Inference
diff --git a/tutorials/source_en/model_infer/images/model_infer_case_select.png b/tutorials/source_en/model_infer/images/model_infer_case_select.png
new file mode 100644
index 0000000000000000000000000000000000000000..0eaa4803ed22d939e178c60571fdc6a5d36a058b
Binary files /dev/null and b/tutorials/source_en/model_infer/images/model_infer_case_select.png differ
diff --git a/tutorials/source_en/model_infer/images/model_infer_stack.png b/tutorials/source_en/model_infer/images/model_infer_stack.png
new file mode 100644
index 0000000000000000000000000000000000000000..a902e358cf176ec5b420aa99ff338fd1c34f92b5
Binary files /dev/null and b/tutorials/source_en/model_infer/images/model_infer_stack.png differ
diff --git a/tutorials/source_en/model_infer/introduction.md b/tutorials/source_en/model_infer/introduction.md
new file mode 100644
index 0000000000000000000000000000000000000000..f02a2a2cc765e40a949e4d1f3ee5c91bd1911e13
--- /dev/null
+++ b/tutorials/source_en/model_infer/introduction.md
@@ -0,0 +1,77 @@
+# MindSpore Inference Overview
+
+[](https://gitee.com/mindspore/docs/blob/master/tutorials/source_en/model_infer/introduction.md)
+
+## Context
+
+MindSpore provides efficient model inference capabilities. From the perspective of AI functions, inference is actually a forward computing of a model using real service data of users. Therefore, the forward computing graph of the MindSpore model can complete the basic functions of inference. However, in actual applications, the purposes of model inference and training are different, and the technologies used for model inference and training are also different.
+
+- Although model training also requires forward computing, the core purpose of training computing is to compute the inference result based on the existing data set, obtain the intermediate result, and update the weight parameters of the model to optimize the model.
+
+- Model inference is to use data in the actual production environment to perform inference and prediction under the condition that the model weight parameters are fixed, and obtain the results required by actual services.
+
+To maximize the model prediction efficiency, model inference needs to provide the following core capabilities:
+
+- **Cost-effectiveness**: In the production environment, the computing cost of AI models is high. Therefore, the model inference capability needs to complete more computing tasks with fewer computing resources. The AI framework needs to provide lower response latency and higher system throughput to reduce the model inference cost.
+
+- **Efficient deployment**: In the actual production environment, AI model deployment is complex, involving model weight preparation, model script, and backend adaptation. The ability to quickly deploy AI models to the production environment is one of the important indicators of the inference capability of the AI framework.
+
+The inference capability required by a model varies with scenarios. Based on common application scenarios in the actual production environment, the inference types are classified as follows:
+
+- **By computing resource**
+
+ - **Cloud inference**: With the development of cloud computing, computing resources in DCs are becoming increasingly abundant. In the cloud environment, computing resources are usually sufficient. Therefore, cloud inference usually indicates a scenario with abundant computing resources. The AI framework can be completely deployed in the production environment. In addition, the framework has high requirements on distributed parallel capabilities and focuses on the system throughput of AI model inference.
+
+ - **Device inference**: On edges and devices, the AI framework cannot be directly deployed in the production environment due to insufficient computing resources. Therefore, a more lightweight model runtime is required. The number of concurrent tasks is not particularly high, but the response latency of AI model inference is the concern.
+
+- **By inference model format**
+
+ - **Inference with a framework**: The model network structure and model weight file are saved separately. You can build a network and separately load the model weight to build AI model inference. The advantage of this type of inference is that the inference weight does not need to be updated, regardless of whether the model is fine-tuned, optimized, or developed and debugged, this inference solution has obvious advantages when the weight of the current LLM reaches hundreds of GB.
+
+ - **Inference with a model file**: The model network and weight are packed into a file (ProtoBuf or FlatBed file). You only need to manage one file to execute the model. This inference solution is convenient for deployment management when there are a large number of models and the model size is not large.
+
+- **By inference backend**
+
+ - **Online inference**: After a model is loaded, the model receives inference requests and calls the model backend for inference. The service backend is also supported. This is a common application deployment mode of AI model services.
+
+ - **Offline inference**: Requests and data are loaded using scripts. Inference is performed for a specific number of times, mostly during model debugging, or integrated as model inference of other service backends.
+
+## MindSpore Inference Solution
+
+The MindSpore framework provides multiple model inference modes so that users can select the optimal inference mode as required in different scenarios. The following lists the inference modes supported by MindSpore:
+
+- **MindSpore inference on the cloud**: This mode is mainly used in scenarios where cloud computing resources are abundant. The MindSpore framework depends on complete components (including dependency libraries such as Python and NumPy). Users can use all capabilities of the MindSpore framework for inference.
+
+ - **Inference with a framework**: The model weight file (CKPT or Safetensor file) and MindSpore network script are used for inference. The model structure can be flexibly adjusted according to requirements. In addition, both dynamic and static graph modes are supported. This inference mode is the main model development and debugging mode for LLMs.
+
+ - **MindIR model inference**: The MindIR file (official MindSpore file) is used for inference, which contains the network structure and weights. Model loading and inference are simpler, but the model cannot be adjusted and the MindIR file needs to be regenerated each time. This mode is not suitable for inference of models with large weights.
+
+ - **vLLM service-based inference**: The vLLM provides the service-based backend model inference capability, which can quickly deploy inference services. This mode is suitable for users who do not have their own service backends and can quickly implement inference services.
+
+- **Lite inference**: This mode is mainly used in scenarios where the computing resources on the device side are limited. The lightweight runtime reduces the resource requirements for model inference. The model file is in FlatBuffer format, implementing KB-level resource consumption for model inference and enabling the AI capability of devices such as mobile phones.
+
+The following figure shows the selection routes of common model inference scenarios.
+
+
+
+You can select the most suitable MindSpore inference solution based on your application scenario.
+
+The following figure shows the key technology stack of MindSpore inference.
+
+
+
+- **Inference with a framework**: In scenarios with abundant computing resources, only Python APIs are provided. You need to use Python scripts to build models and perform inference. Service-oriented components are not mandatory.
+
+ - **vLLM&vLLM-MindSpore**: The service-oriented capability of the inference solution with a framework is provided. The popular vLLM service-oriented inference capability in the open-source community is used to seamlessly connect the service-oriented capability of the community to the MindSpore inference ecosystem.
+
+ - **Python API**: MindSpore provides Python APIs, including mint operator APIs (consistent with PyTorch semantics), nn APIs, and parallel APIs.
+
+ - **Graph Mode**: It indicates the static graph mode. The graph compilation technology is used to optimize models, and the inference computing performance is high. However, model debugging is not intuitive. You are advised to enable this mode only if the model script is fixed.
