell_x_start = max(int(center_x - avg_char_width / 2),
+ 0) + bbox_x_start
+ cell_x_end = min(
+ int(center_x + avg_char_width / 2), bbox_x_end -
+ bbox_x_start) + bbox_x_start
+ cell = ((cell_x_start, bbox_y_start), (cell_x_end, bbox_y_start),
+ (cell_x_end, bbox_y_end), (cell_x_start, bbox_y_end))
+ word_box_list.append(cell)
+
+ return word_box_content_list, word_box_list
diff --git a/requirements.txt b/requirements.txt
index 8c5b12f831dfcb2a8854ec46b82ff1fa5b84029e..a5a022738c5fe4c7430099a7a1e41c1671b4ed15 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -7,13 +7,12 @@ tqdm
numpy
visualdl
rapidfuzz
-opencv-python
-opencv-contrib-python
+opencv-python<=4.6.0.66
+opencv-contrib-python<=4.6.0.66
cython
lxml
premailer
openpyxl
attrdict
-Polygon3
-lanms-neo==1.0.2
-PyMuPDF==1.19.0
\ No newline at end of file
+PyMuPDF<1.21.0
+Pillow
diff --git a/test_tipc/benchmark_train.sh b/test_tipc/benchmark_train.sh
index 25fda8f97f0bfdefbd6922b13a0ffef3f40c3de9..1668e41a9a95272e38f9f4b5960400718772ec34 100644
--- a/test_tipc/benchmark_train.sh
+++ b/test_tipc/benchmark_train.sh
@@ -72,6 +72,19 @@ FILENAME=$new_filename
# MODE must be one of ['benchmark_train']
MODE=$2
PARAMS=$3
+
+to_static=""
+# parse "to_static" options and modify trainer into "to_static_trainer"
+if [[ $PARAMS =~ "dynamicTostatic" ]] ;then
+ to_static="d2sT_"
+ sed -i 's/trainer:norm_train/trainer:to_static_train/g' $FILENAME
+ # clear PARAM contents
+ if [ $PARAMS = "to_static" ] ;then
+ PARAMS=""
+ fi
+fi
+# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamic_bs8_fp32_DP_N1C8
+# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamicTostatic_bs8_fp32_DP_N1C8
# bash test_tipc/benchmark_train.sh test_tipc/configs/det_mv3_db_v2_0/train_benchmark.txt benchmark_train dynamic_bs8_null_DP_N1C1
IFS=$'\n'
# parser params from train_benchmark.txt
@@ -83,13 +96,13 @@ model_name=$(func_parser_value "${lines[1]}")
python_name=$(func_parser_value "${lines[2]}")
# set env
-python=${python_name}
+python=python
export str_tmp=$(echo `pip list|grep paddlepaddle-gpu|awk -F ' ' '{print $2}'`)
export frame_version=${str_tmp%%.post*}
export frame_commit=$(echo `${python} -c "import paddle;print(paddle.version.commit)"`)
# 获取benchmark_params所在的行数
-line_num=`grep -n "train_benchmark_params" $FILENAME | cut -d ":" -f 1`
+line_num=`grep -n -w "train_benchmark_params" $FILENAME | cut -d ":" -f 1`
# for train log parser
batch_size=$(func_parser_value "${lines[line_num]}")
line_num=`expr $line_num + 1`
@@ -117,7 +130,8 @@ repo_name=$(get_repo_name )
SAVE_LOG=${BENCHMARK_LOG_DIR:-$(pwd)} # */benchmark_log
mkdir -p "${SAVE_LOG}/benchmark_log/"
status_log="${SAVE_LOG}/benchmark_log/results.log"
-
+# get benchmark profiling params : PROFILING_TIMER_ONLY=no|True|False
+PROFILING_TIMER_ONLY=${PROFILING_TIMER_ONLY:-"True"}
# The number of lines in which train params can be replaced.
line_python=3
line_gpuid=4
@@ -140,6 +154,13 @@ if [ ! -n "$PARAMS" ] ;then
fp_items_list=(${fp_items})
device_num_list=(N1C4)
run_mode="DP"
+elif [[ ${PARAMS} = "dynamicTostatic" ]];then
+ IFS="|"
+ model_type=$PARAMS
+ batch_size_list=(${batch_size})
+ fp_items_list=(${fp_items})
+ device_num_list=(N1C4)
+ run_mode="DP"
else
# parser params from input: modeltype_bs${bs_item}_${fp_item}_${run_mode}_${device_num}
IFS="_"
@@ -179,26 +200,32 @@ for batch_size in ${batch_size_list[*]}; do
gpu_id=$(set_gpu_id $device_num)
if [ ${#gpu_id} -le 1 ];then
- log_path="$SAVE_LOG/profiling_log"
- mkdir -p $log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_profiling"
func_sed_params "$FILENAME" "${line_gpuid}" "0" # sed used gpu_id
- # set profile_option params
- tmp=`sed -i "${line_profile}s/.*/${profile_option}/" "${FILENAME}"`
-
- # run test_train_inference_python.sh
- cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
- echo $cmd
- eval $cmd
- eval "cat ${log_path}/${log_name}"
-
+ if [[ ${PROFILING_TIMER_ONLY} != "no" ]];then
+ echo "run profile"
+ # The default value of profile_option's timer_only parameter is True
+ if [[ ${PROFILING_TIMER_ONLY} = "False" ]];then
+ profile_option="${profile_option};timer_only=False"
+ fi
+ log_path="$SAVE_LOG/profiling_log"
+ mkdir -p $log_path
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}profiling"
+ # set profile_option params
+ tmp=`sed -i "${line_profile}s/.*/\"${profile_option}\"/" "${FILENAME}"`
+ # run test_train_inference_python.sh
+ cmd="timeout 5m bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
+ echo $cmd
+ eval ${cmd}
+ eval "cat ${log_path}/${log_name}"
+ fi
+ echo "run without profile"
# without profile
log_path="$SAVE_LOG/train_log"
speed_log_path="$SAVE_LOG/index"
mkdir -p $log_path
mkdir -p $speed_log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_log"
- speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_speed"
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
func_sed_params "$FILENAME" "${line_profile}" "null" # sed profile_id as null
cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
echo $cmd
@@ -232,8 +259,8 @@ for batch_size in ${batch_size_list[*]}; do
speed_log_path="$SAVE_LOG/index"
mkdir -p $log_path
mkdir -p $speed_log_path
- log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_log"
- speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_speed"
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
func_sed_params "$FILENAME" "${line_gpuid}" "$gpu_id" # sed used gpu_id
func_sed_params "$FILENAME" "${line_profile}" "null" # sed --profile_option as null
cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml b/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
index 3eb82d42bc3f2b3ca7420d999865977bbad09e31..43e14b84d77a216ef949e2af14a01b65bb350b54 100644
--- a/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
+++ b/test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml
@@ -27,7 +27,7 @@ Optimizer:
beta2: 0.999
lr:
name: Piecewise
- decay_epochs : [700, 800]
+ decay_epochs : [700]
values : [0.001, 0.0001]
warmup_epoch: 5
regularizer:
diff --git a/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
index bf10aebe3e9aa67e30ce7a20cb07f376825e39ae..8daab48a4dc08aae888d7b784605b3986e220821 100644
--- a/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_det/train_infer_python.txt
@@ -17,7 +17,7 @@ norm_train:tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -57,3 +57,5 @@ fp_items:fp32|fp16
epoch:2
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
index 4c8ba0a6fa4a355e9bad1665a8de82399f919740..63362135737f1665fecb16d5b7d6a19c8cd1b8da 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_distillation.yml
@@ -19,6 +19,7 @@ Global:
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_distillation.txt
+ d2s_train_image_shape: [3, 48, -1]
Optimizer:
@@ -27,7 +28,7 @@ Optimizer:
beta2: 0.999
lr:
name: Piecewise
- decay_epochs : [700, 800]
+ decay_epochs : [700]
values : [0.0005, 0.00005]
warmup_epoch: 5
regularizer:
@@ -45,7 +46,7 @@ Architecture:
freeze_params: false
return_all_feats: true
model_type: *model_type
- algorithm: SVTR
+ algorithm: SVTR_LCNet
Transform:
Backbone:
name: MobileNetV1Enhance
@@ -72,7 +73,7 @@ Architecture:
freeze_params: false
return_all_feats: true
model_type: *model_type
- algorithm: SVTR
+ algorithm: SVTR_LCNet
Transform:
Backbone:
name: MobileNetV1Enhance
diff --git a/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
index fee08b08ede0f61ae4f57fd42dba303301798a3e..13480ec49acc3896920219bee369bb4bfc97b6ff 100644
--- a/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv3_rec/train_infer_python.txt
@@ -17,7 +17,7 @@ norm_train:tools/train.py -c test_tipc/configs/ch_PP-OCRv3_rec/ch_PP-OCRv3_rec_d
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -57,4 +57,5 @@ fp_items:fp32|fp16
epoch:1
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
-
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3635c0c6f06c73909527874f54a8fc0402e4c61d
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_det/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_det
+python:python
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:pretrain_models/PPLCNetV3_x0_75_ocr_det.pdparams
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Global.eval_batch_step=[4000,400]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv3_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
+===========================train_benchmark_params==========================
+batch_size:8
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5796deb010d4d58162d1d93b56dca4568c14b849
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt] Train.loader.num_workers=16 Eval.loader.num_workers=16
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:128
+fp_items:fp32|fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fc2884be97f1d483a9d33a0674c8b4bdbfd5ef87