+
+ - **PyNative Mode**: It indicates the dynamic graph mode. The Python interpreter is used to execute Python code in the model script one by one, which facilitates model debugging. However, the execution performance is lower than that of the static graph mode due to the Python calling overhead each time.
+
+ - **Runtime**: It indicates the core runtime of the MindSpore framework. The runtime provides parallel execution of the Actor mechanism, computing device management, and memory allocation.
+
+ - **Operator library**: MindSpore has built-in operator libraries for various computations. In inference scenarios, MindSpore also contains various fusion operators to improve inference performance.
+
+- **Lite inference**: It is oriented to devices with limited resources. The core is C++ runtime, and the resource consumption is less than 1 MB. Lite inference is suitable for devices such as mobile phones. In addition, Lite inference also provides Python APIs to meet different user requirements.
diff --git a/tutorials/source_en/model_infer/ms_infer/ms_infer_model_infer.rst b/tutorials/source_en/model_infer/ms_infer/ms_infer_model_infer.rst
index 3ec0aed33ef3640da7930c717e4c2d45d4105b96..b7f210325b54d93531bafbf5a853bcb095caee8f 100644
--- a/tutorials/source_en/model_infer/ms_infer/ms_infer_model_infer.rst
+++ b/tutorials/source_en/model_infer/ms_infer/ms_infer_model_infer.rst
@@ -94,9 +94,9 @@ To achieve the optimal cost-effectiveness, MindSpore LLM has undergone multiple
- **Attention optimization**: The primary computation in the LLM's network involves the computation of attention. Since the attention size in mainstream models is often large (typically 4096 x 4096 or more), the performance of the entire inference process heavily relies on the efficiency of attention computation. Many studies focus on optimizing the performance of attention computation, with notable techniques such as flash attention and page attention.
- - **Flash attention**: During attention computation, two large matrices (4096 x 4096) are multiplied. This computation breaks the large matrix into smaller matrices that can be processed on multiple chips. Subject to the minimum cache size of chips, data must continuously be moved between the cache and main memory. As a result, compute resources cannot be fully used. Consequently, attention computation is often bandwidth-bound. Flash attention addresses this by dividing attention into blocks, allowing each block to be computed independently on a chip, avoiding multiple data movements during the computation of KVs and enhancing attention computation performance. For details, see `Flash Attention
`_.
+ - **Flash Attention**: During attention computation, two large matrices (4096 x 4096) are multiplied. This computation breaks the large matrix into smaller matrices that can be processed on multiple chips. Subject to the minimum cache size of chips, data must continuously be moved between the cache and main memory. As a result, compute resources cannot be fully used. Consequently, attention computation is often bandwidth-bound. Flash attention addresses this by dividing attention into blocks, allowing each block to be computed independently on a chip, avoiding multiple data movements during the computation of KVs and enhancing attention computation performance. For details, see `Flash Attention `_.
- - **Page attention graphics memory optimization**: Standard flash attention reads and saves the entire input KV data each time. This method is simple but wastes many resources. For example, "China's capital" and "China's national flag" share "China's", leading to identical KVs for their attention. Standard flash attention needs to store two copies of KVs, wasting the graphics memory. Page attention optimizes KVCache based on the page table principle of the Linux OS. It stores KVs in blocks of a specific size. In the preceding example, "China", "'s", "capital", and "national flag" are stored as four pieces of KV data. Compared with the original six pieces of data, this method effectively saves graphics memory resources. In the service-oriented scenario, more idle graphics memory allows for a larger batch size for model inference, thereby achieving higher throughput. For details, see `Page Attention `_.
+ - **Paged Attention**: Standard Flash Attention reads and saves the entire input Key and Value data each time. Although this method is relatively simple, it causes a significant waste of resources. When multiple requests in a batch have inconsistent sequence lengths, Flash Attention requires the key and value to use the memory of the longest sequence. For example, "The capital of China is Beijing" and "The national flag of China is the Five-Star Red Flag", assuming that the words are divided by characters, 10 * 2 = 20 KVCache memory units are required. Paged attention optimizes KVCache based on the page table principle of the Linux OS. Store Key and Value data in blocks of a specific size. For example, when the block size is 2, you can use KVCache per block, only 4 * 2 + 5 * 2 = 18 KVCache memory units are required. Due to the discrete feature of Paged Attention, you can also combine it with technologies such as Prefix Cache to further reduce the memory occupied by "of China". Therefore only 3 * 2 + 5 * 2 = 16 KVCache units are ultimately required. In the service-oriented scenario, more idle graphics memory allows for a larger batch size for model inference, thereby achieving higher throughput. For details, see `Page Attention `_.
- **Model quantization**: MindSpore LLM inference supports quantization to reduce the model size. It provides technologies such as A16W8, A16W4, A8W8, and KVCache quantizations to reduce model resource usage and improve the inference throughput.
diff --git a/tutorials/source_en/parallel/dataset_slice.md b/tutorials/source_en/parallel/dataset_slice.md
index cecf49f7508f8e7a0bfc18c576a38089634a3980..a878165f18e02ec4b15c759a1609a763368ac46b 100644
--- a/tutorials/source_en/parallel/dataset_slice.md
+++ b/tutorials/source_en/parallel/dataset_slice.md
@@ -4,7 +4,7 @@
## Overview
-When performing distributed training, taking image data as an example, when the size of a single image is too large, such as large-format images of remote sensing satellites, when an image is too large, it is necessary to slice the image and read a portion of each card to perform distributed training. Scenarios that deal with dataset slicing need to be combined with model parallelism to achieve the desired effect of reducing video memory, so this feature is provided based on automatic parallelism. The sample used in this tutorial is not a large-format network, and is intended as an example only. Real-life applications to large-format networks often require detailed design of parallel strategies.
+When performing distributed training, taking image data as an example, when the size of a single image is too large, such as large-format images of remote sensing satellites, it is necessary to slice the image and read a portion of each card to perform distributed training. Scenarios that deal with dataset slicing need to be combined with model parallelism to achieve the desired effect of reducing video memory, so this feature is provided based on automatic parallelism. The sample used in this tutorial is not a large-format network, and is intended as an example only. Real-life applications to large-format networks often require detailed design of parallel strategies.
> Dataset sharding is not involved in data parallel mode.
diff --git a/tutorials/source_en/parallel/host_device_training.md b/tutorials/source_en/parallel/host_device_training.md
index 1f34264cb7a636941bab8047cb666f8f6a62c221..997d8643c1134b776248970dfcb1369ddad05ca1 100644
--- a/tutorials/source_en/parallel/host_device_training.md
+++ b/tutorials/source_en/parallel/host_device_training.md
@@ -10,7 +10,7 @@ In MindSpore, users can easily implement hybrid training by configuring trainabl
### Basic Principle
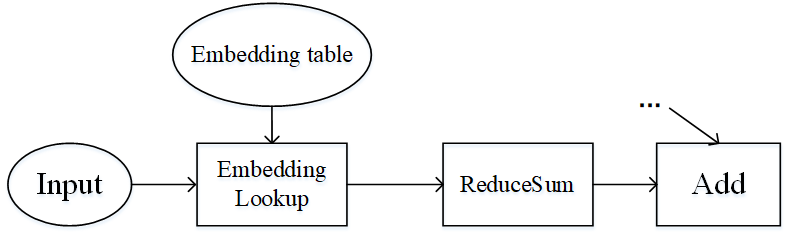
-Pipeline parallel and operator-level parallel are suitable for the model to have a large number of operators, and the parameters are more evenly distributed among the operators. What if the number of operators in the model is small, and the parameters are concentrated in only a few operators? Wide & Deep is an example of this, as shown in the image below. The Embedding table in Wide & Deep can be trained as a parameter of hundreds of GIGabytes or even a few terabytes. If it is executed on an accelerator (device), the number of accelerators required is huge, and the training cost is expensive. On the other hand, if you use accelerator computing, the training acceleration obtained is limited, and it will also trigger cross-server traffic, and the end-to-end training efficiency will not be very high.
+Pipeline parallel and operator-level parallel are suitable for scenarios where there are a large number of model operators and parameters are distributed evenly across the operators. If there are fewer model operators and parameters are concentrated in a small number of operators, a different strategy is required. Wide & Deep is an example of this, as shown in the image below. The Embedding table in Wide & Deep can be trained as a parameter of hundreds of GIGabytes or even a few terabytes. If it is executed on an accelerator (device), the number of accelerators required is huge, and the training cost is expensive. On the other hand, if you use accelerator computing, the training acceleration obtained is limited, and it will also trigger cross-server traffic, and the end-to-end training efficiency will not be very high.
@@ -69,6 +69,7 @@ The dataset is loaded and the data is parallelized consistently with the followi
import os
import mindspore as ms
import mindspore.dataset as ds
+from mindspore.communication import get_rank, get_group_size
ms.set_seed(1)
diff --git a/tutorials/source_zh_cn/beginner/accelerate_with_static_graph.ipynb b/tutorials/source_zh_cn/beginner/accelerate_with_static_graph.ipynb
index 4f80abe32f06a91e830e7653ce5c9de0c907b58c..44f1e78f73008e7c6c3ad0ece6635185dfebbef2 100644
--- a/tutorials/source_zh_cn/beginner/accelerate_with_static_graph.ipynb
+++ b/tutorials/source_zh_cn/beginner/accelerate_with_static_graph.ipynb
@@ -171,7 +171,7 @@
"\n",
"## 静态图模式开启方式\n",
"\n",
- "通常情况下,由于动态图的灵活性,我们会选择使用PyNative模式来进行自由的神经网络构建,以实现模型的创新和优化。但是当需要进行性能加速时,可以对神经网络部分或整体进行加速。MindSpore提供了两种切换为图模式的方式:基于装饰器的开启方式以及基于全局context的开启方式。\n",
+ "通常情况下,由于动态图的灵活性,我们会选择使用PyNative模式来进行自由的神经网络构建,以实现模型的创新和优化。但是当需要进行性能加速时,可以对神经网络部分或整体进行加速。MindSpore提供了两种切换为静态图模式的方式:基于装饰器的开启方式以及基于全局context的开启方式。\n",
"\n",
"### 基于装饰器的开启方式\n",
"\n",
diff --git a/tutorials/source_zh_cn/conf.py b/tutorials/source_zh_cn/conf.py
index d79551a49489cfb1cada667671e5a13e466a5567..fa082f61b9ee44773ea8cfe082e3d8007825ba4a 100644
--- a/tutorials/source_zh_cn/conf.py
+++ b/tutorials/source_zh_cn/conf.py
@@ -48,7 +48,7 @@ html_title = author + ' ' + release + ' ' + project
# ones.
myst_enable_extensions = ["dollarmath", "amsmath"]
-
+# 允许生成几级及以上的锚点
myst_heading_anchors = 5
extensions = [
'myst_parser',
diff --git a/tutorials/source_zh_cn/custom_program/op_custom.rst b/tutorials/source_zh_cn/custom_program/op_custom.rst
index 13f5a13fff31a0fb9e343a7f8e147281b8b95bb6..f30ac98b4cd9d8ab72137ff559e489bae5c9e0e0 100644
--- a/tutorials/source_zh_cn/custom_program/op_custom.rst
+++ b/tutorials/source_zh_cn/custom_program/op_custom.rst
@@ -16,6 +16,7 @@
operation/op_customopbuilder
operation/cpp_api_for_custom_ops
operation/op_customopbuilder_atb
+ operation/op_customopbuilder_asdsip
当开发网络遇到内置算子不足以满足需求时,你可以利用MindSpore的自定义算子功能接入你的算子。当前MindSpore提供了两种方式接入自定义算子,分别是 `基于Custom原语接入 `_ 和 `基于CustomOpBuilder接入 `_ 。