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_ampO2_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_ampO2_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:384
+fp_items:fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0465cfc5d78f477ce2b3a7f7b87ceebcef45b5b5
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_mobile_rec_fp32_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_mobile_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_fp32_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:192
+fp_items:fp32
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..315fac9829be3a6443958bdaa2d69a5f84b26c26
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_det/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_det
+python:python
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:pretrain_models/PPHGNet_small_ocr_det.pdparams
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_teacher.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Global.eval_batch_step=[4000,400]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_teacher.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv3_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
+===========================train_benchmark_params==========================
+batch_size:4
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c7fa48f196b92939687d34c7c310e15a57a6d9b4
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt] Train.loader.num_workers=16 Eval.loader.num_workers=16
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:128
+fp_items:fp32|fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..679d2aa37179ba85cad2d0b65c3d06a6c2eb5af9
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec_ampO2_ultra/train_infer_python.txt
@@ -0,0 +1,60 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet_ampO2_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:256
+fp_items:fp16
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..368bc7c64c1d05ee8d6670638fff4d62f4d08796
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv4_server_rec_fp32_ultra/train_infer_python.txt
@@ -0,0 +1,61 @@
+===========================train_params===========================
+model_name:ch_PP-OCRv4_server_rec
+python:python
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:fp32
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=50
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_hgnet_fp32_ultra.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/ic15_data Train.dataset.label_file_list=[./train_data/ic15_data/rec_gt_train.txt] Eval.dataset.data_dir=./train_data/ic15_data Eval.dataset.label_file_list=[./train_data/ic15_data/rec_gt_test.txt]
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:Global.to_static=true
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+##
+infer_model:./inference/ch_PP-OCRv4_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_image_shape="3,48,320"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,48,320]}]
+===========================train_benchmark_params==========================
+batch_size:256
+fp_items:fp32
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================disable_to_static_train_benchmark===========================
+to_static_train:Global.to_static=False
diff --git a/test_tipc/configs/en_table_structure/table_mv3.yml b/test_tipc/configs/en_table_structure/table_mv3.yml
deleted file mode 100755
index edcbe2c3b00e8d8a56ad8dd9f208e283b511b86e..0000000000000000000000000000000000000000
--- a/test_tipc/configs/en_table_structure/table_mv3.yml
+++ /dev/null
@@ -1,129 +0,0 @@
-Global:
- use_gpu: true
- epoch_num: 10
- log_smooth_window: 20
- print_batch_step: 5
- save_model_dir: ./output/table_mv3/
- save_epoch_step: 400
- # evaluation is run every 400 iterations after the 0th iteration
- eval_batch_step: [0, 40000]
- cal_metric_during_train: True
- pretrained_model:
- checkpoints:
- save_inference_dir:
- use_visualdl: False
- infer_img: ppstructure/docs/table/table.jpg
- save_res_path: output/table_mv3
- # for data or label process
- character_dict_path: ppocr/utils/dict/table_structure_dict.txt
- character_type: en
- max_text_length: &max_text_length 500
- box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
- infer_mode: False
-
-Optimizer:
- name: Adam
- beta1: 0.9
- beta2: 0.999
- clip_norm: 5.0
- lr:
- learning_rate: 0.001
- regularizer:
- name: 'L2'
- factor: 0.00000
-
-Architecture:
- model_type: table
- algorithm: TableAttn
- Backbone:
- name: MobileNetV3
- scale: 1.0
- model_name: small
- disable_se: true
- Head:
- name: TableAttentionHead
- hidden_size: 256
- loc_type: 2
- max_text_length: *max_text_length
- loc_reg_num: &loc_reg_num 4
-
-Loss:
- name: TableAttentionLoss
- structure_weight: 100.0
- loc_weight: 10000.0
-
-PostProcess:
- name: TableLabelDecode
-
-Metric:
- name: TableMetric
- main_indicator: acc
- compute_bbox_metric: false # cost many time, set False for training
-
-Train:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train
- label_file_list: [./train_data/pubtabnet/train.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: False
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: True
- batch_size_per_card: 32
- drop_last: True
- num_workers: 1
-
-Eval:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: False
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 16
- num_workers: 1
diff --git a/test_tipc/configs/en_table_structure/train_infer_python.txt b/test_tipc/configs/en_table_structure/train_infer_python.txt
index 3fd5dc9f60a9621026d488e5654cd7e1421e8b65..8861ea8cc134a94dfa7b9b233ea66bc341a5a666 100644
--- a/test_tipc/configs/en_table_structure/train_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o Global.print_batch_step=1 Train.loader.shuffle=false
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
index 41d236c3765fbf6a711c6739d8dee4f41a147039..8e25b9d4ef7abbde7986545ec7245cc92ae25710 100644
--- a/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/en_table_structure/train_linux_gpu_fleet_normal_infer_python_linux_gpu_cpu.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index 31ac1ed53f2adc9810bc4fd2cf4f874d89d49606..a399e35d453745f323ec4c4e18fe428fe8150d85 100644
--- a/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/en_table_structure/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_train:tools/train.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+norm_export:tools/export_model.py -c configs/table/table_mv3.yml -o
quant_export:
fpgm_export:
distill_export:null
diff --git a/test_tipc/configs/en_table_structure/train_pact_infer_python.txt b/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
index 9890b906a1d3b1127352af567dca0d7186f94694..0bb04c4c929a53ebb44db0ce5c3e98b28c179ff9 100644
--- a/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_pact_infer_python.txt
@@ -14,7 +14,7 @@ null:null
##
trainer:pact_train
norm_train:null
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+pact_train:deploy/slim/quantization/quant.py -c configs/table/table_mv3.yml -o Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
fpgm_train:null
distill_train:null
null:null
@@ -28,7 +28,7 @@ null:null
Global.save_inference_dir:./output/
Global.checkpoints:
norm_export:null
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+quant_export:deploy/slim/quantization/export_model.py -c configs/table/table_mv3.yml -o
fpgm_export:
distill_export:null
export1:null
diff --git a/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt b/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
index e8f7bbaa50417b97f79596634677fff0a95cb47f..aae0895e6469e6913673e5e5dad2f75702f6c921 100644
--- a/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
+++ b/test_tipc/configs/en_table_structure/train_ptq_infer_python.txt
@@ -4,7 +4,7 @@ python:python3.7
Global.pretrained_model:
Global.save_inference_dir:null
infer_model:./inference/en_ppocr_mobile_v2.0_table_structure_infer/
-infer_export:deploy/slim/quantization/quant_kl.py -c test_tipc/configs/en_table_structure/table_mv3.yml -o
+infer_export:deploy/slim/quantization/quant_kl.py -c configs/table/table_mv3.yml -o
infer_quant:True
inference:ppstructure/table/predict_table.py --det_model_dir=./inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=./inference/en_ppocr_mobile_v2.0_table_rec_infer --rec_char_dict_path=./ppocr/utils/dict/table_dict.txt --table_char_dict_path=./ppocr/utils/dict/table_structure_dict.txt --image_dir=./ppstructure/docs/table/table.jpg --det_limit_side_len=736 --det_limit_type=min --output ./output/table
--use_gpu:True|False
diff --git a/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml b/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