diff --git a/tutorials/source_zh_cn/custom_program/operation/cpp_api_for_custom_ops.md b/tutorials/source_zh_cn/custom_program/operation/cpp_api_for_custom_ops.md
index abca0f67105a0ab79d4cf5e4a076b8b5ef32b008..4c77055275a284309526c474f570341c6ff43c2f 100644
--- a/tutorials/source_zh_cn/custom_program/operation/cpp_api_for_custom_ops.md
+++ b/tutorials/source_zh_cn/custom_program/operation/cpp_api_for_custom_ops.md
@@ -517,3 +517,50 @@ void RunAtbOp(const std::string &op_name, const ParamType ¶m, const std::vec
- `param`:初始化 ATB 算子所需的参数。
- `inputs`:算子的输入 Tensor 列表。
- `outputs`:算子的输出 Tensor 列表。
+
+### class AsdSipFFTOpRunner
+
+用于执行 Ascend Sip Boost (ASDSIP) 算子的运行器类,定义在[asdsip_common.h](https://gitee.com/mindspore/mindspore/blob/master/mindspore/ccsrc/ms_extension/ascend/asdsip/asdsip_common.h)头文件中。
+
+此类继承自 `PyboostRunner`,并封装了 ASDSIP FFT 算子的调用流程,包括初始化和运行 ASDSIP FFT 算子、管理输入输出 Tensor、内存分配及内核调度。
+
+可以查看教程 [CustomOpBuilder通过AsdSipFFTOpRunner接入ASDSIP FFT算子](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/op_customopbuilder_asdsip.html) 获取使用方法。
+
+#### 构造函数
+
+- **AsdSipFFTOpRunner**
+
+ ```cpp
+ explicit AsdSipFFTOpRunner(std::string op_name) : PyboostRunner(op_name) {}
+ ```
+
+ 继承自 `PyboostRunner` 的构造函数。
+
+#### 公共方法
+
+- **Init(const FFTParam ¶m);**
+
+ ```cpp
+ void Init(const FFTParam ¶m);
+ ```
+
+ - **描述**: 【API】 使用给定参数初始化 ASDSIP FFT 算子。此方法通过 `AsdFftCreate` 创建对应算子的 `asdFftHandle` 实例,并将其放入缓存中。对于`param`相同的算子,只会创建一份 `asdFftHandle` 实例。
+ - **参数**
+ - `param`:用于配置 ASDSIP FFT 算子的参数。
+
+### function RunAsdSipFFTOp
+
+动态图执行ASDSIP FFT算子的接口,定义在[asdsip_common.h](https://gitee.com/mindspore/mindspore/blob/master/mindspore/ccsrc/ms_extension/ascend/asdsip/asdsip_common.h)头文件中。
+
+```cpp
+inline void RunAsdSipFFTOp(const std::string &op_name, const FFTParam &fft_param, const ms::Tensor &input,
+ const ms::Tensor &output)
+```
+
+【API】 使用提供的参数、输入和输出执行一个 ASDSIP FFT 算子。此函数是对 `AsdSipFFTOpRunner` 的一层封装。
+
+- **参数**
+ - `op_name`:要执行的 ASDSIP FFT 算子名称。
+ - `fft_param`:初始化 ASDSIP FFT 算子所需的参数。
+ - `inputs`:算子的输入 Tensor。
+ - `outputs`:算子的输出 Tensor。
diff --git a/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder.md b/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder.md
index e74bb4b21de413b6814cd3b25ccf34af71e0e472..1a41e5ffa7e3b31a5e559f0095373806bf0758eb 100644
--- a/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder.md
+++ b/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder.md
@@ -215,3 +215,4 @@ print(out)
## 更多场景示例
- [通过AtbOpRunner接入ATB算子](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/op_customopbuilder_atb.html):介绍通过自定义算子快速对接ATB算子的方法。
+- [通过AsdSipFFTOpRunner接入ASDSIP FFT算子](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/op_customopbuilder_asdsip.html):介绍通过自定义算子快速对接ASDSIP FFT算子的方法。
diff --git a/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder_asdsip.md b/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder_asdsip.md
new file mode 100644
index 0000000000000000000000000000000000000000..781f45663409bd3ef614f9d445e0afb0b5bba2c6
--- /dev/null
+++ b/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder_asdsip.md
@@ -0,0 +1,128 @@
+# CustomOpBuilder通过AsdSipFFTOpRunner接入ASDSIP FFT算子
+
+[](https://gitee.com/mindspore/docs/blob/master/tutorials/source_zh_cn/custom_program/operation/op_customopbuilder_asdsip.md)
+
+## 概述
+
+[Ascend Sip Boost (ASDSIP) 算子加速库](https://www.hiascend.com/document/detail/zh/canncommercial/82RC1/acce/SiP/SIP_0000.html) 是基于华为Ascend AI处理器,专门为信号处理领域而设计的算子库。
+
+当用户需要使用ASDSIP加速库的FFT类算子,而MindSpore未提供相应算子接口时,用户可以使用自定义算子的方法快速接入使用。
+
+在 [基于CustomOpBuilder的自定义算子](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/op_customopbuilder.html) 中,MindSpore提供了 `PyboostRunner` 方便用户在动态图接入自定义算子。现在针对ASDSIP算子,MindSpore又额外提供了一套`AsdSipFFTOpRunner`用于把ASDSIP FFT算子的调用流程和动态图多级流水封装到一起。
+
+用户基于 [AsdSipFFTOpRunner类](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/cpp_api_for_custom_ops.html#class-asdsipfftoprunner) 对接ASDSIP FFT算子时,仅需要提供`Param`,并调用`Init`接口初始化(即构造`Operation`),再调用`Run`接口即可执行ASDSIP算子。还可以直接调用 [RunAsdSipFFTOp](https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/cpp_api_for_custom_ops.html#function-launchasdsipfft)函数一键执行(函数内包含了`Init`和`Run`接口的调用)。
+
+本指南以一个`FftC2C`为例,展示ASDSIP FFT算子的接入流程。完整代码请参阅[代码仓库](https://gitee.com/mindspore/mindspore/blob/master/tests/st/graph_kernel/custom/jit_test_files/asdsip_fftc2c.cpp)。