index d2be152f0bae7d87129904d87c56c6d777a1f338..31e0ed4918e25c9408b0a6f77ae94d3d8f734cc1 100644
--- a/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
+++ b/test_tipc/configs/layoutxlm_ser/ser_layoutxlm_xfund_zh.yml
@@ -84,7 +84,7 @@ Train:
shuffle: True
drop_last: False
batch_size_per_card: 8
- num_workers: 4
+ num_workers: 16
Eval:
dataset:
diff --git a/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
index 140b17e0e79f9895167e9c51d86ced173e44a541..6e22bc7832c292b59e060f0564d77c1e93d785af 100644
--- a/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
+++ b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
@@ -20,6 +20,7 @@ Global:
infer_mode: False
use_space_char: False
save_res_path: ./output/rec/predicts_svtr_tiny.txt
+ d2s_train_image_shape: [3, 64, 256]
Optimizer:
diff --git a/test_tipc/configs/rec_svtrnet/train_infer_python.txt b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
index 5508c0411cfdc7102ccec7a00c59c2a5e1a54998..63e6b908a35c061f0979d0548f73e73b4265505d 100644
--- a/test_tipc/configs/rec_svtrnet/train_infer_python.txt
+++ b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
@@ -51,3 +51,11 @@ inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dic
null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,64,256]}]
+===========================train_benchmark_params==========================
+batch_size:512
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/slanet/SLANet.yml b/test_tipc/configs/slanet/SLANet.yml
deleted file mode 100644
index 0d55d70d64e29716e942517e9c0d4909e6f70f9b..0000000000000000000000000000000000000000
--- a/test_tipc/configs/slanet/SLANet.yml
+++ /dev/null
@@ -1,143 +0,0 @@
-Global:
- use_gpu: true
- epoch_num: 100
- log_smooth_window: 20
- print_batch_step: 20
- save_model_dir: ./output/SLANet
- save_epoch_step: 400
- # evaluation is run every 1000 iterations after the 0th iteration
- eval_batch_step: [0, 1000]
- cal_metric_during_train: True
- pretrained_model:
- checkpoints:
- save_inference_dir: ./output/SLANet/infer
- use_visualdl: False
- infer_img: ppstructure/docs/table/table.jpg
- # for data or label process
- character_dict_path: ppocr/utils/dict/table_structure_dict.txt
- character_type: en
- max_text_length: &max_text_length 500
- box_format: &box_format 'xyxy' # 'xywh', 'xyxy', 'xyxyxyxy'
- infer_mode: False
- use_sync_bn: True
- save_res_path: 'output/infer'
-
-Optimizer:
- name: Adam
- beta1: 0.9
- beta2: 0.999
- clip_norm: 5.0
- lr:
- name: Piecewise
- learning_rate: 0.001
- decay_epochs : [40, 50]
- values : [0.001, 0.0001, 0.00005]
- regularizer:
- name: 'L2'
- factor: 0.00000
-
-Architecture:
- model_type: table
- algorithm: SLANet
- Backbone:
- name: PPLCNet
- scale: 1.0
- pretrained: true
- use_ssld: true
- Neck:
- name: CSPPAN
- out_channels: 96
- Head:
- name: SLAHead
- hidden_size: 256
- max_text_length: *max_text_length
- loc_reg_num: &loc_reg_num 4
-
-Loss:
- name: SLALoss
- structure_weight: 1.0
- loc_weight: 2.0
- loc_loss: smooth_l1
-
-PostProcess:
- name: TableLabelDecode
- merge_no_span_structure: &merge_no_span_structure True
-
-Metric:
- name: TableMetric
- main_indicator: acc
- compute_bbox_metric: False
- loc_reg_num: *loc_reg_num
- box_format: *box_format
-
-Train:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train/
- label_file_list: [./train_data/pubtabnet/train.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: *merge_no_span_structure
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- in_box_format: *box_format
- out_box_format: *box_format
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: True
- batch_size_per_card: 48
- drop_last: True
- num_workers: 1
-
-Eval:
- dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - TableLabelEncode:
- learn_empty_box: False
- merge_no_span_structure: *merge_no_span_structure
- replace_empty_cell_token: False
- loc_reg_num: *loc_reg_num
- max_text_length: *max_text_length
- - TableBoxEncode:
- in_box_format: *box_format
- out_box_format: *box_format
- - ResizeTableImage:
- max_len: 488
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - PaddingTableImage:
- size: [488, 488]
- - ToCHWImage:
- - KeepKeys:
- keep_keys: [ 'image', 'structure', 'bboxes', 'bbox_masks', 'shape' ]
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 48
- num_workers: 1
diff --git a/test_tipc/configs/slanet/train_infer_python.txt b/test_tipc/configs/slanet/train_infer_python.txt
index 05264360ac95d08ba11157372a9badef23afdc70..0beebc04d63f74d6d099f19b516a4702b43bd39f 100644
--- a/test_tipc/configs/slanet/train_infer_python.txt
+++ b/test_tipc/configs/slanet/train_infer_python.txt
@@ -1,6 +1,6 @@
===========================train_params===========================
model_name:slanet
-python:python3.7
+python:python
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:fp32
@@ -13,11 +13,11 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/slanet/SLANet.yml -o Global.print_batch_step=1 Train.loader.shuffle=false
+norm_train:tools/train.py -c configs/table/SLANet.yml -o Global.cal_metric_during_train=False Global.print_batch_step=1 Train.loader.shuffle=false Train.dataset.data_dir=./train_data/pubtabnet/train Train.dataset.label_file_list=[./train_data/pubtabnet/train.jsonl] Eval.dataset.data_dir=./train_data/pubtabnet/test Eval.dataset.label_file_list=[./train_data/pubtabnet/test.jsonl]
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -27,7 +27,7 @@ null:null
===========================infer_params===========================
Global.save_inference_dir:./output/
Global.checkpoints:
-norm_export:tools/export_model.py -c test_tipc/configs/slanet/SLANet.yml -o
+norm_export:tools/export_model.py -c configs/table/SLANet.yml -o
quant_export:
fpgm_export:
distill_export:null
@@ -52,8 +52,10 @@ null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,488,488]}]
===========================train_benchmark_params==========================
-batch_size:32
+batch_size:64
fp_items:fp32|fp16
epoch:2
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/table_master/table_master.yml b/test_tipc/configs/table_master/table_master.yml
index 27f81683b9b7e9475bdfa4ad4862166f4cf9c14d..b27bdae542bf85d8f2932372d9002c2de8d6c652 100644
--- a/test_tipc/configs/table_master/table_master.yml
+++ b/test_tipc/configs/table_master/table_master.yml
@@ -6,7 +6,7 @@ Global:
save_model_dir: ./output/table_master/
save_epoch_step: 17
eval_batch_step: [0, 6259]
- cal_metric_during_train: true
+ cal_metric_during_train: false
pretrained_model: null
checkpoints:
save_inference_dir: output/table_master/infer
@@ -16,6 +16,7 @@ Global:
character_dict_path: ppocr/utils/dict/table_master_structure_dict.txt
infer_mode: false
max_text_length: 500
+ d2s_train_image_shape: [3, 480, 480]
Optimizer:
@@ -67,16 +68,15 @@ Metric:
Train:
dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/train
- label_file_list: [./train_data/pubtabnet/train.jsonl]
+ name: LMDBDataSetTableMaster
+ data_dir: train_data/StructureLabel_val_500/
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: False
replace_empty_cell_token: True
- ResizeTableImage:
max_len: 480
@@ -101,16 +101,15 @@ Train:
Eval:
dataset:
- name: PubTabDataSet
- data_dir: ./train_data/pubtabnet/test/
- label_file_list: [./train_data/pubtabnet/test.jsonl]
+ name: LMDBDataSetTableMaster
+ data_dir: train_data/StructureLabel_val_500/
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- TableMasterLabelEncode:
learn_empty_box: False
- merge_no_span_structure: True
+ merge_no_span_structure: False
replace_empty_cell_token: True
- ResizeTableImage:
max_len: 480
diff --git a/test_tipc/configs/table_master/train_infer_python.txt b/test_tipc/configs/table_master/train_infer_python.txt
index c3a871731a36fb5434db111cfd68b6eab7ba3f99..a248cd8227a22babb29f2fad1b4eb8b30051711f 100644
--- a/test_tipc/configs/table_master/train_infer_python.txt
+++ b/test_tipc/configs/table_master/train_infer_python.txt
@@ -13,7 +13,7 @@ train_infer_img_dir:./ppstructure/docs/table/table.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c test_tipc/configs/table_master/table_master.yml -o Global.print_batch_step=10
+norm_train:tools/train.py -c test_tipc/configs/table_master/table_master.yml -o Global.print_batch_step=1
pact_train:null
fpgm_train:null
distill_train:null
@@ -51,3 +51,11 @@ null:null
null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,480,480]}]
+===========================train_benchmark_params==========================
+batch_size:10
+fp_items:fp32|fp16
+epoch:2
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
\ No newline at end of file
diff --git a/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt b/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
index adad78bb76e34635a632ef7c1b55e212bc4b636a..e304519c719f21deed52c5f33aa9ce3a8fd8251d 100644
--- a/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
+++ b/test_tipc/configs/vi_layoutxlm_ser/train_infer_python.txt
@@ -1,6 +1,6 @@
===========================train_params===========================
model_name:vi_layoutxlm_ser
-python:python3.7
+python:python
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:fp32
@@ -13,11 +13,11 @@ train_infer_img_dir:ppstructure/docs/kie/input/zh_val_42.jpg
null:null
##
trainer:norm_train
-norm_train:tools/train.py -c ./configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Global.print_batch_step=1 Global.eval_batch_step=[1000,1000] Train.loader.shuffle=false
+norm_train:tools/train.py -c ./configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Global.print_batch_step=1 Global.eval_batch_step=[1000,1000] Train.loader.shuffle=false Train.loader.num_workers=32 Eval.loader.num_workers=32
pact_train:null
fpgm_train:null
distill_train:null
-null:null
+to_static_train:Global.to_static=true
null:null
##
===========================eval_params===========================
@@ -52,8 +52,10 @@ null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[3,224,224]}]
===========================train_benchmark_params==========================
-batch_size:4
+batch_size:8
fp_items:fp32|fp16
epoch:3
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98
+===========================to_static_train_benchmark_params===========================
+to_static_train:Global.to_static=true
diff --git a/test_tipc/prepare.sh b/test_tipc/prepare.sh
index 02ee8a24d241195d1330ea42fc05ed35dd7a87b7..a2e5332745a704ca8bf0770823be36ae8c475802 100644
--- a/test_tipc/prepare.sh
+++ b/test_tipc/prepare.sh
@@ -23,7 +23,7 @@ trainer_list=$(func_parser_value "${lines[14]}")
if [ ${MODE} = "benchmark_train" ];then
python_name_list=$(func_parser_value "${lines[2]}")
array=(${python_name_list})
- python_name=${array[0]}
+ python_name=python
${python_name} -m pip install -r requirements.txt
if [[ ${model_name} =~ "ch_ppocr_mobile_v2_0_det" || ${model_name} =~ "det_mv3_db_v2_0" ]];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
@@ -40,6 +40,42 @@ if [ ${MODE} = "benchmark_train" ];then
cd ../../../
fi
fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPLCNetV3_x0_75_ocr_det.pdparams --no-check-certificate
+ rm -rf ./train_data/icdar2015
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015_benckmark.tar
+ ln -s ./icdar2015_benckmark ./icdar2015
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPHGNet_small_ocr_det.pdparams --no-check-certificate
+ rm -rf ./train_data/icdar2015
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf icdar2015_benckmark.tar
+ ln -s ./icdar2015_benckmark ./icdar2015
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_rec" ]];then
+ rm -rf ./train_data/ic15_data
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+ cd ../
+ cd ../
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_rec" ]];then
+ rm -rf ./train_data/ic15_data
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+ cd ../
+ cd ../
+ fi
if [[ ${model_name} =~ "ch_ppocr_server_v2_0_det" || ${model_name} =~ "ch_PP-OCRv3_det" ]];then
rm -rf ./train_data/icdar2015
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/icdar2015_benckmark.tar --no-check-certificate
@@ -88,7 +124,7 @@ if [ ${MODE} = "benchmark_train" ];then
ln -s ./ic15_data_benckmark ./ic15_data
cd ../
fi
- if [[ ${model_name} =~ "ch_PP-OCRv2_rec" || ${model_name} =~ "ch_PP-OCRv3_rec" ]];then
+ if [[ ${model_name} =~ "ch_PP-OCRv2_rec" || ${model_name} =~ "ch_PP-OCRv3_rec" || ${model_name} =~ "ch_PP-OCRv4_mobile_rec" || ${model_name} =~ "ch_PP-OCRv4_server_rec" ]];then
rm -rf ./train_data/ic15_data
wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
cd ./train_data/ && tar xf ic15_data_benckmark.tar
@@ -138,6 +174,26 @@ if [ ${MODE} = "benchmark_train" ];then
cd ../
fi
+ if [ ${model_name} == "table_master" ];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar --no-check-certificate
+ cd ./pretrain_models/ && tar xf table_structure_tablemaster_train.tar && cd ../
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/StructureLabel_val_500.tar --no-check-certificate
+ cd ./train_data/ && tar xf StructureLabel_val_500.tar
+ cd ../
+ fi
+ if [ ${model_name} == "rec_svtrnet" ]; then
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/ic15_data_benckmark.tar --no-check-certificate
+ cd ./train_data/ && tar xf ic15_data_benckmark.tar
+ ln -s ./ic15_data_benckmark ./ic15_data
+ cd ic15_data
+ mv rec_gt_train4w.txt rec_gt_train.txt
+
+ for i in `seq 10`;do cp rec_gt_train.txt dup$i.txt;done
+ cat dup* > rec_gt_train.txt && rm -rf dup*
+
+ cd ../
+ cd ../
+ fi
fi
if [ ${MODE} = "lite_train_lite_infer" ];then
@@ -150,7 +206,9 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
# pretrain lite train data
wget -nc -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams --no-check-certificate
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar --no-check-certificate
- cd ./pretrain_models/ && tar xf det_mv3_db_v2.0_train.tar && cd ../
+ cd ./pretrain_models/
+ tar xf det_mv3_db_v2.0_train.tar
+ cd ../
if [[ ${model_name} =~ "ch_PP-OCRv2_det" ]];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv2_det_distill_train.tar && cd ../
@@ -159,6 +217,12 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf ch_PP-OCRv3_det_distill_train.tar && cd ../
fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_mobile_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPLCNetV3_x0_75_ocr_det.pdparams --no-check-certificate
+ fi
+ if [[ ${model_name} =~ "ch_PP-OCRv4_server_det" ]];then
+ wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/PPHGNet_small_ocr_det.pdparams --no-check-certificate
+ fi
if [ ${model_name} == "en_table_structure" ] || [ ${model_name} == "en_table_structure_PACT" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf en_ppocr_mobile_v2.0_table_structure_train.tar && cd ../
@@ -179,6 +243,8 @@ if [ ${MODE} = "lite_train_lite_infer" ];then
if [ ${model_name} == "table_master" ];then
wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/tablemaster/table_structure_tablemaster_train.tar --no-check-certificate
cd ./pretrain_models/ && tar xf table_structure_tablemaster_train.tar && cd ../
+ wget -nc -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/StructureLabel_val_500.tar --no-check-certificate
+ cd ./train_data/ && tar xf StructureLabel_val_500.tar && cd ../
fi
rm -rf ./train_data/icdar2015
rm -rf ./train_data/ic15_data
@@ -366,7 +432,7 @@ elif [ ${MODE} = "whole_infer" ];then
python_name_list=$(func_parser_value "${lines[2]}")
array=(${python_name_list})
python_name=${array[0]}
- ${python_name} -m pip install paddleslim --force-reinstall
+ ${python_name} -m pip install paddleslim
${python_name} -m pip install -r requirements.txt
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/ch_det_data_50.tar --no-check-certificate
wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/rec_inference.tar --no-check-certificate
diff --git a/test_tipc/supplementary/data_loader.py b/test_tipc/supplementary/data_loader.py
index 049e7b2d36306d4bb7264d1c45a072ed84bbba60..f0245dd27cc5bb5d7272d6950f27b4ae0ba899f2 100644
--- a/test_tipc/supplementary/data_loader.py
+++ b/test_tipc/supplementary/data_loader.py
@@ -1,7 +1,6 @@
import numpy as np
from paddle.vision.datasets import Cifar100
from paddle.vision.transforms import Normalize
-from paddle.fluid.dataloader.collate import default_collate_fn
import signal
import os
from paddle.io import Dataset, DataLoader, DistributedBatchSampler
diff --git a/test_tipc/supplementary/train.py b/test_tipc/supplementary/train.py
index e632d1d1803a85144bc750c3ff6ff51b1eb65973..f582123407956b335aac8a0845cae50769dae829 100644
--- a/test_tipc/supplementary/train.py
+++ b/test_tipc/supplementary/train.py
@@ -71,7 +71,7 @@ def amp_scaler(config):
'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
'FLAGS_max_inplace_grad_add': 8,
}
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["AMP"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["AMP"].get("use_dynamic_loss_scaling",
False)
@@ -168,22 +168,22 @@ def train(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
model,
@@ -276,22 +276,22 @@ def train_distill(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model._layers.student)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
@@ -401,22 +401,22 @@ def train_distill_multiopt(config, scaler=None):
if idx % 10 == 0:
et = time.time()
strs = f"epoch: [{epoch}/{EPOCH}], iter: [{idx}/{data_num}], "
- strs += f"loss: {avg_loss.numpy()[0]}, loss1: {avg_loss1.numpy()[0]}"
- strs += f", acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs += f"loss: {float(avg_loss)}, loss1: {float(avg_loss1)}"