+
+## 安装ASDSIP加速库
+
+[点这里查看安装教程](https://www.hiascend.com/document/detail/zh/canncommercial/82RC1/acce/SiP/SIP_0001.html)
+
+安装成功之后,需要激活ASDSIP加速库的环境变量:
+
+```sh
+source /usr/local/Ascend/nnal/asdsip/set_env.sh &> /dev/null
+```
+
+## FftC2C算子接入
+
+这里使用`ms::pynative::RunAsdSipFFTOp`接入算子,并通过`ms::pynative::PyboostRunner::Call`调用函数接口:
+
+```cpp
+#include "ms_extension/api.h"
+
+ms::Tensor InferFFTForward(const ms::Tensor &input) {
+ ShapeVector out_tensor_shape(input.shape());
+ return ms::Tensor(input.data_type(), out_tensor_shape);
+}
+
+ms::Tensor npu_fft(const ms::Tensor &input, int64_t n, int64_t batch_size) {
+ ms::pynative::FFTParam param;
+ param.fftXSize = n;
+ param.fftYSize = 0;
+ param.fftType = ms::pynative::asdFftType::ASCEND_FFT_C2C;
+ param.direction = ms::pynative::asdFftDirection::ASCEND_FFT_FORWARD;
+ param.batchSize = batch_size;
+ param.dimType = ms::pynative::asdFft1dDimType::ASCEND_FFT_HORIZONTAL;
+ auto output = InferFFTForward(input);
+ ms::pynative::RunAsdSipFFTOp("asdFftExecC2C", param, input, output);
+ return output;
+}
+
+auto pyboost_npu_fft(const ms::Tensor &input, int64_t n, int64_t batch_size) {
+ return ms::pynative::PyboostRunner::Call<1>(npu_fft, input, n, batch_size);
+}
+
+PYBIND11_MODULE(MS_EXTENSION_NAME, m) {
+ m.def("fft", &pyboost_npu_fft, "FFT C2C", pybind11::arg("input"), pybind11::arg("n"),
+ pybind11::arg("batch_size"));
+}
+```
+
+### 1. 推导算子的输出信息
+
+```cpp
+ms::Tensor InferFFT1DForward(const ms::Tensor &input) {
+ ShapeVector out_tensor_shape(input.shape());
+ return ms::Tensor(input.data_type(), out_tensor_shape);
+}
+```
+
+对于`FftC2C`算子,输出张量的数据类型和输入的一样。推导出输出形状之后,通过`ms::Tensor`构造函数构造一个空的张量。
+
+### 2. 创建并设置算子属性结构体
+
+```cpp
+ms::pynative::FFTParam param;
+param.fftXSize = n;
+param.fftYSize = 0;
+param.fftType = ms::pynative::asdFftType::ASCEND_FFT_C2C;
+param.direction = ms::pynative::asdFftDirection::ASCEND_FFT_FORWARD;
+param.batchSize = batch_size;
+param.dimType = ms::pynative::asdFft1dDimType::ASCEND_FFT_HORIZONTAL;
+```
+
+### 3. 调用RunAtbOp接口执行算子
+
+```cpp
+ms::pynative::PyboostRunner::Call<1>(npu_fft, input, n, batch_size);
+```
+
+这是一个模板接口,其等效于:
+
+```cpp
+auto runner = std::make_shared("FFTExecC2C");
+runner->Init(fft_param);
+runner->Run({input}, {output});
+```
+
+传入算子名、属性、输入张量、输出张量几个信息,即可调用相应的ASDSIP算子。此接口支持了动态图的多级流水执行流程。
+
+### 4. 通过pybind11将C++函数绑定一个Python函数
+
+```cpp
+auto pyboost_npu_fft(const ms::Tensor &input, int64_t n, int64_t batch_size) {
+ return ms::pynative::PyboostRunner::Call<1>(npu_fft, input, n, batch_size);
+}
+
+PYBIND11_MODULE(MS_EXTENSION_NAME, m) {
+ m.def("fft", &pyboost_npu_fft, "FFT C2C", pybind11::arg("input"), pybind11::arg("n"),
+ pybind11::arg("batch_size"));
+}
+```
+
+### 5. 使用CustomOpBuilder编译自定义算子
+
+将上述C++代码保存成文件`asdsip_fftc2c.cpp`,然后使用Python接口`CustomOpBuilder`编译。
+
+```python
+input_np = np.random.rand(2, 16)
+real_np = input_np.astype(np.float32)
+imag_np = input_np.astype(np.float32)
+complex_np = real_np + 1j * imag_np
+my_ops = CustomOpBuilder("asdsip_fftc2c", "jit_test_files/asdsip_fftc2c.cpp", enable_asdsip=True).load()
+output_tensor = my_ops.fft(input_tensor, 16, 2)
+print(output_tensor)
+```
+
+这里向`CustomOpBuilder`传入了`enable_asdsip=True`的参数,MindSpore会自动添加与ASDSIP加速库有关的编译和链接选项。用户需保证正确执行了ASDSIP库的`set_env.sh`脚本,环境中已配置`ASDSIP_HOME_PATH`环境变量。
diff --git a/tutorials/source_zh_cn/debug/dump.md b/tutorials/source_zh_cn/debug/dump.md
index 444a145e262989c41b3d6a681b3c581062725eb6..1077c97419d2c7735e3de20738a275e61758102d 100644
--- a/tutorials/source_zh_cn/debug/dump.md
+++ b/tutorials/source_zh_cn/debug/dump.md
@@ -155,7 +155,7 @@ MindSpore在不同后端下支持的Dump功能如下表所示:
- "negative inf count": 表示Tensor中`-Inf`元素的个数;
- "positive inf count": 表示Tensor中`+Inf`元素的个数;
- "zero count": 表示Tensor中元素`0`的个数;
- - "md5": 表示Tensor的MD5值;
+ - "hash": 表示Tensor的哈希特征值,默认使用SHA1算法,也可写作"hash:sha1",该算法计算更快,推荐优先使用;"hash:md5"表示Tensor的MD5值,与先前版本的"md5"配置项结果相同。
- "l2norm": 表示Tensor的L2Norm值,支持在device统计和在host统计。
以上除了标记了支持device统计的,其他都仅支持在host统计。
@@ -168,7 +168,7 @@ MindSpore在不同后端下支持的Dump功能如下表所示:
- `enable`:设置成true,表示开启同步Dump;设置成false时,采用异步Dump。不设置该字段时默认值为false,开启异步Dump。两者的区别是异步Dump对原本代码执行过程的影响更小。
- `trans_flag`:开启格式转换,将设备上的数据格式转换成NCHW格式。若为`true`,则数据会以Host侧的4D格式(NCHW)格式保存;若为`false`,则保留Device侧的数据格式。该配置参数在CPU上无效,因为CPU上没有format转换。默认值:true。