+ strs += f", acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
strs += f", batch_time: {round(et-st, 4)} s"
logger.info(strs)
st = time.time()
if epoch % 10 == 0:
acc = eval(config, model._layers.student)
- if len(best_acc) < 1 or acc['top5'].numpy()[0] > best_acc['top5']:
+ if len(best_acc) < 1 or float(acc['top5']) > best_acc['top5']:
best_acc = acc
best_acc['epoch'] = epoch
is_best = True
else:
is_best = False
logger.info(
- f"The best acc: acc_topk1: {best_acc['top1'].numpy()[0]}, acc_top5: {best_acc['top5'].numpy()[0]}, best_epoch: {best_acc['epoch']}"
+ f"The best acc: acc_topk1: {float(best_acc['top1'])}, acc_top5: {float(best_acc['top5'])}, best_epoch: {best_acc['epoch']}"
)
save_model(
model, [optimizer, optimizer1],
@@ -450,7 +450,7 @@ def eval(config, model):
labels = paddle.concat(labels, axis=0)
acc = metric_func(outs, labels)
- strs = f"The metric are as follows: acc_topk1: {acc['top1'].numpy()[0]}, acc_top5: {acc['top5'].numpy()[0]}"
+ strs = f"The metric are as follows: acc_topk1: {float(acc['top1'])}, acc_top5: {float(acc['top5'])}"
logger.info(strs)
return acc
diff --git a/test_tipc/test_serving_infer_cpp.sh b/test_tipc/test_serving_infer_cpp.sh
index 10ddecf3fa26805fef7bc6ae10d78ee5e741cd27..6de685682a20acda0f97e64abfa20e61284f9b1b 100644
--- a/test_tipc/test_serving_infer_cpp.sh
+++ b/test_tipc/test_serving_infer_cpp.sh
@@ -103,7 +103,9 @@ function func_serving(){
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
status_check $last_status "${cpp_client_cmd}" "${status_log}" "${model_name}" "${_save_log_path}"
- ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ #ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ ${python_list[0]} ${web_service_py} stop
+ sleep 5s
else
server_log_path="${LOG_PATH}/cpp_server_gpu.log"
web_service_cpp_cmd="nohup ${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} ${gpu_key} ${gpu_id} > ${server_log_path} 2>&1 &"
@@ -115,7 +117,8 @@ function func_serving(){
last_status=${PIPESTATUS[0]}
eval "cat ${_save_log_path}"
status_check $last_status "${cpp_client_cmd}" "${status_log}" "${model_name}" "${_save_log_path}"
- ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ #ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
+ ${python_list[0]} ${web_service_py} stop
fi
done
}
diff --git a/test_tipc/test_train_inference_python.sh b/test_tipc/test_train_inference_python.sh
index e182fa57f060c81af012a5da89b892bde02b4a2b..9a94db858cb44355745ebb0399a227fe24e2dc73 100644
--- a/test_tipc/test_train_inference_python.sh
+++ b/test_tipc/test_train_inference_python.sh
@@ -5,7 +5,7 @@ FILENAME=$1
# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer', 'whole_infer']
MODE=$2
-dataline=$(awk 'NR==1, NR==51{print}' $FILENAME)
+dataline=$(awk 'NR>=1{print}' $FILENAME)
# parser params
IFS=$'\n'
@@ -88,11 +88,14 @@ benchmark_value=$(func_parser_value "${lines[49]}")
infer_key1=$(func_parser_key "${lines[50]}")
infer_value1=$(func_parser_value "${lines[50]}")
+line_num=`grep -n -w "to_static_train_benchmark_params" $FILENAME | cut -d ":" -f 1`
+to_static_key=$(func_parser_key "${lines[line_num]}")
+to_static_trainer=$(func_parser_value "${lines[line_num]}")
+
LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
mkdir -p ${LOG_PATH}
status_log="${LOG_PATH}/results_python.log"
-
function func_inference(){
IFS='|'
_python=$1
@@ -253,9 +256,9 @@ else
elif [ ${trainer} = "${distill_key}" ]; then
run_train=${distill_trainer}
run_export=${distill_export}
- elif [ ${trainer} = ${trainer_key1} ]; then
- run_train=${trainer_value1}
- run_export=${export_value1}
+ elif [ ${trainer} = "${to_static_key}" ]; then
+ run_train="${norm_trainer} ${to_static_trainer}"
+ run_export=${norm_export}
elif [[ ${trainer} = ${trainer_key2} ]]; then
run_train=${trainer_value2}
run_export=${export_value2}
@@ -289,11 +292,11 @@ else
set_save_model=$(func_set_params "${save_model_key}" "${save_log}")
if [ ${#gpu} -le 2 ];then # train with cpu or single gpu
- cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_train_params1} ${set_amp_config} "
+ cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
elif [ ${#ips} -le 15 ];then # train with multi-gpu
- cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_train_params1} ${set_amp_config}"
+ cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
else # train with multi-machine
- cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_train_params1} ${set_amp_config}"
+ cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_amp_config} ${set_train_params1}"
fi
# run train
eval $cmd
@@ -337,5 +340,4 @@ else
done # done with: for trainer in ${trainer_list[*]}; do
done # done with: for autocast in ${autocast_list[*]}; do
done # done with: for gpu in ${gpu_list[*]}; do
-fi # end if [ ${MODE} = "infer" ]; then
-
+fi # end if [ ${MODE} = "infer" ]; then
\ No newline at end of file
diff --git a/test_tipc/test_train_inference_python_npu.sh b/test_tipc/test_train_inference_python_npu.sh
index bab70fc78ee902515c0fccb57d9215d86f2a6589..4341ceeaebfdbef2b29e40e9b2361e6ab6ab7a61 100644
--- a/test_tipc/test_train_inference_python_npu.sh
+++ b/test_tipc/test_train_inference_python_npu.sh
@@ -29,18 +29,28 @@ fi
sed -i 's/use_gpu/use_npu/g' $FILENAME
# disable benchmark as AutoLog required nvidia-smi command
sed -i 's/--benchmark:True/--benchmark:False/g' $FILENAME
+# python has been updated to version 3.9 for npu backend
+sed -i "s/python3.7/python3.9/g" $FILENAME
dataline=`cat $FILENAME`
# parser params
IFS=$'\n'
lines=(${dataline})
+modelname=$(echo ${lines[1]} | cut -d ":" -f2)
+if [ $modelname == "rec_r31_sar" ] || [ $modelname == "rec_mtb_nrtr" ]; then
+ sed -i "s/Global.epoch_num:lite_train_lite_infer=2/Global.epoch_num:lite_train_lite_infer=1/g" $FILENAME
+ sed -i "s/gpu_list:0|0,1/gpu_list:0,1/g" $FILENAME
+ sed -i "s/Global.use_npu:True|True/Global.use_npu:True/g" $FILENAME
+fi
+
# replace training config file
grep -n 'tools/.*yml' $FILENAME | cut -d ":" -f 1 \
| while read line_num ; do
train_cmd=$(func_parser_value "${lines[line_num-1]}")
trainer_config=$(func_parser_config ${train_cmd})
sed -i 's/use_gpu/use_npu/g' "$REPO_ROOT_PATH/$trainer_config"
+ sed -i 's/use_sync_bn: True/use_sync_bn: False/g' "$REPO_ROOT_PATH/$trainer_config"
done
# change gpu to npu in execution script
diff --git a/tools/eval.py b/tools/eval.py
index 21f4d94d5e4ed560b8775c8827ffdbbd00355218..b4c69b6d37532103f1316eb3b7a14b472d741ed3 100755
--- a/tools/eval.py
+++ b/tools/eval.py
@@ -24,7 +24,7 @@ sys.path.insert(0, __dir__)
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
import paddle
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
from ppocr.metrics import build_metric
@@ -35,6 +35,7 @@ import tools.program as program
def main():
global_config = config['Global']
# build dataloader
+ set_signal_handlers()
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
@@ -54,8 +55,12 @@ def main():
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -66,8 +71,11 @@ def main():
out_channels_list = {}
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
@@ -75,7 +83,8 @@ def main():
model = build_model(config['Architecture'])
extra_input_models = [
- "SRN", "NRTR", "SAR", "SEED", "SVTR", "VisionLAN", "RobustScanner"
+ "SRN", "NRTR", "SAR", "SEED", "SVTR", "SVTR_LCNet", "VisionLAN",
+ "RobustScanner", "SVTR_HGNet"
]
extra_input = False
if config['Architecture']['algorithm'] == 'Distillation':
@@ -103,7 +112,7 @@ def main():
'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
'FLAGS_max_inplace_grad_add': 8,
}
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["Global"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["Global"].get(
"use_dynamic_loss_scaling", False)
diff --git a/tools/export_center.py b/tools/export_center.py
index 30b9c33499b8d0c8044682c6a078e00f683c1d7c..3f7a883528525bebe037de7f78847fd77a059142 100644
--- a/tools/export_center.py
+++ b/tools/export_center.py
@@ -24,7 +24,7 @@ __dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
from ppocr.utils.save_load import load_model
@@ -40,6 +40,7 @@ def main():
'data_dir']
config['Eval']['dataset']['label_file_list'] = config['Train']['dataset'][
'label_file_list']
+ set_signal_handlers()
eval_dataloader = build_dataloader(config, 'Eval', device, logger)
# build post process
diff --git a/tools/export_model.py b/tools/export_model.py
index 4b90fcae435619a53a3def8cc4dc46b4e2963bff..cc515164bf64f0038856a3b97975562335eb1dc2 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -62,17 +62,17 @@ def export_single_model(model,
shape=[None], dtype="float32")]
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] in ["SVTR_LCNet", "SVTR_HGNet"]:
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 48, -1], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "SVTR":