- - `stat_calc_mode`:选择统计信息计算后端,可选"host"和"device"。选择"device"后可以使能device计算统计信息,当前只在Ascend生效,只支持`min/max/avg/l2norm`统计量。在op_debug_mode设置为3时,仅支持将`stat_calc_mode`设置为"host"。
+ - `stat_calc_mode`:选择统计信息计算后端,可选"host"和"device"。选择"device"后可以使能device计算统计信息,当前只在Ascend生效,只支持`min/max/avg/l2norm`统计量。在op_debug_mode设置为3时,仅支持将`stat_calc_mode`设置为"host"。默认值:"host"。
- `device_stat_precision_mode`(可选):device统计信息精度模式,可选"high"和"low"。选择"high"时,`avg/l2norm`统计量使用float32进行计算,会增加device内存占用,精度更高;为"low"时使用与原始数据相同的类型进行计算,device内存占用较少,但在处理较大数值时可能会导致统计量溢出。默认值为"high"。
- `sample_mode`(可选):设置成0,表示不开启切片dump功能;设置成1时,在图编译后端为ms_backend的情况下开启切片dump功能。仅在op_debug_mode设置为0时生效,其他场景不会开启切片dump功能。
- `sample_num`(可选):用于控制切片dump中切片的大小。默认值为100。
diff --git a/tutorials/source_zh_cn/index.rst b/tutorials/source_zh_cn/index.rst
index 4fe672c75125f04f3e7a0318d58b8e6f981dcd55..0fe6549850dad434913ce6b84faeb9e88efcee20 100644
--- a/tutorials/source_zh_cn/index.rst
+++ b/tutorials/source_zh_cn/index.rst
@@ -148,7 +148,7 @@ MindSpore教程
-
+
数据处理
@@ -234,7 +234,7 @@ MindSpore教程
-
+
推理
diff --git a/tutorials/source_zh_cn/model_infer/ms_infer/ms_infer_model_infer.rst b/tutorials/source_zh_cn/model_infer/ms_infer/ms_infer_model_infer.rst
index cca47ae04ffb1a0c8c4fe8ac7a13bdb1fa6a52c4..edad80d5899e999f72211d38595267a042ef9a22 100644
--- a/tutorials/source_zh_cn/model_infer/ms_infer/ms_infer_model_infer.rst
+++ b/tutorials/source_zh_cn/model_infer/ms_infer/ms_infer_model_infer.rst
@@ -96,7 +96,7 @@ MindSpore大语言模型为了能够实现最优的性价比,针对大语言
- **Flash Attention**:Attention计算中会存在两个大矩阵相乘(4K大小),实际计算会将大矩阵分解为多个芯片能够计算的小矩阵单元进行计算,由于芯片的最小级的缓存大小限制,需要不断地将待计算数据在缓存和主存间搬入搬出,导致计算资源实际无法充分利用,因此当前主流芯片下,Attention计算实际上是带宽bound。Flash Attention技术将原本Attention进行分块,使得每一块计算都能够在芯片上独立计算完成,避免了在计算Key和Value时多次数据的搬入和搬出,从而提升Attention计算性能,具体可以参考 `Flash Attention
`_。
- - **Page Attention显存优化**:标准的Flash Attention每次会读取和保存整个输入的Key和Value数据,这种方式虽然比较简单,但是会造成较多的资源浪费,如“中国的首都”和“中国的国旗”,都有共同的“中国的”作为公共前缀,其Attention对应的Key和Value值实际上是一样的,标准Flash Attention就需要存两份Key和Value,导致显存浪费。Page Attention基于Linux操作系统页表原理对KVCache进行优化,按照特定大小的块来存储Key和Value的数据,将上面例子中的Key和Value存储为“中国”、“的”、“首都”、“国旗”一共四份Key和Value数据,相比原来的六份数据,有效地节省了显存资源。在服务化的场景下,更多空闲显存可以让模型推理的batch更大,从而获得更高的吞吐量,具体可以参考 `Page Attention `_。
+ - **Paged Attention**:标准的Flash Attention每次会读取和保存整个输入的Key和Value数据,这种方式虽然比较简单,但是会造成较多的资源浪费,当一个batch中多个请求序列长度不一致时,Flash Attention需要key和value用最长的序列的显存,如“中国的首都是北京“和“中国的国旗是五星红旗”,假设分词按字分词,则需要10 * 2 = 20个KVCache显存单元。Paged Attention基于Linux操作系统页表原理对KVCache进行优化,按照特定大小的块来存储Key和Value的数据,如块大小为2时,可以按照块使用KVCache,只需要4 * 2 + 5 * 2 = 18个KVCache的显存单元,由于Paged Attention离散的特性,也可以结合Prefix Cache这类技术进一步节省“中国的”所占用的显存,最终只需要3 * 2 + 5 * 2 = 16个KVCache单元。在服务化的场景下,更多空闲显存可以让模型推理的batch更大,从而获得更高的吞吐量,具体可以参考 `Page Attention `_。
- **模型量化**:MindSpore大语言模型推理支持通过量化技术减小模型体积,提供了A16W8、A16W4、A8W8量化以及KVCache量化等技术,减少模型资源占用,提升推理吞吐量。
diff --git a/tutorials/source_zh_cn/parallel/comm_fusion.md b/tutorials/source_zh_cn/parallel/comm_fusion.md
index f5bd3c2bfc9d3d36656c7501a588402ea9d461b0..dca3d1344eb452f5cde67bd1ca9753dc9ecd5b8f 100644
--- a/tutorials/source_zh_cn/parallel/comm_fusion.md
+++ b/tutorials/source_zh_cn/parallel/comm_fusion.md
@@ -4,7 +4,7 @@
## 简介
-在分布式并行训练场景下训练大规模参数量的模型(如GPT-3, Pangu-$\alpha$),跨设备甚至跨节点的数据传输是制约扩展性以及算力利用率的瓶颈[1]。通信融合是一种提升网络资源利用率、加速数据传输效率的重要方法,其将相同源节点和目的节点的通信算子打包同时执行,以避免多个单算子执行带来的额外开销。
+在分布式并行训练场景下训练大规模参数量的模型(如GPT-3、Pangu-$\alpha$),跨设备甚至跨节点的数据传输是制约扩展性以及算力利用率的瓶颈[1]。通信融合是一种提升网络资源利用率、加速数据传输效率的重要方法,其将相同源节点和目的节点的通信算子打包同时执行,以避免多个单算子执行带来的额外开销。
MindSpore支持对分布式训练中三种常用通信算子([AllReduce](https://www.mindspore.cn/docs/zh-CN/master/api_python/ops/mindspore.ops.AllReduce.html)、[AllGather](https://www.mindspore.cn/docs/zh-CN/master/api_python/ops/mindspore.ops.AllGather.html)、[ReduceScatter](https://www.mindspore.cn/docs/zh-CN/master/api_python/ops/mindspore.ops.ReduceScatter.html))的融合,并提供简洁易用的接口方便用户自行配置。在长稳训练任务支撑中,通信融合特性发挥了重要作用。
@@ -54,7 +54,7 @@ MindSpore提供两种接口来使能通信融合,下面分别进行介绍:
2. 利用`Cell`提供的接口
- 无论在哪种并行模式场景下,用户都可以通过[Cell.set_comm_fusion](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Cell.html#mindspore.nn.Cell.set_comm_fusion)接口为模型某layer的参数设置index,MindSpore将融合相同index的参数所对应的通信算子。
+ 无论在哪种并行模式场景下,用户都可以通过[Cell.set_comm_fusion](https://www.mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.Cell.html#mindspore.nn.Cell.set_comm_fusion)接口为模型某个layer的参数设置index,MindSpore将融合相同index的参数所对应的通信算子。