- if arch_config["Head"]["name"] == 'MultiHead':
- other_shape = [
- paddle.static.InputSpec(
- shape=[None, 3, 48, -1], dtype="float32"),
- ]
- else:
- other_shape = [
- paddle.static.InputSpec(
- shape=[None] + input_shape, dtype="float32"),
- ]
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None] + input_shape, dtype="float32"),
+ ]
model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
other_shape = [
@@ -105,6 +105,12 @@ def export_single_model(model,
shape=[None, 1, 32, 100], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == 'SATRN':
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 32, 100], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "VisionLAN":
other_shape = [
paddle.static.InputSpec(
@@ -181,6 +187,13 @@ def export_single_model(model,
shape=[None] + infer_shape, dtype="float32")
])
+ if arch_config["model_type"] != "sr" and arch_config["Backbone"][
+ "name"] == "PPLCNetV3":
+ # for rep lcnetv3
+ for layer in model.sublayers():
+ if hasattr(layer, "rep") and not getattr(layer, "is_repped"):
+ layer.rep()
+
if quanter is None:
paddle.jit.save(model, save_path)
else:
@@ -212,8 +225,12 @@ def main():
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -228,8 +245,11 @@ def main():
char_num = len(getattr(post_process_class, 'character'))
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
diff --git a/tools/infer/predict_det.py b/tools/infer/predict_det.py
index 1b4446a6717bccdc5b3de4ba70e058885479be84..6c5c36cf86febef406609bf5022cfd2ee776756f 100755
--- a/tools/infer/predict_det.py
+++ b/tools/infer/predict_det.py
@@ -143,7 +143,9 @@ class TextDetector(object):
if self.use_onnx:
img_h, img_w = self.input_tensor.shape[2:]
- if img_h is not None and img_w is not None and img_h > 0 and img_w > 0:
+ if isinstance(img_h, str) or isinstance(img_w, str):
+ pass
+ elif img_h is not None and img_w is not None and img_h > 0 and img_w > 0:
pre_process_list[0] = {
'DetResizeForTest': {
'image_shape': [img_h, img_w]
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index b3ef557c09fb74990b65c266afa5d5c77960b7ed..9dd33dc7b68e05cc218a9a0746cb58ccb5a8ebb2 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -106,6 +106,13 @@ class TextRecognizer(object):
"character_dict_path": None,
"use_space_char": args.use_space_char
}
+ elif self.rec_algorithm == "SATRN":
+ postprocess_params = {
+ 'name': 'SATRNLabelDecode',
+ "character_dict_path": args.rec_char_dict_path,
+ "use_space_char": args.use_space_char,
+ "rm_symbol": True
+ }
elif self.rec_algorithm == "PREN":
postprocess_params = {'name': 'PRENLabelDecode'}
elif self.rec_algorithm == "CAN":
@@ -116,6 +123,7 @@ class TextRecognizer(object):
"use_space_char": args.use_space_char
}
self.postprocess_op = build_post_process(postprocess_params)
+ self.postprocess_params = postprocess_params
self.predictor, self.input_tensor, self.output_tensors, self.config = \
utility.create_predictor(args, 'rec', logger)
self.benchmark = args.benchmark
@@ -139,6 +147,7 @@ class TextRecognizer(object):
],
warmup=0,
logger=logger)
+ self.return_word_box = args.return_word_box
def resize_norm_img(self, img, max_wh_ratio):
imgC, imgH, imgW = self.rec_image_shape
@@ -149,7 +158,7 @@ class TextRecognizer(object):
if self.rec_algorithm == 'ViTSTR':
img = image_pil.resize([imgW, imgH], Image.BICUBIC)
else:
- img = image_pil.resize([imgW, imgH], Image.ANTIALIAS)
+ img = image_pil.resize([imgW, imgH], Image.Resampling.LANCZOS)
img = np.array(img)
norm_img = np.expand_dims(img, -1)
norm_img = norm_img.transpose((2, 0, 1))
@@ -173,9 +182,10 @@ class TextRecognizer(object):
imgW = int((imgH * max_wh_ratio))
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
- if w is not None and w > 0:
+ if isinstance(w, str):
+ pass
+ elif w is not None and w > 0:
imgW = w
-
h, w = img.shape[:2]
ratio = w / float(h)
if math.ceil(imgH * ratio) > imgW:
@@ -407,11 +417,12 @@ class TextRecognizer(object):
valid_ratios = []
imgC, imgH, imgW = self.rec_image_shape[:3]
max_wh_ratio = imgW / imgH
- # max_wh_ratio = 0
+ wh_ratio_list = []
for ino in range(beg_img_no, end_img_no):
h, w = img_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
+ wh_ratio_list.append(wh_ratio)
for ino in range(beg_img_no, end_img_no):
if self.rec_algorithm == "SAR":
norm_img, _, _, valid_ratio = self.resize_norm_img_sar(
@@ -428,7 +439,7 @@ class TextRecognizer(object):
gsrm_slf_attn_bias1_list.append(norm_img[3])
gsrm_slf_attn_bias2_list.append(norm_img[4])
norm_img_batch.append(norm_img[0])
- elif self.rec_algorithm == "SVTR":
+ elif self.rec_algorithm in ["SVTR", "SATRN"]:
norm_img = self.resize_norm_img_svtr(img_list[indices[ino]],
self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
@@ -616,7 +627,10 @@ class TextRecognizer(object):
preds = outputs
else:
preds = outputs[0]
- rec_result = self.postprocess_op(preds)
+ if self.postprocess_params['name'] == 'CTCLabelDecode':
+ rec_result = self.postprocess_op(preds, return_word_box=self.return_word_box, wh_ratio_list=wh_ratio_list, max_wh_ratio=max_wh_ratio)
+ else:
+ rec_result = self.postprocess_op(preds)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
if self.benchmark:
diff --git a/tools/infer/predict_system.py b/tools/infer/predict_system.py
index affd0d1bcd1283be02ead3cd61c01c375b49bdf9..8af45b4cf52eb6355c9d4e08bc609e6ea91dfb43 100755
--- a/tools/infer/predict_system.py
+++ b/tools/infer/predict_system.py
@@ -34,7 +34,7 @@ import tools.infer.predict_det as predict_det
import tools.infer.predict_cls as predict_cls
from ppocr.utils.utility import get_image_file_list, check_and_read
from ppocr.utils.logging import get_logger
-from tools.infer.utility import draw_ocr_box_txt, get_rotate_crop_image
+from tools.infer.utility import draw_ocr_box_txt, get_rotate_crop_image, get_minarea_rect_crop
logger = get_logger()
@@ -65,40 +65,53 @@ class TextSystem(object):
self.crop_image_res_index += bbox_num
def __call__(self, img, cls=True):
- time_dict = {'det': 0, 'rec': 0, 'csl': 0, 'all': 0}
+ time_dict = {'det': 0, 'rec': 0, 'cls': 0, 'all': 0}
+
+ if img is None:
+ logger.debug("no valid image provided")
+ return None, None, time_dict
+
start = time.time()
ori_im = img.copy()
dt_boxes, elapse = self.text_detector(img)
time_dict['det'] = elapse
- logger.debug("dt_boxes num : {}, elapse : {}".format(
- len(dt_boxes), elapse))
+
if dt_boxes is None:
- return None, None
+ logger.debug("no dt_boxes found, elapsed : {}".format(elapse))
+ end = time.time()
+ time_dict['all'] = end - start
+ return None, None, time_dict
+ else:
+ logger.debug("dt_boxes num : {}, elapsed : {}".format(
+ len(dt_boxes), elapse))
img_crop_list = []
dt_boxes = sorted_boxes(dt_boxes)
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
- img_crop = get_rotate_crop_image(ori_im, tmp_box)
+ if self.args.det_box_type == "quad":
+ img_crop = get_rotate_crop_image(ori_im, tmp_box)
+ else:
+ img_crop = get_minarea_rect_crop(ori_im, tmp_box)
img_crop_list.append(img_crop)
if self.use_angle_cls and cls:
img_crop_list, angle_list, elapse = self.text_classifier(
img_crop_list)
time_dict['cls'] = elapse
- logger.debug("cls num : {}, elapse : {}".format(
+ logger.debug("cls num : {}, elapsed : {}".format(
len(img_crop_list), elapse))
rec_res, elapse = self.text_recognizer(img_crop_list)
time_dict['rec'] = elapse
- logger.debug("rec_res num : {}, elapse : {}".format(
+ logger.debug("rec_res num : {}, elapsed : {}".format(
len(rec_res), elapse))
if self.args.save_crop_res:
self.draw_crop_rec_res(self.args.crop_res_save_dir, img_crop_list,
rec_res)
filter_boxes, filter_rec_res = [], []
for box, rec_result in zip(dt_boxes, rec_res):
- text, score = rec_result
+ text, score = rec_result[0], rec_result[1]
if score >= self.drop_score:
filter_boxes.append(box)
filter_rec_res.append(rec_result)
@@ -120,7 +133,7 @@ def sorted_boxes(dt_boxes):
_boxes = list(sorted_boxes)
for i in range(num_boxes - 1):
- for j in range(i, 0, -1):
+ for j in range(i, -1, -1):
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and \
(_boxes[j + 1][0][0] < _boxes[j][0][0]):
tmp = _boxes[j]
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index 34cad2590f2904f79709530acf841033c89088e0..b064cbf18941a40bdca57e4d7e4ec68dc42e6fc6 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -19,6 +19,7 @@ import platform
import cv2
import numpy as np
import paddle
+import PIL
from PIL import Image, ImageDraw, ImageFont
import math
from paddle import inference
@@ -28,8 +29,10 @@ from ppocr.utils.logging import get_logger
def str2bool(v):
- return v.lower() in ("true", "t", "1")
+ return v.lower() in ("true", "yes", "t", "y", "1")
+def str2int_tuple(v):
+ return tuple([int(i.strip()) for i in v.split(",")])
def init_args():
parser = argparse.ArgumentParser()
@@ -42,6 +45,7 @@ def init_args():
parser.add_argument("--min_subgraph_size", type=int, default=15)
parser.add_argument("--precision", type=str, default="fp32")
parser.add_argument("--gpu_mem", type=int, default=500)
+ parser.add_argument("--gpu_id", type=int, default=0)
# params for text detector
parser.add_argument("--image_dir", type=str)
@@ -144,6 +148,10 @@ def init_args():
parser.add_argument("--show_log", type=str2bool, default=True)
parser.add_argument("--use_onnx", type=str2bool, default=False)
+
+ # extended function
+ parser.add_argument("--return_word_box", type=str2bool, default=False, help='Whether return the bbox of each word (split by space) or chinese character. Only used in ppstructure for layout recovery')
+
return parser
@@ -181,7 +189,10 @@ def create_predictor(args, mode, logger):
if not os.path.exists(model_file_path):
raise ValueError("not find model file path {}".format(
model_file_path))
- sess = ort.InferenceSession(model_file_path)
+ if args.use_gpu:
+ sess = ort.InferenceSession(model_file_path, providers=['CUDAExecutionProvider'])
+ else:
+ sess = ort.InferenceSession(model_file_path)
return sess, sess.get_inputs()[0], None, None
else:
@@ -219,7 +230,7 @@ def create_predictor(args, mode, logger):
logger.warning(
"GPU is not found in current device by nvidia-smi. Please check your device or ignore it if run on jetson."
)
- config.enable_use_gpu(args.gpu_mem, 0)
+ config.enable_use_gpu(args.gpu_mem, args.gpu_id)
if args.use_tensorrt:
config.enable_tensorrt_engine(
workspace_size=1 << 30,
@@ -245,7 +256,7 @@ def create_predictor(args, mode, logger):
logger.info("Please keep your paddlepaddle-gpu >= 2.3.0!")
elif args.use_npu:
- config.enable_npu()
+ config.enable_custom_device("npu")
elif args.use_xpu:
config.enable_xpu(10 * 1024 * 1024)
else:
@@ -290,7 +301,9 @@ def create_predictor(args, mode, logger):
def get_output_tensors(args, mode, predictor):
output_names = predictor.get_output_names()
output_tensors = []
- if mode == "rec" and args.rec_algorithm in ["CRNN", "SVTR_LCNet"]:
+ if mode == "rec" and args.rec_algorithm in [
+ "CRNN", "SVTR_LCNet", "SVTR_HGNet"
+ ]:
output_name = 'softmax_0.tmp_0'
if output_name in output_names:
return [predictor.get_output_handle(output_name)]
@@ -310,7 +323,7 @@ def get_infer_gpuid():
if sysstr == "Windows":
return 0
- if not paddle.fluid.core.is_compiled_with_rocm():
+ if not paddle.device.is_compiled_with_rocm:
cmd = "env | grep CUDA_VISIBLE_DEVICES"
else:
cmd = "env | grep HIP_VISIBLE_DEVICES"
@@ -468,7 +481,11 @@ def draw_box_txt_fine(img_size, box, txt, font_path="./doc/fonts/simfang.ttf"):
def create_font(txt, sz, font_path="./doc/fonts/simfang.ttf"):
font_size = int(sz[1] * 0.99)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
- length = font.getsize(txt)[0]
+ if int(PIL.__version__.split('.')[0]) < 10:
+ length = font.getsize(txt)[0]
+ else:
+ length = font.getlength(txt)
+
if length > sz[0]:
font_size = int(font_size * sz[0] / length)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
@@ -629,6 +646,29 @@ def get_rotate_crop_image(img, points):
return dst_img
+def get_minarea_rect_crop(img, points):
+ bounding_box = cv2.minAreaRect(np.array(points).astype(np.int32))
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_a, index_b, index_c, index_d = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_a = 0
+ index_d = 1
+ else:
+ index_a = 1
+ index_d = 0
+ if points[3][1] > points[2][1]:
+ index_b = 2
+ index_c = 3
+ else:
+ index_b = 3
+ index_c = 2
+
+ box = [points[index_a], points[index_b], points[index_c], points[index_d]]
+ crop_img = get_rotate_crop_image(img, np.array(box))
+ return crop_img
+
+
def check_gpu(use_gpu):
if use_gpu and not paddle.is_compiled_with_cuda():
use_gpu = False
diff --git a/tools/infer_det.py b/tools/infer_det.py
index f253e8f2876a5942538f18e93dfdada4391875b2..097d032b99c7d25a3e9e3b1d781bbdbe4dde62fa 100755
--- a/tools/infer_det.py
+++ b/tools/infer_det.py
@@ -40,17 +40,16 @@ import tools.program as program
def draw_det_res(dt_boxes, config, img, img_name, save_path):
- if len(dt_boxes) > 0:
- import cv2
- src_im = img
- for box in dt_boxes:
- box = np.array(box).astype(np.int32).reshape((-1, 1, 2))
- cv2.polylines(src_im, [box], True, color=(255, 255, 0), thickness=2)
- if not os.path.exists(save_path):
- os.makedirs(save_path)
- save_path = os.path.join(save_path, os.path.basename(img_name))
- cv2.imwrite(save_path, src_im)
- logger.info("The detected Image saved in {}".format(save_path))
+ import cv2
+ src_im = img
+ for box in dt_boxes:
+ box = np.array(box).astype(np.int32).reshape((-1, 1, 2))
+ cv2.polylines(src_im, [box], True, color=(255, 255, 0), thickness=2)
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+ save_path = os.path.join(save_path, os.path.basename(img_name))
+ cv2.imwrite(save_path, src_im)
+ logger.info("The detected Image saved in {}".format(save_path))
@paddle.no_grad()
diff --git a/tools/infer_kie_token_ser_re.py b/tools/infer_kie_token_ser_re.py
index c4fa2c927ab93cfa9082e51f08f8d6e1c35fe29e..76120a913f36c815cbd3b9314523ea91e3290065 100755
--- a/tools/infer_kie_token_ser_re.py
+++ b/tools/infer_kie_token_ser_re.py
@@ -81,7 +81,7 @@ def make_input(ser_inputs, ser_results):
end.append(entity['end'])
label.append(entities_labels[res['pred']])
- entities = np.full([max_seq_len + 1, 3], fill_value=-1)
+ entities = np.full([max_seq_len + 1, 3], fill_value=-1, dtype=np.int64)
entities[0, 0] = len(start)
entities[1:len(start) + 1, 0] = start
entities[0, 1] = len(end)
@@ -98,7 +98,7 @@ def make_input(ser_inputs, ser_results):
head.append(i)
tail.append(j)
- relations = np.full([len(head) + 1, 2], fill_value=-1)
+ relations = np.full([len(head) + 1, 2], fill_value=-1, dtype=np.int64)
relations[0, 0] = len(head)
relations[1:len(head) + 1, 0] = head
relations[0, 1] = len(tail)
diff --git a/tools/infer_rec.py b/tools/infer_rec.py
index 29aab9b57853b16bf615c893c30351a403270b57..80986ccdebb5b0e91cb843933c1a0ee6914ca671 100755
--- a/tools/infer_rec.py
+++ b/tools/infer_rec.py
@@ -48,34 +48,41 @@ def main():
# build model
if hasattr(post_process_class, 'character'):
char_num = len(getattr(post_process_class, 'character'))
- if config['Architecture']["algorithm"] in ["Distillation",
+ if config["Architecture"]["algorithm"] in ["Distillation",
]: # distillation model
- for key in config['Architecture']["Models"]:
- if config['Architecture']['Models'][key]['Head'][
- 'name'] == 'MultiHead': # for multi head
+ for key in config["Architecture"]["Models"]:
+ if config["Architecture"]["Models"][key]["Head"][
+ "name"] == 'MultiHead': # multi head
out_channels_list = {}
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ config["Architecture"]["Models"][key]["Head"][
+ "out_channels"] = char_num
elif config['Architecture']['Head'][
- 'name'] == 'MultiHead': # for multi head loss
+ 'name'] == 'MultiHead': # multi head
out_channels_list = {}
+ char_num = len(getattr(post_process_class, 'character'))
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list['CTCLabelDecode'] = char_num
out_channels_list['SARLabelDecode'] = char_num + 2
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
- config['Architecture']["Head"]['out_channels'] = char_num
-
+ config["Architecture"]["Head"]["out_channels"] = char_num
model = build_model(config['Architecture'])
load_model(config, model)
diff --git a/tools/program.py b/tools/program.py
index afb8a47254b9847e4a4d432b7f17902c3ee78725..511ee9dd1f12273eb773b6f2e29a3955940721ee 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -134,9 +134,18 @@ def check_device(use_gpu, use_xpu=False, use_npu=False, use_mlu=False):
if use_xpu and not paddle.device.is_compiled_with_xpu():
print(err.format("use_xpu", "xpu", "xpu", "use_xpu"))
sys.exit(1)
- if use_npu and not paddle.device.is_compiled_with_npu():
- print(err.format("use_npu", "npu", "npu", "use_npu"))
- sys.exit(1)
+ if use_npu:
+ if int(paddle.version.major) != 0 and int(
+ paddle.version.major) <= 2 and int(
+ paddle.version.minor) <= 4:
+ if not paddle.device.is_compiled_with_npu():
+ print(err.format("use_npu", "npu", "npu", "use_npu"))
+ sys.exit(1)
+ # is_compiled_with_npu() has been updated after paddle-2.4
+ else:
+ if not paddle.device.is_compiled_with_custom_device("npu"):
+ print(err.format("use_npu", "npu", "npu", "use_npu"))
+ sys.exit(1)
if use_mlu and not paddle.device.is_compiled_with_mlu():
print(err.format("use_mlu", "mlu", "mlu", "use_mlu"))
sys.exit(1)
@@ -179,7 +188,9 @@ def train(config,
log_writer=None,
scaler=None,
amp_level='O2',
- amp_custom_black_list=[]):
+ amp_custom_black_list=[],
+ amp_custom_white_list=[],
+ amp_dtype='float16'):
cal_metric_during_train = config['Global'].get('cal_metric_during_train',
False)
calc_epoch_interval = config['Global'].get('calc_epoch_interval', 1)