## 操作实践
@@ -91,7 +91,7 @@ net.comm_fusion(config={"allreduce": {"mode": "auto", "config": None}})
init()
```
-若将所有的同类通信算子融合成一个算子,在当前训练迭代中,传输需要等待计算完全结束后才能执行,这样会造成设备的等待。
+若将所有的同类通信算子融合成一个算子,在当前训练迭代中,需要等待计算完全结束后才能执行传输,这样会造成设备的等待。
为了避免上述问题,可以将网络参数进行分组融合:在下一组参数进行的计算的同时,进行上组参数的通信,使得计算和通信能够互相隐藏,可以通过限定fusion buffer的大小,或者index分区的方法进行分组融合。
diff --git a/tutorials/source_zh_cn/parallel/dataset_slice.md b/tutorials/source_zh_cn/parallel/dataset_slice.md
index fcedd8e4146913739ddbfc66e6db17528ae6263f..709c7135dd3d32135f26e3e58282fba5bb670b25 100644
--- a/tutorials/source_zh_cn/parallel/dataset_slice.md
+++ b/tutorials/source_zh_cn/parallel/dataset_slice.md
@@ -4,7 +4,7 @@
## 简介
-在进行分布式训练时,以图片数据为例,当单张图片的大小过大时,如遥感卫星等大幅面图片,当单张图片过大时,需要对图片进行切分,每张卡读取一部分图片,进行分布式训练。处理数据集切分的场景,需要配合模型并行一起才能达到预期的降低显存的效果,因此,基于自动并行提供了该项功能。本教程使用的样例不是大幅面的网络,仅作示例。真实应用到大幅面的网络时,往往需要详细设计并行策略。
+在进行分布式训练时,以图片数据为例,当单张图片的大小过大时,如遥感卫星等大幅面图片,需要对图片进行切分,每张卡读取一部分图片,进行分布式训练。处理数据集切分的场景,需要配合模型并行一起才能达到预期的降低显存的效果,因此,基于自动并行提供了该项功能。本教程使用的样例不是大幅面的网络,仅作示例。真实应用到大幅面的网络时,往往需要详细设计并行策略。
> 数据集切分在数据并行模式下不涉及。
diff --git a/tutorials/source_zh_cn/parallel/high_dimension_tensor_parallel.md b/tutorials/source_zh_cn/parallel/high_dimension_tensor_parallel.md
index 104c534b22c1fc49c05ac3b98889b46f42e6265a..3781617b1ddd6b3eb5a4281d8b2670a5350b1f69 100644
--- a/tutorials/source_zh_cn/parallel/high_dimension_tensor_parallel.md
+++ b/tutorials/source_zh_cn/parallel/high_dimension_tensor_parallel.md
@@ -6,11 +6,11 @@
大模型训练中,模型并行能够有效减少内存负荷,但其引入的通信是一个显著的性能瓶颈。因此需要优化整网模型切分策略以期引入最小的通信量。
-张量并行(Tensor Parallel,简称TP)训练是将一个张量沿特定维度分成 `N` 块,每个设备只持有整个张量的 `1/N`,进行MatMul/BatchMatMul等算子计算,并引入额外通信保证最终结果正确。而高维张量并行则允许灵活控制对张量的切分次数和切分轴,支持1D、2D、3D切分。2D/3D切分相对与1D切分,在合适的切分策略下,通信量随着TP设备数增长更慢,在TP设备数较大时有着更低的额外通信量,达到提高训练速度的目的。
+张量并行(Tensor Parallel,简称TP)训练是将一个张量沿特定维度分成 `N` 块,每个设备只持有整个张量的 `1/N`,进行MatMul/BatchMatMul等算子计算,并引入额外通信保证最终结果正确。而高维张量并行则允许灵活控制对张量的切分次数和切分轴,支持1D、2D、3D切分。2D/3D切分相对于1D切分,在合适的切分策略下,通信量随着TP设备数增长更慢,在TP设备数较大时有着更低的额外通信量,达到提高训练速度的目的。
> 本特性支持的硬件平台为Ascend,需要在Graph模式、半自动并行下运行。
-使用场景:在半自动模式下,网络中存在张量并行,且训练卡数较多时(一般不少于8卡)时,对MatMul/BatchMatMul进行2D/3D张量并行策略配置,并适配上下游算子的切分策略,可获得训练性能提升。
+使用场景:在半自动模式下,网络中存在张量并行,且训练卡数较多时(一般不少于8卡),对MatMul/BatchMatMul进行2D/3D张量并行策略配置,并适配上下游算子的切分策略,可获得训练性能提升。
### 原理
diff --git a/tutorials/source_zh_cn/parallel/host_device_training.md b/tutorials/source_zh_cn/parallel/host_device_training.md
index 63386c8a0885c7a820439be8d7aa9ff2ab2574cb..96207571219cd7771f9b5dcec357eafe745bab43 100644
--- a/tutorials/source_zh_cn/parallel/host_device_training.md
+++ b/tutorials/source_zh_cn/parallel/host_device_training.md
@@ -10,13 +10,13 @@
### 基本原理
-流水线并行和算子级并行适用于模型的算子数量较大,同时参数较均匀的分布在各个算子中。如果模型中的算子数量较少,同时参数只集中在几个算子中呢?Wide&Deep就是这样的例子,如下图所示。Wide&Deep中的Embedding table作为需训练的参数可达几百GB甚至几TB,若放在加速器(device)上执行,那么所需的加速器数量巨大,训练费用昂贵。另一方面,若使用加速器计算,其获得的训练加速有限,同时会引发跨服务器的通信量,端到端的训练效率不会很高。
+流水线并行和算子级并行适用于模型算子数量较多,且参数较均匀地分布在各算子中的场景。若模型算子较少而参数集中在少数算子中,则需要采用不同策略。Wide & Deep 是典型例子,如下图所示。Wide&Deep中的Embedding table作为需训练的参数可达几百GB甚至几TB,若放在加速器(device)上执行,那么所需的加速器数量巨大,训练费用昂贵。另一方面,若使用加速器计算,其获得的训练加速有限,同时会引发跨服务器的通信量,端到端的训练效率不会很高。

*图:Wide&Deep模型的部分结构*
-仔细分析Wide&Deep模型的特殊结构后可得:Embedding table虽然参数量巨大,但其参与的计算量很少,可以将Embedding table和其对应的算子EmbeddingLookup算子放置在Host端计算,其余算子放置在加速器端。这样做能够同时发挥Host端内存量大、加速器端计算快的特性,同时利用了同一台服务器的Host到加速器高带宽的特性。下图展示了Wide&Deep异构切分的方式:
+仔细分析Wide&Deep模型的特殊结构后可得:Embedding table虽然参数量巨大,但其参与的计算量很少,可以将Embedding table和其对应的EmbeddingLookup算子放置在Host端计算,其余算子放置在加速器端。这样做能够同时发挥Host端内存量大、加速器端计算快的特性,同时利用了同一台服务器的Host到加速器高带宽的特性。下图展示了Wide&Deep异构切分的方式:

@@ -69,6 +69,7 @@ init()
import os
import mindspore as ms
import mindspore.dataset as ds
+from mindspore.communication import get_rank, get_group_size
ms.set_seed(1)
@@ -93,7 +94,7 @@ data_set = create_dataset(32)
### 网络定义
-网络定义与单卡网络区别在于,配置[ops.Add()](https://www.mindspore.cn/docs/en/master/api_python/ops/mindspore.ops.Add.html)算子在主机端运行,代码如下:
+网络定义与单卡网络区别在于,配置[ops.Add()](https://www.mindspore.cn/docs/zh-CN/master/api_python/ops/mindspore.ops.Add.html)算子在主机端运行,代码如下:
```python
import mindspore as ms
@@ -180,7 +181,7 @@ for epoch in range(5):
bash run.sh
```
-训练完后,关于Loss部分结果保存在`log_output/worker_*.log`中,示例如下:
+训练完成后,关于Loss部分结果保存在`log_output/worker_*.log`中,示例如下:
```text
epoch: 0, step: 0, loss is 2.302936
diff --git a/tutorials/source_zh_cn/parallel/msrun_launcher.md b/tutorials/source_zh_cn/parallel/msrun_launcher.md
index c0e48a22916c6e1a57106540fb8e217f822a43cd..56a8e1fa7a169417307035d7883905e6e554dbc7 100644
--- a/tutorials/source_zh_cn/parallel/msrun_launcher.md
+++ b/tutorials/source_zh_cn/parallel/msrun_launcher.md
@@ -4,7 +4,7 @@
## 概述
-`msrun`是[动态组网](https://www.mindspore.cn/tutorials/zh-CN/master/parallel/dynamic_cluster.html)启动方式的封装,用户可使用`msrun`,以单个命令行指令的方式在各节点拉起多进程分布式任务,并且无需手动设置[动态组网环境变量](https://www.mindspore.cn/tutorials/zh-CN/master/parallel/dynamic_cluster.html)。`msrun`同时支持`Ascend`,`GPU`和`CPU`后端。与`动态组网`启动方式一样,`msrun`无需依赖第三方库以及配置文件。
+`msrun`是[动态组网](https://www.mindspore.cn/tutorials/zh-CN/master/parallel/dynamic_cluster.html)启动方式的封装,用户可使用`msrun`,以单个命令行指令的方式在各节点拉起多进程分布式任务,并且无需手动设置[动态组网环境变量](https://www.mindspore.cn/tutorials/zh-CN/master/parallel/dynamic_cluster.html)。`msrun`同时支持`Ascend`、`GPU`和`CPU`后端。与`动态组网`启动方式一样,`msrun`无需依赖第三方库以及配置文件。
> - `msrun`在用户安装MindSpore后即可使用,可使用指令`msrun --help`查看支持参数。
> - `msrun`支持`图模式`以及`PyNative模式`。
diff --git a/tutorials/source_zh_cn/parallel/optimize_technique.rst b/tutorials/source_zh_cn/parallel/optimize_technique.rst
index 4a4df80d3f93bd596f480bbd8ebce011244be8a3..2a1bfe268eab6dfcf457612ea346e4136e2a91c5 100644
--- a/tutorials/source_zh_cn/parallel/optimize_technique.rst
+++ b/tutorials/source_zh_cn/parallel/optimize_technique.rst
@@ -21,7 +21,7 @@
考虑到实际并行训练中,可能会对训练性能、吞吐量或规模有要求,可以从三个方面考虑优化:并行策略优化、内存优化和通信优化
-- 并行策略优化:并行策略优化主要包括并行策略的选择、算子级并行下的切分技巧以及多副本技巧。
+- 并行策略优化:主要包括并行策略的选择、算子级并行下的切分技巧以及多副本技巧。
- `策略选择 `_:根据模型规模和数据量大小,可以选择不同的并行策略,以提高训练效率和资源利用率。
- `切分技巧 `_:切分技巧是指通过手动配置某些关键算子的切分策略,减少张量重排布来提升训练效率。
diff --git a/tutorials/source_zh_cn/parallel/overview.md b/tutorials/source_zh_cn/parallel/overview.md
index 3da1bc241819a4971bf00d48d8899053f28daf8f..b5a157c5814ae8706ccca7f7306f75e6771dab02 100644
--- a/tutorials/source_zh_cn/parallel/overview.md
+++ b/tutorials/source_zh_cn/parallel/overview.md
@@ -39,7 +39,7 @@ MindSpore提供两种粒度的算子级并行能力:算子级并行和高阶
## 流水线并行
-近年来,神经网络的规模几乎是呈指数型增长。受单卡内存的限制,训练这些大模型用到的设备数量也在不断增加。受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按阶段(Stage)进行切分,每个Stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。MindSpore能够根据用户的配置,将单机模型自动地转换成流水线并行模式去执行。
+近年来,神经网络的规模几乎呈指数型增长。受单卡内存的限制,训练这些大模型用到的设备数量也在不断增加。受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按阶段(Stage)进行切分,每个Stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。MindSpore能够根据用户的配置,将单机模型自动地转换成流水线并行模式去执行。
详细可参考[流水线并行](https://www.mindspore.cn/tutorials/zh-CN/master/parallel/pipeline_parallel.html)章节。
diff --git a/tutorials/source_zh_cn/parallel/pipeline_parallel.md b/tutorials/source_zh_cn/parallel/pipeline_parallel.md
index e38b87ae28d475f347e6b69f21f734f5b4fe9c04..3a8eaa4165b3d6fb8165419489eef6c4860e7ae3 100644
--- a/tutorials/source_zh_cn/parallel/pipeline_parallel.md
+++ b/tutorials/source_zh_cn/parallel/pipeline_parallel.md
@@ -4,7 +4,7 @@
## 简介
-近年来,神经网络的规模几乎是呈指数型增长。受单卡内存的限制,训练这些大模型用到的设备数量也在不断增加。受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按阶段(Stage)进行切分,每个Stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。MindSpore能够根据用户的配置,将单机模型自动地转换成流水线并行模式去执行。
+近年来,神经网络的规模几乎呈指数型增长。受单卡内存的限制,训练这些大模型用到的设备数量也在不断增加。受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按阶段(Stage)进行切分,每个Stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。MindSpore能够根据用户的配置,将单机模型自动转换成流水线并行模式去执行。
## 训练操作实践
diff --git a/tutorials/source_zh_cn/parallel/split_technique.md b/tutorials/source_zh_cn/parallel/split_technique.md
index a6f1ef019c1fa2938acaecbdf7b4e323b7648155..9a23e6a058ef4a40a32b2e557dc27118921853cd 100644
--- a/tutorials/source_zh_cn/parallel/split_technique.md
+++ b/tutorials/source_zh_cn/parallel/split_technique.md
@@ -118,7 +118,7 @@ class CoreAttention(nn.Cell):
-再看[FlashAttention](https://gitee.com/mindspore/mindformers/blob/master/mindformers/modules/flash_attention.py)的例子:
+再看[FlashAttention](https://gitee.com/mindspore/mindformers/blob/master/mindformers/modules/flash_attention.py)的例子:
|
@@ -193,4 +193,4 @@ class LlamaForCausalLM(LlamaPretrainedModel):
|
-**用户无法确认是否需要对算子配置策略时,可以不配置,由算法传播找寻最优策略,但是可能无法获得最佳的并行效果;若用户能够确认该算子需要配置什么策略,则可以进行配置帮助算法获得预期效果。**
+**用户无法确认是否需要对算子配置策略时,可以不配置,由算法传播找寻最优策略,但是可能无法获得最佳的并行效果;若用户能够确认该算子需要配置什么策略,则可以进行配置,帮助算法获得预期效果。**