@@ -219,8 +230,8 @@ def train(config,
use_srn = config['Architecture']['algorithm'] == "SRN"
extra_input_models = [
- "SRN", "NRTR", "SAR", "SEED", "SVTR", "SPIN", "VisionLAN",
- "RobustScanner", "RFL", 'DRRG'
+ "SRN", "NRTR", "SAR", "SEED", "SVTR", "SVTR_LCNet", "SPIN", "VisionLAN",
+ "RobustScanner", "RFL", 'DRRG', 'SATRN', 'SVTR_HGNet'
]
extra_input = False
if config['Architecture']['algorithm'] == 'Distillation':
@@ -268,7 +279,9 @@ def train(config,
if scaler:
with paddle.amp.auto_cast(
level=amp_level,
- custom_black_list=amp_custom_black_list):
+ custom_black_list=amp_custom_black_list,
+ custom_white_list=amp_custom_white_list,
+ dtype=amp_dtype):
if model_type == 'table' or extra_input:
preds = model(images, data=batch[1:])
elif model_type in ["kie"]:
@@ -333,7 +346,10 @@ def train(config,
lr_scheduler.step()
# logger and visualdl
- stats = {k: v.numpy().mean() for k, v in loss.items()}
+ stats = {
+ k: float(v) if v.shape == [] else v.numpy().mean()
+ for k, v in loss.items()
+ }
stats['lr'] = lr
train_stats.update(stats)
@@ -382,7 +398,9 @@ def train(config,
extra_input=extra_input,
scaler=scaler,
amp_level=amp_level,
- amp_custom_black_list=amp_custom_black_list)
+ amp_custom_black_list=amp_custom_black_list,
+ amp_custom_white_list=amp_custom_white_list,
+ amp_dtype=amp_dtype)
cur_metric_str = 'cur metric, {}'.format(', '.join(
['{}: {}'.format(k, v) for k, v in cur_metric.items()]))
logger.info(cur_metric_str)
@@ -475,7 +493,9 @@ def eval(model,
extra_input=False,
scaler=None,
amp_level='O2',
- amp_custom_black_list=[]):
+ amp_custom_black_list=[],
+ amp_custom_white_list=[],
+ amp_dtype='float16'):
model.eval()
with paddle.no_grad():
total_frame = 0.0
@@ -498,7 +518,8 @@ def eval(model,
if scaler:
with paddle.amp.auto_cast(
level=amp_level,
- custom_black_list=amp_custom_black_list):
+ custom_black_list=amp_custom_black_list,
+ dtype=amp_dtype):
if model_type == 'table' or extra_input:
preds = model(images, data=batch[1:])
elif model_type in ["kie"]:
@@ -641,9 +662,9 @@ def preprocess(is_train=False):
'EAST', 'DB', 'SAST', 'Rosetta', 'CRNN', 'STARNet', 'RARE', 'SRN',
'CLS', 'PGNet', 'Distillation', 'NRTR', 'TableAttn', 'SAR', 'PSE',
'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'LayoutLMv2', 'PREN', 'FCE',
- 'SVTR', 'ViTSTR', 'ABINet', 'DB++', 'TableMaster', 'SPIN', 'VisionLAN',
- 'Gestalt', 'SLANet', 'RobustScanner', 'CT', 'RFL', 'DRRG', 'CAN',
- 'Telescope'
+ 'SVTR', 'SVTR_LCNet', 'ViTSTR', 'ABINet', 'DB++', 'TableMaster', 'SPIN',
+ 'VisionLAN', 'Gestalt', 'SLANet', 'RobustScanner', 'CT', 'RFL', 'DRRG',
+ 'CAN', 'Telescope', 'SATRN', 'SVTR_HGNet'
]
if use_xpu:
@@ -665,7 +686,7 @@ def preprocess(is_train=False):
if 'use_visualdl' in config['Global'] and config['Global']['use_visualdl']:
save_model_dir = config['Global']['save_model_dir']
- vdl_writer_path = '{}/vdl/'.format(save_model_dir)
+ vdl_writer_path = save_model_dir
log_writer = VDLLogger(vdl_writer_path)
loggers.append(log_writer)
if ('use_wandb' in config['Global'] and
diff --git a/tools/train.py b/tools/train.py
index ff261e85fec10ec974ff763d6c3747faaa47c8d9..85c98eaddfe69c08e0e29921edcb1d26539b871f 100755
--- a/tools/train.py
+++ b/tools/train.py
@@ -27,7 +27,7 @@ import yaml
import paddle
import paddle.distributed as dist
-from ppocr.data import build_dataloader
+from ppocr.data import build_dataloader, set_signal_handlers
from ppocr.modeling.architectures import build_model
from ppocr.losses import build_loss
from ppocr.optimizer import build_optimizer
@@ -41,7 +41,7 @@ import tools.program as program
dist.get_world_size()
-def main(config, device, logger, vdl_writer):
+def main(config, device, logger, vdl_writer, seed):
# init dist environment
if config['Global']['distributed']:
dist.init_parallel_env()
@@ -49,7 +49,8 @@ def main(config, device, logger, vdl_writer):
global_config = config['Global']
# build dataloader
- train_dataloader = build_dataloader(config, 'Train', device, logger)
+ set_signal_handlers()
+ train_dataloader = build_dataloader(config, 'Train', device, logger, seed)
if len(train_dataloader) == 0:
logger.error(
"No Images in train dataset, please ensure\n" +
@@ -60,7 +61,7 @@ def main(config, device, logger, vdl_writer):
return
if config['Eval']:
- valid_dataloader = build_dataloader(config, 'Eval', device, logger)
+ valid_dataloader = build_dataloader(config, 'Eval', device, logger, seed)
else:
valid_dataloader = None
@@ -80,14 +81,22 @@ def main(config, device, logger, vdl_writer):
if config['PostProcess'][
'name'] == 'DistillationSARLabelDecode':
char_num = char_num - 2
- # update SARLoss params
- assert list(config['Loss']['loss_config_list'][-1].keys())[
- 0] == 'DistillationSARLoss'
- config['Loss']['loss_config_list'][-1][
- 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ if config['PostProcess'][
+ 'name'] == 'DistillationNRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list = {}
out_channels_list['CTCLabelDecode'] = char_num
- out_channels_list['SARLabelDecode'] = char_num + 2
+ # update SARLoss params
+ if list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss':
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ elif list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationNRTRLoss':
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
+
config['Architecture']['Models'][key]['Head'][
'out_channels_list'] = out_channels_list
else:
@@ -97,19 +106,24 @@ def main(config, device, logger, vdl_writer):
'name'] == 'MultiHead': # for multi head
if config['PostProcess']['name'] == 'SARLabelDecode':
char_num = char_num - 2
- # update SARLoss params
- assert list(config['Loss']['loss_config_list'][1].keys())[
- 0] == 'SARLoss'
- if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
- config['Loss']['loss_config_list'][1]['SARLoss'] = {
- 'ignore_index': char_num + 1
- }
- else:
- config['Loss']['loss_config_list'][1]['SARLoss'][
- 'ignore_index'] = char_num + 1
+ if config['PostProcess']['name'] == 'NRTRLabelDecode':
+ char_num = char_num - 3
out_channels_list = {}
out_channels_list['CTCLabelDecode'] = char_num
- out_channels_list['SARLabelDecode'] = char_num + 2
+ # update SARLoss params
+ if list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss':
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ elif list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'NRTRLoss':
+ out_channels_list['NRTRLabelDecode'] = char_num + 3
config['Architecture']['Head'][
'out_channels_list'] = out_channels_list
else: # base rec model
@@ -147,14 +161,17 @@ def main(config, device, logger, vdl_writer):
use_amp = config["Global"].get("use_amp", False)
amp_level = config["Global"].get("amp_level", 'O2')
+ amp_dtype = config["Global"].get("amp_dtype", 'float16')
amp_custom_black_list = config['Global'].get('amp_custom_black_list', [])
+ amp_custom_white_list = config['Global'].get('amp_custom_white_list', [])
if use_amp:
AMP_RELATED_FLAGS_SETTING = {'FLAGS_max_inplace_grad_add': 8, }
if paddle.is_compiled_with_cuda():
AMP_RELATED_FLAGS_SETTING.update({
- 'FLAGS_cudnn_batchnorm_spatial_persistent': 1
+ 'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
+ 'FLAGS_gemm_use_half_precision_compute_type': 0,
})
- paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
+ paddle.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["Global"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["Global"].get(
"use_dynamic_loss_scaling", False)
@@ -166,7 +183,8 @@ def main(config, device, logger, vdl_writer):
models=model,
optimizers=optimizer,
level=amp_level,
- master_weight=True)
+ master_weight=True,
+ dtype=amp_dtype)
else:
scaler = None
@@ -180,7 +198,8 @@ def main(config, device, logger, vdl_writer):
program.train(config, train_dataloader, valid_dataloader, device, model,
loss_class, optimizer, lr_scheduler, post_process_class,
eval_class, pre_best_model_dict, logger, vdl_writer, scaler,
- amp_level, amp_custom_black_list)
+ amp_level, amp_custom_black_list, amp_custom_white_list,
+ amp_dtype)
def test_reader(config, device, logger):
@@ -205,5 +224,5 @@ if __name__ == '__main__':
config, device, logger, vdl_writer = program.preprocess(is_train=True)
seed = config['Global']['seed'] if 'seed' in config['Global'] else 1024
set_seed(seed)
- main(config, device, logger, vdl_writer)
+ main(config, device, logger, vdl_writer, seed)
# test_reader(config, device, logger)
| |
 @@ -13,195 +13,220 @@ English | [简体中文](README_ch.md) | [हिन्दी](./doc/doc_i18n/REA
@@ -13,195 +13,220 @@ English | [简体中文](README_ch.md) | [हिन्दी](./doc/doc_i18n/REA

 +
+ 

 +
+ 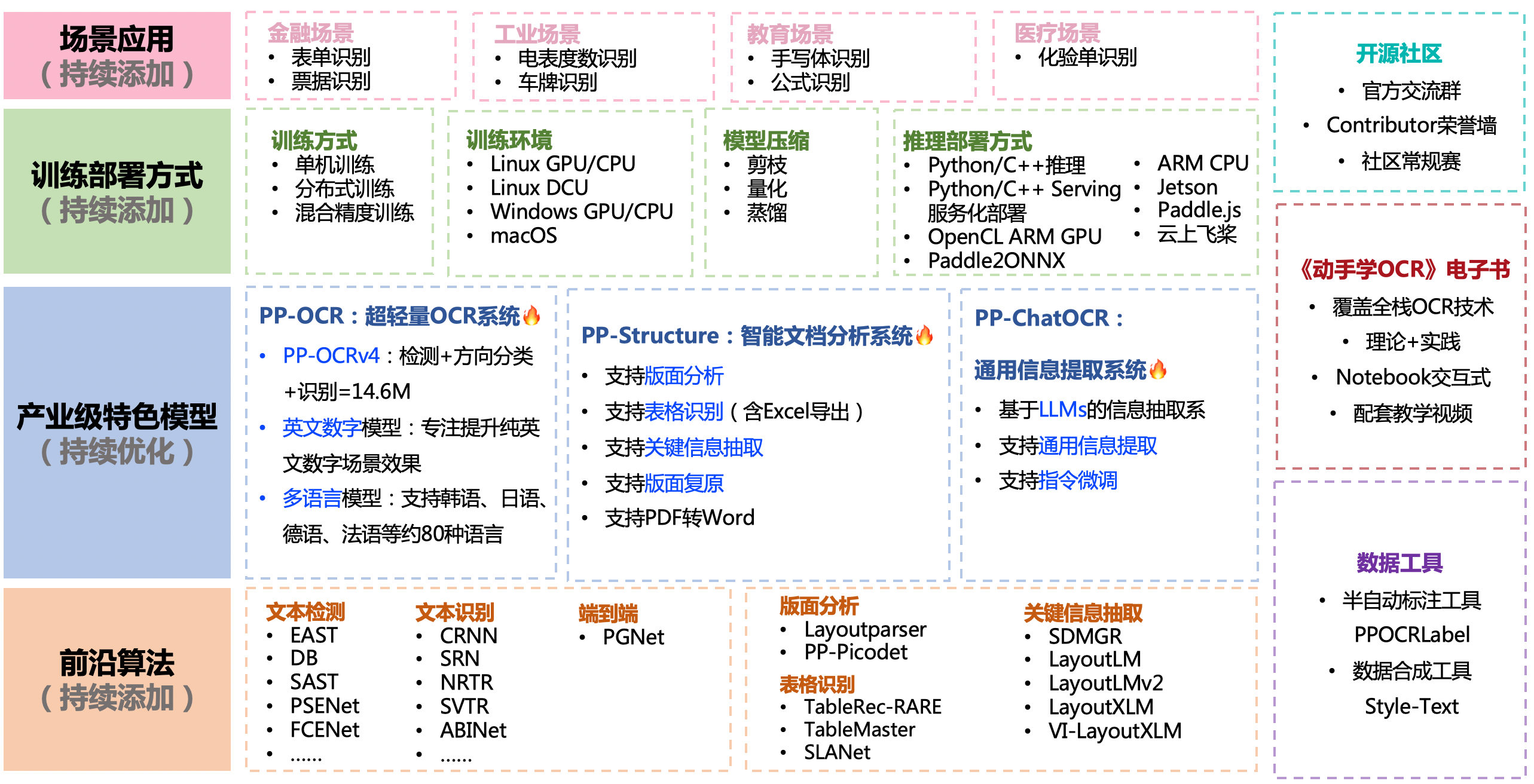
 -
- +
+ +
+







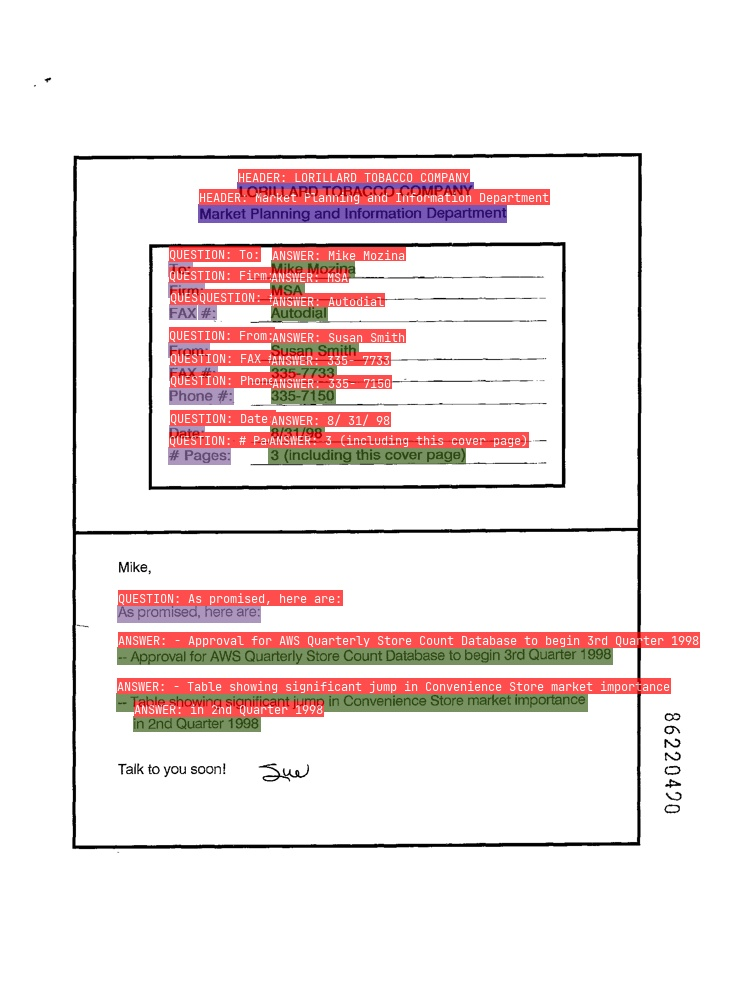 -
-
 -- RE (Relation Extraction)
-- RE (Relation Extraction)
 -
-
 -
-


 -
- +
+
+
+ +
+